

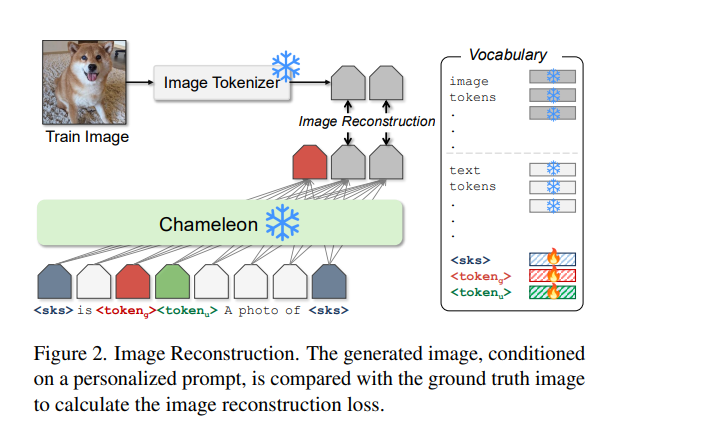
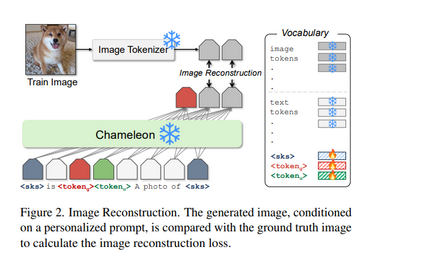
大型多模态模型(如 GPT-4、Gemini、Chameleon)已发展为拥有数百万用户的强大工具。然而,这些模型仍然是通用模型,缺乏对特定用户概念的个性化知识。尽管已有研究探索了文本生成中的个性化问题,但尚不清楚这些方法如何扩展到新的模态,例如图像生成。 本文提出了 Yo’Chameleon,首次尝试在大型多模态模型中研究个性化问题。给定某一特定概念的 3–5 张图像,Yo’Chameleon 通过软提示调优(soft-prompt tuning)嵌入主体特定的信息,以实现:(i) 回答关于该主体的问题;(ii) 重建像素级细节,在新背景中生成该主体的图像。 Yo’Chameleon 的训练过程包括: 1. 一种自我提示优化机制(self-prompting optimization mechanism),以平衡不同模态间的表现; 1. 一种**“软正样本”图像生成策略**(soft-positive image generation approach),用于在小样本条件下提升图像质量。
我们的定性与定量分析表明,Yo’Chameleon 能够以更少的 token 更高效地学习概念,并有效编码视觉属性,其表现优于现有提示方法基线。
成为VIP会员查看完整内容

相关内容
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日