

本文研究了在计算资源有限的条件下缩小对比语言-图像预训练(CLIP)模型的性能。我们从三个维度探讨CLIP模型:数据、架构和训练策略。关于数据,我们展示了高质量训练数据的重要性,并证明较小的高质量数据集可以胜过较大的低质量数据集。我们还研究了模型性能如何随数据集大小变化,发现较小的ViT模型更适合较小的数据集,而较大的模型在有固定计算资源的较大数据集上表现更佳。此外,我们提供了在CLIP训练中选择基于CNN的架构还是基于ViT的架构的指导。我们比较了四种CLIP训练策略——SLIP、FLIP、CLIP以及CLIP+数据增强,并显示训练策略的选择取决于可用的计算资源。我们的分析揭示,CLIP+数据增强能够仅使用一半的训练数据达到与CLIP相当的性能。这项工作提供了如何有效训练和部署CLIP模型的实用见解,使其在各种应用中更易于访问和负担得起。
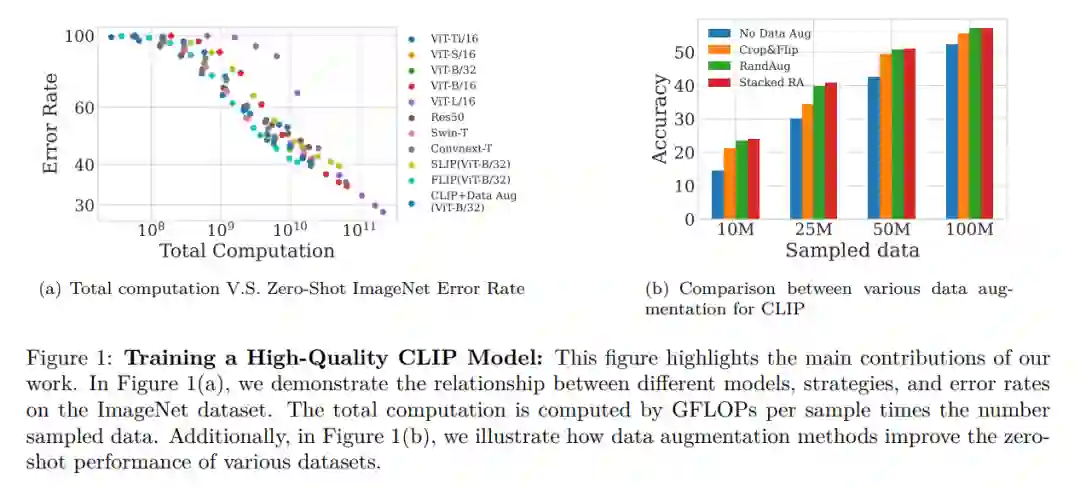
近年来,图像和语言表征学习领域的兴趣激增(Radford et al., 2021; Jia et al., 2021; Pham et al., 2021; Ramesh et al., 2022),其目标是捕捉视觉和文本信息之间丰富而复杂的相互作用。在这一领域中最有前景的方法之一是对比语言-图像预训练(CLIP)框架,它利用大规模文本和图像数据学习一个统一的表征空间,适用于这两种模式。CLIP在一系列下游任务上取得了最先进的表现,并且已经证明能够很好地泛化到分布外数据(Chen et al., 2019; Jia et al., 2021; Miller et al., 2021; Taori et al., 2020; Nguyen et al., 2022; GontijoLopes et al., 2021)。虽然先前关于扩展对比语言-图像预训练(CLIP)的研究,如 Li et al. (2022); Cherti et al. (2022),主要集中在大计算场景下,我们的工作旨在探索资源限制下的CLIP性能。我们提出了一个全面的研究,从三个方向缩小CLIP的规模:数据、架构和训练策略。具体来说,我们研究了使用不同训练数据大小的效果,比较了不同架构在不同计算预算下的性能,并评估了不同预训练策略的有效性。我们的实验在一个大型图像和语言数据集WebLI上进行(Chen et al., 2022),该数据集包含超过34亿个英语图文对。特别是,我们为大部分实验设置了计算限制,且大部分实验的样本数据量最多为34亿。
我们在不同大小的数据集上训练,以探索在ImageNet变体上的表现是否与在ImageNet上的表现一致。我们还探讨了数据质量的重要性,并证明了一小部分高质量数据可以胜过更大的数据集。我们发现仅使用高质量数据的40%可以获得比使用整个数据集更好的表现,并研究了模型性能随数据集大小增加的变化情况。我们的结果为选择CLIP模型的训练数据提供了指导,这是实际应用中的一个关键问题。
关于架构,我们在不同的数据集大小下比较了多种架构。我们研究了根据数据集大小和计算预算如何选择视觉编码器的大小。我们显示了更大的ViT(Dosovitskiy et al., 2020)并非总是更好的选择。我们还展示了在CLIP训练中选择CNN(He et al., 2016)和ViT架构的重要性。虽然以前的研究表明基于ViT的CLIP性能优于基于CNN的CLIP模型,但我们发现当采样数据量较小时,CNN表现更佳。
最后,我们比较了四个选项:SLIP(Mu et al., 2021)、FLIP(Li et al., 2022)、CLIP和CLIP+数据增强。我们显示SLIP(Mu et al., 2021)并非总是比CLIP和FLIP更优的选择。当训练集大小较小时,SLIP比CLIP表现更好。然而,随着训练数据大小的增加,SLIP的表现与CLIP相似,但需要两倍的计算成本。我们的结果提供了CLIP训练中计算成本与性能之间的权衡的见解,这是实际应用中的一个关键问题。
