

摘要 — 随着人工智能生成内容(AIGC)的快速发展,视频生成已成为其中最具活力和影响力的子领域之一。尤其是视频生成基础模型的进步,催生了对可控视频生成方法日益增长的需求,以更准确地反映用户意图。目前大多数基础模型主要用于文本生成视频(text-to-video),然而,仅依赖文本提示往往难以表达复杂、多模态且细粒度的用户需求。这一局限性使得用户难以通过现有模型实现精确控制的视频生成。为了解决这一问题,近期研究开始探索引入额外的非文本条件——如相机运动、深度图和人体姿态等——以扩展预训练的视频生成模型,从而实现更可控的视频合成。这些方法旨在提升 AIGC 驱动的视频生成系统的灵活性和实际应用能力。 在本综述中,我们系统回顾了可控视频生成的研究进展,涵盖理论基础与前沿方法。我们首先介绍了关键概念以及常用的开源视频生成模型,随后重点讨论了视频扩散模型中的控制机制,分析了不同类型的控制条件如何在去噪过程被集成以引导生成过程。最后,我们按照所采用控制信号的类型,将现有方法分为单一条件生成、多条件生成和通用可控生成三类。完整的可控视频生成文献列表可参见我们整理的资源库:https://github.com/mayuelala/Awesome-Controllable-Video-Generation。 关键词—综述、视频生成模型、可控生成、AIGC
1 引言
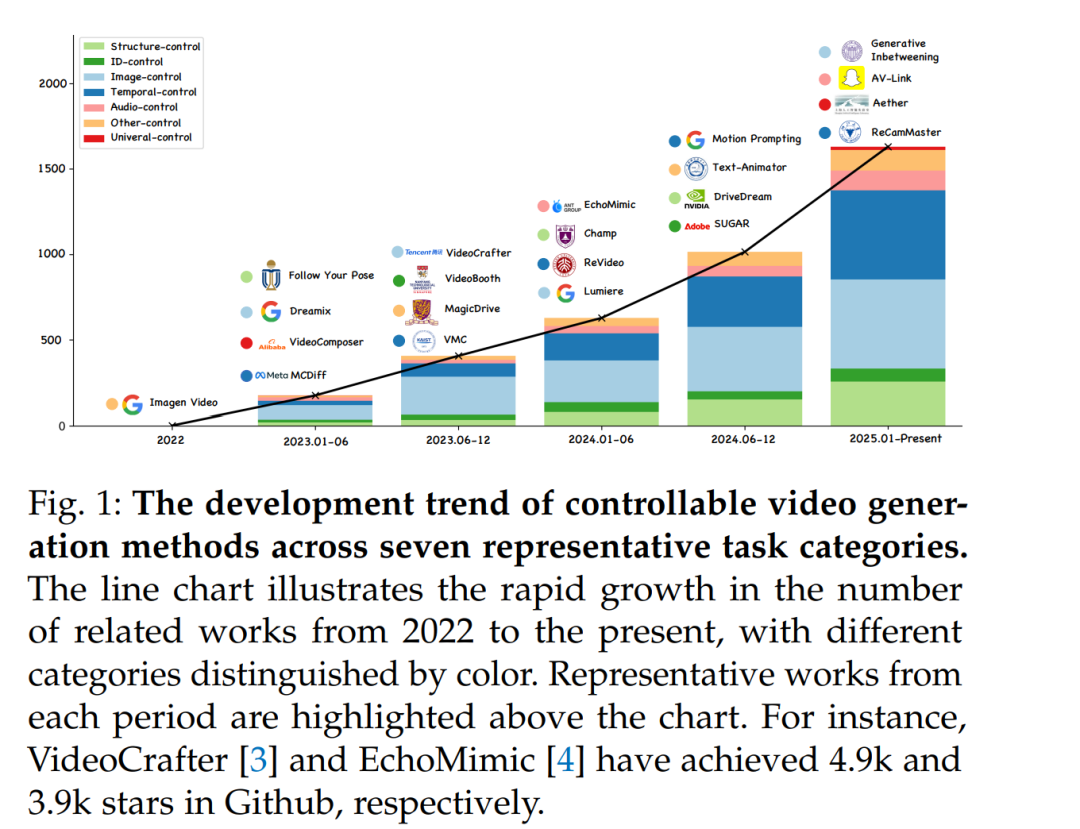
随着人工智能生成内容(AIGC)持续升温,视频生成作为其关键领域之一,正成为研究者和用户高度关注的焦点。现代视频生成方法通常结合最前沿的生成范式(如扩散模型 [8], [9] 或自回归模型 [10]–[13]),并依托大规模数据集 [14]–[16]、庞大的模型参数 [17]–[19] 以及先进的架构设计 [20]。本文将这类方法统称为视频生成基础模型,其推动了生成视频的质量达到前所未有的高度,展现出令人惊叹的创造力。 尽管这些模型具备强大的生成能力,但它们通常依赖仅基于文本的条件输入,这限制了用户对生成内容的控制程度。因此,用户在创作实践中常常难以将自己的创意精准转化为视频输出,降低了这些模型在真实内容创作场景中的实用性。 为了解决上述问题,研究者开始探索引入文本以外的控制信号,以实现更准确和灵活的视频生成引导。例如,让用户能够修改相机运动轨迹,或为视频中的角色指定特定动作,正逐渐成为研究热点。只有当对生成内容实现细粒度的控制时,用户才能真正释放创作潜力,充分发挥视频生成任务的实际价值。 在本综述中,我们聚焦于可控视频生成任务,涵盖其理论基础与实际应用,旨在提供该快速演进领域的全面研究进展概览,并梳理其发展脉络。具体而言,我们首先简要介绍视频生成模型的背景与核心概念,厘清其理论基础,从而帮助理解早期工作的核心原理。随后,我们对已有研究进行详细回顾,突出其创新贡献与方法特征。在此基础上,进一步探讨这些方法在实际场景中的应用,突出其在各类任务中的现实意义与影响力。同时,我们还将深入讨论可控视频生成的局限性与未来发展方向。 在图 1 中,我们绘制了一张趋势图,展示了采用不同条件类型的可控视频生成研究数量随时间的变化。伴随视频基础模型的快速演进,可控视频生成研究也呈现出显著增长。 近期已有综述论文对 AIGC 进行了较为全面的回顾,涵盖了生成对抗网络(GAN)与变分自编码器(VAE)驱动的视频生成 [21], [22]、扩散模型理论与架构 [23]、高效视频扩散模型 [24]、多模态视频合成与理解 [25]、视频编辑 [26]、基础视频扩散模型 [27]–[29] 以及四维生成应用 [30] 等多个方向。尽管这些综述提供了有价值的见解,但许多仅对视频生成模型做了粗略介绍,或更偏重其他模态,因而在可控视频生成方面存在明显空白。此外,已有研究很少系统讨论如深度图、草图、分割图等多种控制信号在视频生成中的整合方式,这使得我们对可控视频生成中条件扩展的潜力和挑战尚缺乏深入理解。 总之,本文的主要贡献包括:
提出结构清晰的可控视频生成方法分类体系,基于输入控制信号将现有方法进行归类,有助于理解已有研究并揭示该领域的核心挑战; * 系统梳理 GAN、VAE、Flow、DM 和 AR 等架构的理论基础,以及构建于其上的最新视频生成模型,帮助读者深入理解其基本原理; * 围绕所提出的分类体系,广泛介绍各种条件生成方法,并强调各类方法的特征与技术创新; * 探讨条件生成在实际视频生成中的应用影响,涵盖多个生成场景,体现其在 AIGC 生态中的日益重要性,同时指出当前技术的关键不足并提出未来潜在的研究方向。
本文结构如下:第 2 节简要回顾各类生成范式;第 3 节介绍代表性的视频生成模型,并构建完整的可控视频生成方法分类体系;第 4 节讨论控制机制,说明如何将新型条件集成至视频生成模型中,并基于分类总结已有方法;第 5 节强调可控视频生成的关键应用场景;最后,第 6 节从技术和实践两个角度讨论当前研究的局限,并提出未来的研究展望。 可控视频生成是一个系统性强且高度复杂的研究领域。目前大多数相关研究主要聚焦于在特定控制下的视频生成,例如姿态引导或主体引导等。根据控制类型的不同,该任务可自然划分为七个子任务,如图 3 所示。为了更深入地理解其内部机制,并从整体上把握该研究方向,本文进一步按照条件类型对其进行细化分类。 该领域的核心挑战在于:如何将各种控制条件注入到预训练的视频生成模型中。这意味着模型不仅要与文本提示对齐,还需协同额外条件,共同驱动生成过程,从而生成具备高质量与高保真度的视频内容。 此外,近期研究还探索了多条件视频生成,即模型在生成过程中同时受到多个输入的引导,例如参考图像、稀疏轨迹和运动笔刷等。这类设定显著提升了生成的复杂度,要求模型能够有效整合和协同多个条件,从而实现更细致和灵活的控制能力。

