
随着大型语言模型(LLMs)的持续进步,它们在作为智能体部署时的推理与决策能力得到了显著提升。然而,更丰富的推理往往需要更长的思维链(Chain of Thought, CoT),从而在真实场景中阻碍交互效率。尽管如此,目前仍缺乏对 LLM 智能体效率的系统性定义,限制了针对性的改进。 为此,我们提出**双重效率(dual-efficiency)**的概念,包括: (i) 步骤级效率(step-level efficiency):最小化每一步所需的 token 数; (ii) 轨迹级效率(trajectory-level efficiency):最小化完成任务所需的步骤数量。 基于这一定义,我们提出 DEPO ——一种兼顾两类效率的偏好优化方法,通过同时奖励更简洁的回答和更少的动作步骤来提升效率。 在 WebShop 和 BabyAI 上的实验结果表明,DEPO 能够最多减少 60.9% 的 token 使用量和 26.9% 的步骤数,同时带来最高 29.3% 的性能提升。DEPO 还可泛化至三个领域外的数学基准,并且在仅使用 25% 训练数据时仍保持其效率收益。
项目页面 — https://opencausalab.github.io/DEPO
1 引言
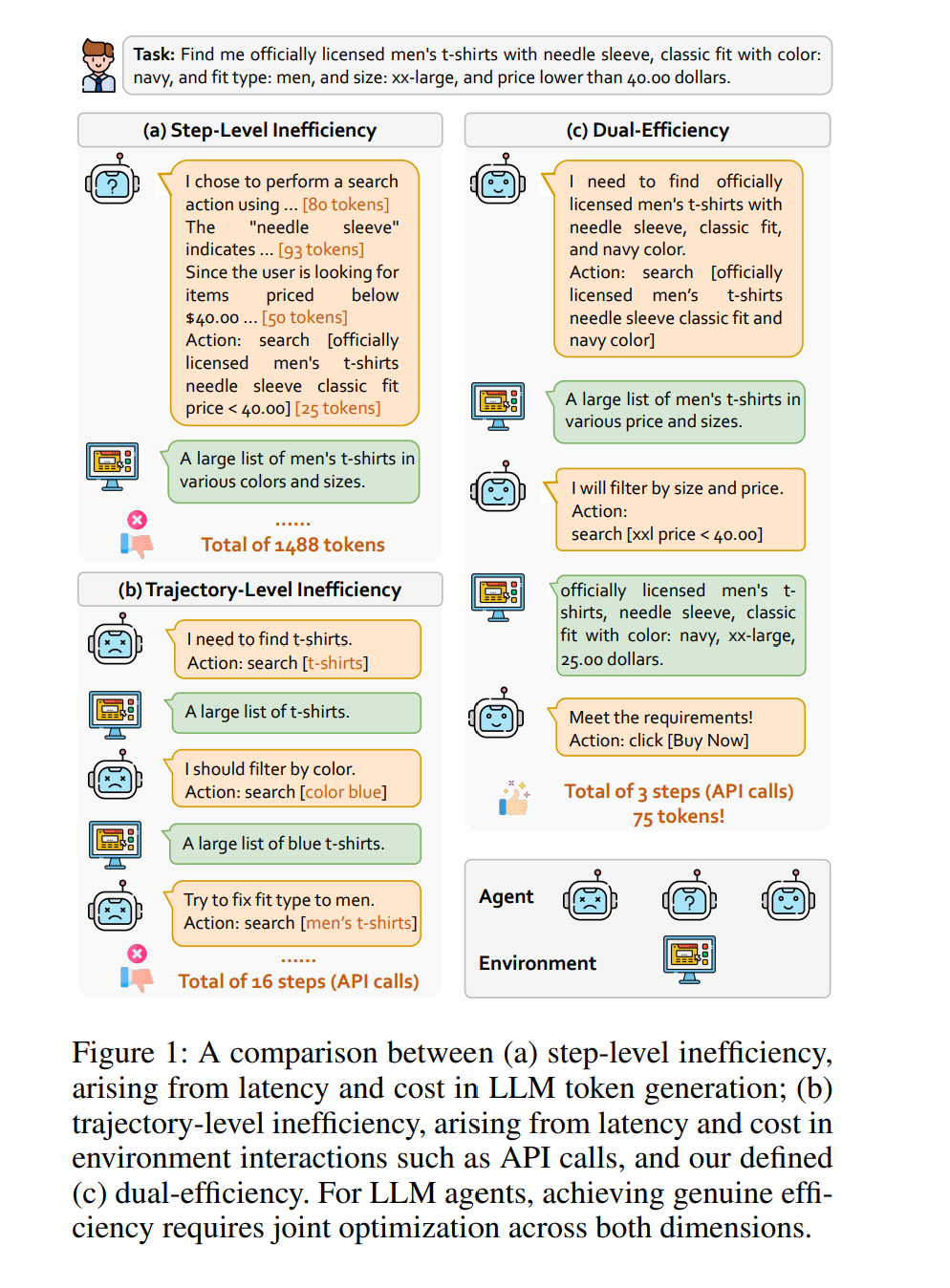
大型语言模型(LLMs)在长上下文推理(Bai et al. 2024)、代码生成(Zhuo et al. 2025)以及数学推理(Luo et al. 2025b)等复杂任务上表现出令人瞩目的能力。为了让这些能力更加贴近真实应用,近期研究开始探索 LLM 智能体(LLM agents),旨在构建能够执行任务规划、工具使用,并与动态环境进行多轮交互的自主系统(Shi et al. 2024; Song et al. 2024; Chen et al. 2024; Zeng et al. 2024; Yuan et al. 2025; Fu et al. 2025; Wang et al. 2025c; Feng et al. 2025a)。随着更先进的模型追求更高的推理准确性,其思维链(CoT, Wei et al. 2022; Zhao et al. 2025)往往变得更长,导致响应延迟增加、执行效率降低。效率对于将 LLM 智能体从原型推进至实际应用至关重要,因为缓慢的响应时间是阻碍真实部署的一大障碍。然而,提高速度不能以牺牲准确性为代价——一个快速但不可靠的智能体是无用的,甚至具有危害性。因此,我们在保持推理质量的前提下寻求提升响应效率。 当前关于 LLM 效率的讨论主要集中于减少生成的 token 数量(Wang et al. 2025a; Qu et al. 2025; Feng et al. 2025b)。然而,这一视角忽视了 LLM 智能体的交互动态特性。在实践中,智能体通常需要在每个决策步骤执行 API 调用或访问 Web 服务,其延迟和成本更多取决于步骤数量而非仅仅 token 数量。因此,我们首先从两个关键维度定义了 LLM 智能体的效率,即我们称之为双重效率(dual-efficiency): 1. 步骤级效率(step-level efficiency):旨在最小化每个交互步骤生成的 token 数,促进回答更简洁。 1. 轨迹级效率(trajectory-level efficiency):旨在最小化完成任务所需的总交互步骤数量。
图 1 展示了步骤级与轨迹级低效智能体的示例,以及实现双重效率的智能体。步骤级低效的智能体由于过度思考导致每一步 token 使用过高(图 1(a));轨迹级低效的智能体虽然每步简洁,但由于推理不准确导致完成任务需要大量步骤(图 1(b))。相比之下,双重高效的智能体同时保持单步 token 少与总步骤少,实现快速且高效的任务完成(图 1(c))。 现有强化学习(RL)方法是对齐 LLM 与人类偏好的重要工具,其中 PPO 是代表性方法(Schulman et al. 2017; Luo et al. 2025a; Shen et al. 2025; Aggarwal and Welleck 2025)。近期工作进一步提升了训练稳定性(如 DPO (Rafailov et al. 2023; Chen et al. 2025)、GRPO (Shao et al. 2024)),并降低了计算成本(如 KTO (Ethayarajh et al. 2024))。然而,这些方法主要关注模型的学习动态,而非智能体的效率——即智能体与环境交互的有效性。 为填补这一空白,我们提出 DEPO,一种面向 LLM 智能体的**双重效率偏好优化(Dual-Efficiency Preference Optimization)**方法,显式地同时优化步骤级与轨迹级效率。具体而言,我们将 KTO 扩展为加入一个 efficiency bonus(效率奖励) —— 一个加在 desirable log-ratio 上、与参数无关的偏移量,用于奖励使用更少步骤与更少 token 的样本;然后结合 KL 散度(Kullback and Leibler 1951)应用 sigmoid 偏好损失。该奖励促使模型在高效轨迹上产生更大的决策边界,从而放大其偏好得分,而不改变损失形式或 undesirable 分支。总体而言,DEPO 仅依赖离线的 desirable / undesirable 标签,不需要成对标注、奖励模型训练或 on-policy 采样,具有训练稳定、计算高效、数据高效的优点。 我们在五个广泛使用的基准上,对多个 LLM 智能体进行了全面实验,包括 WebShop、BabyAI、GSM8K、MATH 和 SimulEq。结果表明,DEPO 能显著提升智能体效率:相较于行为克隆(BC),token 使用量最多减少 60.9%;相较于 vanilla KTO,步骤数量最多减少 26.9%。更重要的是,DEPO 在不牺牲性能的前提下提升效率,甚至获得了额外性能提升 —— 其中最大增幅相对 BC 为 29.3%。此外,DEPO 在三个领域外数学基准上同样展现了强泛化能力。最后,DEPO 具有优异的样本效率,即使仅使用 25% 的训练数据仍能保持效率提升。 总之,我们的主要贡献如下:
我们正式定义了 LLM 智能体的双重效率——包括步骤级效率与轨迹级效率,为高效算法的开发与评估提供了理论基础。 * 我们提出了 DEPO,将双重效率偏好注入 vanilla KTO,引导模型生成更少 token、需要更少步骤的响应。
我们进行了全面实验验证 DEPO 的有效性,并展示其强泛化能力与样本效率。
