深度强化学习(DRL)在各个领域的序列决策任务中取得了显著的成功,但其依赖于黑箱神经网络架构的特点限制了解释性、可信度以及在高风险应用中的部署。可解释深度强化学习(XRL)通过在特征级、状态级、数据集级和模型级的解释技术来解决这些挑战,从而提高透明度。本综述提供了XRL方法的全面回顾,评估了其定性和定量评估框架,并探讨了它们在策略优化、对抗鲁棒性和安全性中的作用。此外,我们还考察了强化学习与大语言模型(LLMs)的结合,特别是通过基于人类反馈的强化学习(RLHF),该方法优化了AI与人类偏好的对齐。最后,我们总结了当前的研究挑战并展望了未来的发展方向,以推进可解释、可靠和负责任的DRL系统的研究进展。
1 引言
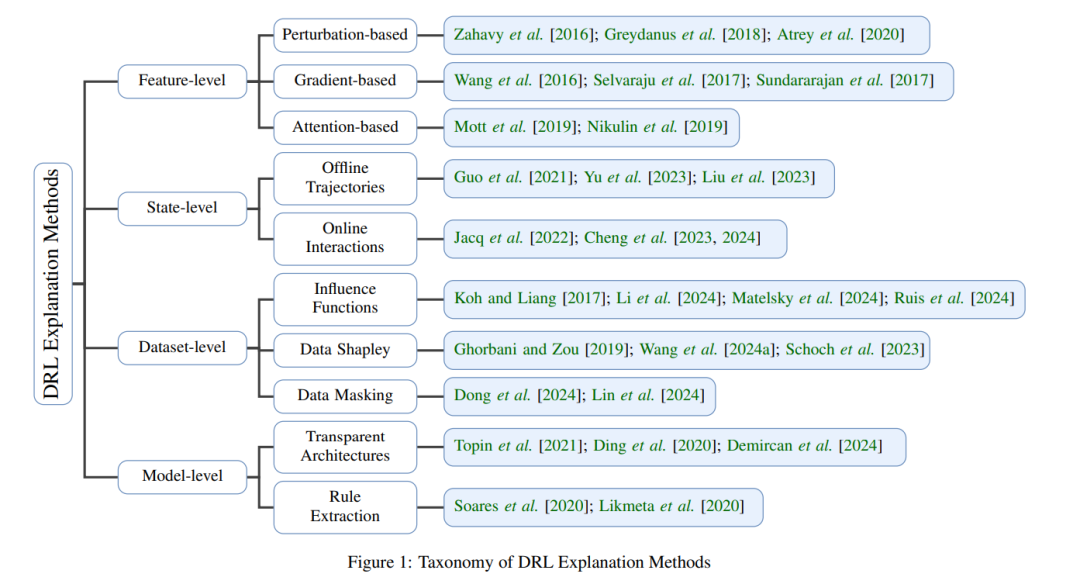
深度强化学习(DRL)作为一种解决复杂序列决策问题的变革性范式,已经取得了显著进展。通过使自主智能体与环境互动、接收奖励反馈,并不断优化策略,DRL在多个领域取得了卓越的成功,包括游戏(如:Atari [Mnih, 2013; Kaiser et al., 2020],围棋 [Silver et al., 2018, 2017],以及星际争霸 II [Vinyals et al., 2019, 2017]),机器人技术 [Kalashnikov et al., 2018],通信网络 [Feriani and Hossain, 2021],以及金融 [Liu et al., 2024]。这些成功凸显了DRL超越传统基于规则系统的能力,尤其是在高维度和动态变化的环境中。尽管取得了这些进展,仍然存在一个根本性挑战:DRL智能体通常依赖于深度神经网络,这些网络作为黑箱模型运行,遮蔽了其决策过程的背后原理。这种不透明性在安全关键和高风险应用中构成了显著障碍,因为在这些领域中,可解释性对于信任、合规性和调试至关重要。DRL中缺乏透明度可能导致不可靠的决策,使其在需要可解释性的领域(如医疗、自动驾驶和金融风险评估)中不适用。 为了解决这些问题,可解释深度强化学习(XRL)领域应运而生,旨在开发能够提高DRL策略可解释性的技术。XRL致力于提供智能体决策过程的洞察,帮助研究人员、实践者和最终用户理解、验证并优化学习到的策略。通过促进更大的透明度,XRL有助于开发更安全、更稳健、以及更符合伦理的AI系统。 此外,强化学习(RL)与大语言模型(LLMs)的日益融合,使得RL成为自然语言处理(NLP)领域的前沿技术。诸如基于人类反馈的强化学习(RLHF)[Bai et al., 2022; Ouyang et al., 2022]等方法已经成为使LLM输出与人类偏好和伦理指南对齐的重要手段。通过将语言生成视为序列决策过程,基于RL的微调使LLM能够优化诸如事实准确性、连贯性和用户满意度等属性,超越了传统的监督学习技术。然而,RL在LLM对齐中的应用进一步加剧了可解释性问题,因为RL更新与神经网络表示之间的复杂交互仍然不完全为人所理解。 本综述提供了关于DRL中可解释性方法的系统性回顾,特别关注其与LLM和人类参与系统的集成。我们首先介绍了强化学习的基本概念,并突出展示了DRL的关键进展。接着,我们对现有的解释方法进行分类和分析,涵盖了特征级、状态级、数据集级和模型级的技术。此外,我们讨论了评估XRL技术的方法,考虑了定性和定量评估标准。最后,我们探讨了XRL在现实应用中的实践,包括策略优化、对抗性攻击缓解以及在现代AI系统中确保可解释性的挑战。通过本综述,我们旨在提供关于XRL当前状态的全面视角,并概述未来的研究方向,以推进可解释且值得信赖的DRL模型的发展。