

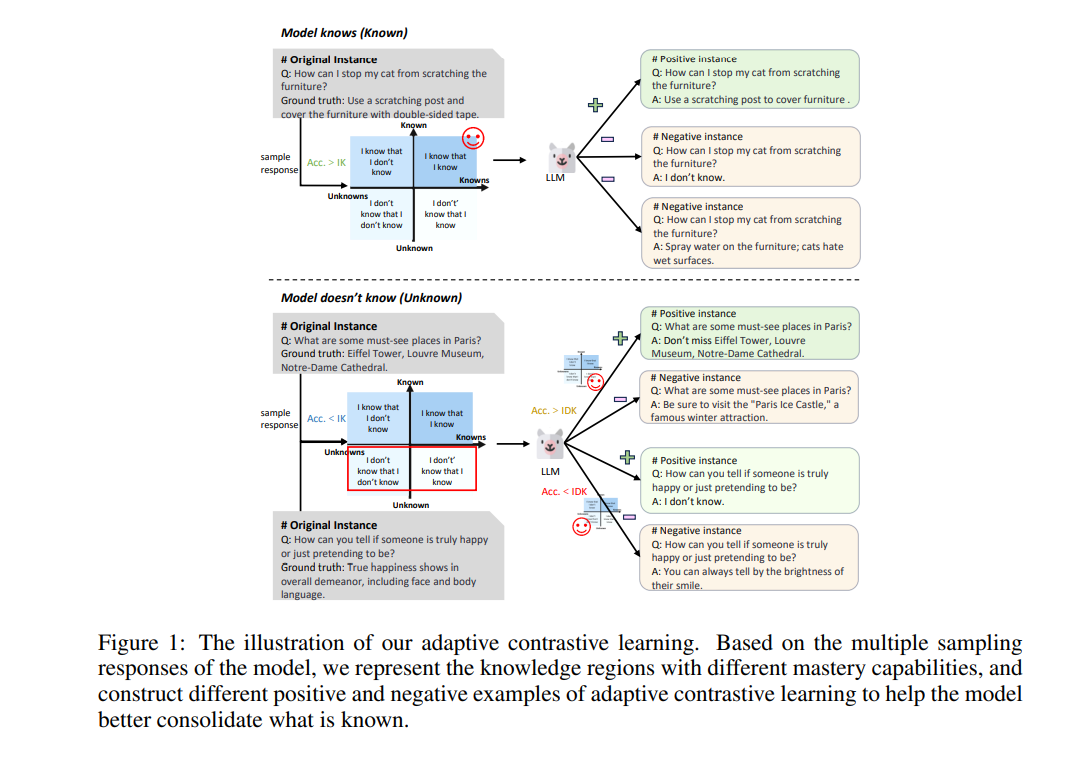
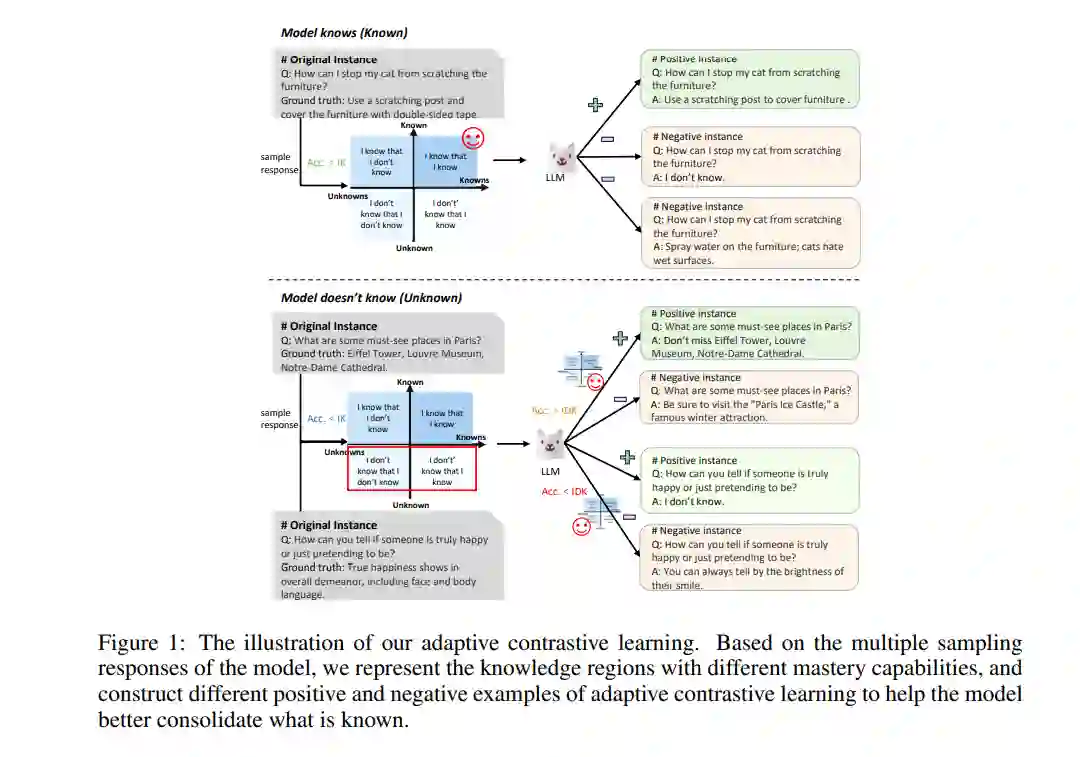
如何减轻大规模语言模型(LLMs)中的幻觉问题,一直是LLMs研究社区追求的根本目标。通过回顾大量与幻觉相关的研究,减少幻觉的主流方法之一是通过优化LLMs的知识表示来改变其输出。考虑到这些工作的核心关注点是模型所获取的知识,而知识一直是人类社会进步的核心主题,我们认为模型在精炼知识的过程中,可以从人类的学习方式中大大受益。
在本研究中,我们通过模仿人类的学习过程,设计了一种自适应对比学习策略。我们的方法根据LLMs实际掌握的知识灵活地构建不同的正负样本进行对比学习。这一策略帮助LLMs巩固它们已掌握的正确知识,深化它们对已接触但未完全理解的正确知识的理解,忘记之前学习过的错误知识,并诚实地承认它们缺乏的知识。大量实验和广泛使用的数据集上的详细分析验证了我们方法的有效性。
成为VIP会员查看完整内容

相关内容
Arxiv
224+阅读 · 2023年4月7日


相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日