摘要—文本到图像 (T2I) 扩散模型 (DMs) 因其在图像生成方面的显著进展而受到广泛关注。然而,随着其日益普及,与信任度的关键非功能性属性相关的伦理和社会问题也日益凸显,例如鲁棒性、公平性、安全性、隐私性、事实性和可解释性,这些问题与传统深度学习 (DL) 任务中的类似问题相似。由于 T2I DMs 的独特特性,例如其多模态性,传统的研究深度学习任务信任度的方式往往不足以应对这些问题。鉴于这一挑战,近年来一些新方法被提出,通过伪造、增强、验证与确认以及评估等多种方式来研究 T2I DMs 的信任度。然而,关于这些非功能性属性和方法的深入分析仍然相对缺乏。在本次调研中,我们对可信的 T2I DMs 文献进行了及时且重点突出的回顾,涵盖了从属性、手段、基准和应用等角度构建的简明分类结构。我们的调研首先介绍了 T2I DMs 的基本知识,随后总结了 T2I 任务特有的关键定义/指标,并基于这些定义/指标分析了最新文献中提出的研究手段。此外,我们还回顾了 T2I DMs 的基准测试和领域应用。最后,我们指出了当前研究中的空白,讨论了现有方法的局限性,并提出了未来研究方向,以推动可信 T2I DMs 的发展。此外,我们还通过我们的 GitHub 仓库(https://github.com/wellzline/Trustworthy-T2I-DMs)保持领域最新进展的更新。 关键词—文本到图像扩散模型,人工智能安全,可靠性,负责任的人工智能,基础模型,多模态模型。
1. 引言
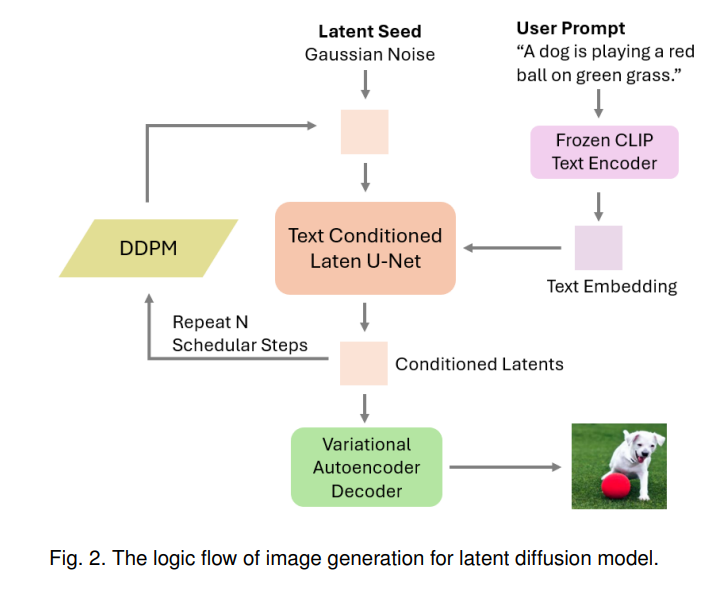
文本到图像 (T2I) 扩散模型 (DMs) 在生成高保真图像方面取得了显著进展。通过简单的自然语言描述生成高质量图像的能力,可能会为多个现实世界的应用带来巨大好处,如智能汽车 [1], [2], [3]、医疗保健 [4], [5], [6],以及一系列不受领域限制的生成任务 [7], [8], [9], [10], [11]。扩散模型是一类概率生成模型,它通过先注入噪声再进行逆过程来生成样本 [12]。T2I DMs 是其中的一种特殊实现,通过描述性文本作为指导信号来引导图像生成。像 Stability AI 的 Stable Diffusion (SD) [13] 和 Google 的 Imagen [14] 这样的模型,经过大规模带注释的文本-图像对数据集训练,能够生成照片般真实的图像。商业产品如 DALL-E 3 [15] 和 Midjourney [16] 在多个 T2I 应用中展示了令人印象深刻的能力,推动了该领域的发展。 然而,类似于传统深度学习 (DL) 系统 [17], [18], [19],T2I DMs 的日益普及和进步也引发了伦理和社会问题 [20], [21], [22],特别是围绕信任度的一系列非功能性属性问题,包括鲁棒性、公平性、安全性、隐私性、事实性和可解释性。然而,由于 T2I DMs 的独特特性,传统 DL 的信任度研究方法并不直接适用于它们。这里有两个主要区别:(1) 传统的信任度研究通常针对单一模态系统,无论是文本 [23], [24] 还是图像 [25], [26],而 T2I DMs 涉及多模态任务,处理输入(文本)和输出(图像)等更为多样的数据结构 [27],这使得传统 DL 任务中提出的黑箱信任度方法不再适用;(2) 与传统的确定性 AI 模型(如用于 DL 分类任务的模型)相比,T2I DMs 的生成机制有所不同。即使与生成式对抗网络 (GANs) 等随机生成式 AI 模型相比,T2I DMs 的训练目标和基础算法也有本质区别 [28], [29], [30]。因此,传统 DL 的白箱方法无法直接应用于 T2I DMs。T2I DMs 的这些独特特性要求开发新的方法来应对其特定的信任度挑战。 为应对这一挑战,近年来涌现了大量关于 T2I DMs 信任度的研究。然而,社区中仍然缺乏专门针对这一关键且新兴领域的调查研究。为此,本次调研旨在填补这一空白——提供一份关于 T2I DMs 信任度的及时且重点突出的文献综述。
范围、分类和术语
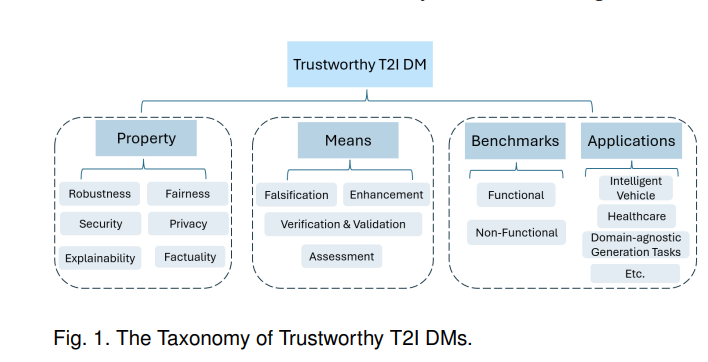
在本次调研中,我们特别关注 T2I DMs 信任度的六个关键非功能性属性1:鲁棒性、公平性、安全性、隐私性、事实性和可解释性。此外,我们通过四种方式探讨这些属性:伪造、增强、验证与确认 (V&V) 以及评估。我们对属性和手段的选择基于传统 DL 系统中常研究的信任度和安全性方面 [17], [31], [32],这些系统定义了一组类似的属性,仅在命名上略有不同。此外,我们还总结了 T2I DMs 的几个基准测试和应用领域。该分类如图 1 所示。 图 1. 可信 T2I DMs 的分类。
我们现在为每个属性提供非正式定义,正式定义将在后面介绍:
- 鲁棒性 是指模型在面对“小”输入扰动时保持一致性能的能力。
- 公平性 是确保模型输出不会偏向或歧视某些个人或群体。
- 安全性(本文中特别关注后门攻击)涉及保护模型免受隐藏漏洞的攻击,这些漏洞可能在特定输入触发时导致恶意预测。
- 隐私性 是指训练模型可能无意中泄露训练数据中的敏感信息的风险。
- 可解释性 旨在使模型的内部工作机制变得可理解,为模型如何做出决策提供洞见。
- 事实性 是指生成的图像与文本描述的常识或事实保持一致,而不仅仅是与文本提示相匹配。
此外,我们将研究这些属性的四种主要手段进行分类:
- 伪造 涉及通过设计和执行复杂攻击暴露模型的漏洞,从而展示模型的缺陷或弱点。
- 验证与确认 (V&V) 侧重于确保模型的正确性,检查其是否符合预定义的(正式)规范。
- 非功能性属性(也称为质量属性)指的是描述系统如何执行其功能的特性,而不是系统执行什么功能。
- 评估 类似于 V&V,但不针对特定规范,而是设计和应用指标来评估模型。
- 增强 涉及实施对策以保护模型免受各种威胁或修复影响模型信任度的缺陷。
总而言之,在本次综述的范围内,伪造旨在“查找漏洞”,评估旨在设计信任度测量规范,V&V 旨在实施符合过程,最后,增强旨在设计附加机制。
相关综述
扩散模型 (DMs) 在多个领域取得了显著的性能提升,极大地推动了生成式 AI 的发展。已有若干综述总结了 DMs 的进展,包括通用综述 [33], [34] 以及专注于特定领域的综述,如视觉 [35]、语言处理 [36], [37]、音频 [38]、时间序列 [39] 和医学分析 [40]。此外,还有综述涵盖了 DMs 在不同数据结构中的应用 [41]。然而,这些综述都未专门针对文本到图像 (T2I) 任务。 在 T2I DMs 领域,一些评论深入探讨了功能性属性 [27], [42], [43],但它们忽略了非功能性属性。相比之下,我们的工作聚焦于信任度,提供了对研究非功能性属性的现有方法的及时分析,并指出了当前研究的局限性。此外,一些研究分析了 T2I DMs 的特定属性,如可控生成。例如,[44] 重点分析了新条件在 T2I 模型中的集成及其影响,而 [45] 探讨了文本编码器在 T2I DMs 图像生成过程中的作用。最近的工作 [46] 调查了多种类型的攻击,包括对抗性攻击、后门攻击和成员推断攻击 (MIAs),以及相应的防御策略。然而,这些综述都没有全面探讨信任度作为一组属性和手段的关键问题。据我们所知,本工作是第一个全面深入分析 T2I DMs 的信任度非功能性属性及其应对手段的研究,同时涵盖了它们的基准和应用。
贡献
总而言之,我们的主要贡献如下:
- 分类法:我们提出了一个简明的可信 T2I DMs 分类法,涵盖三个维度——非功能性属性的定义、研究这些属性的手段以及基准和应用。
- 综述:我们围绕提出的信任度分类法进行了一项及时且重点突出的综述,汇集了71篇相关论文。
- 分析:我们对六个与信任度相关的非功能性属性和四种手段进行了深入分析,概括了所综述论文中的解决方案,进行了比较,识别了模式和趋势,并总结了关键论点。
- 空白和未来方向:我们为每个属性和手段识别了研究空白,指出了现有工作的局限性,并提出了推动可信 T2I DMs 发展的未来研究方向。