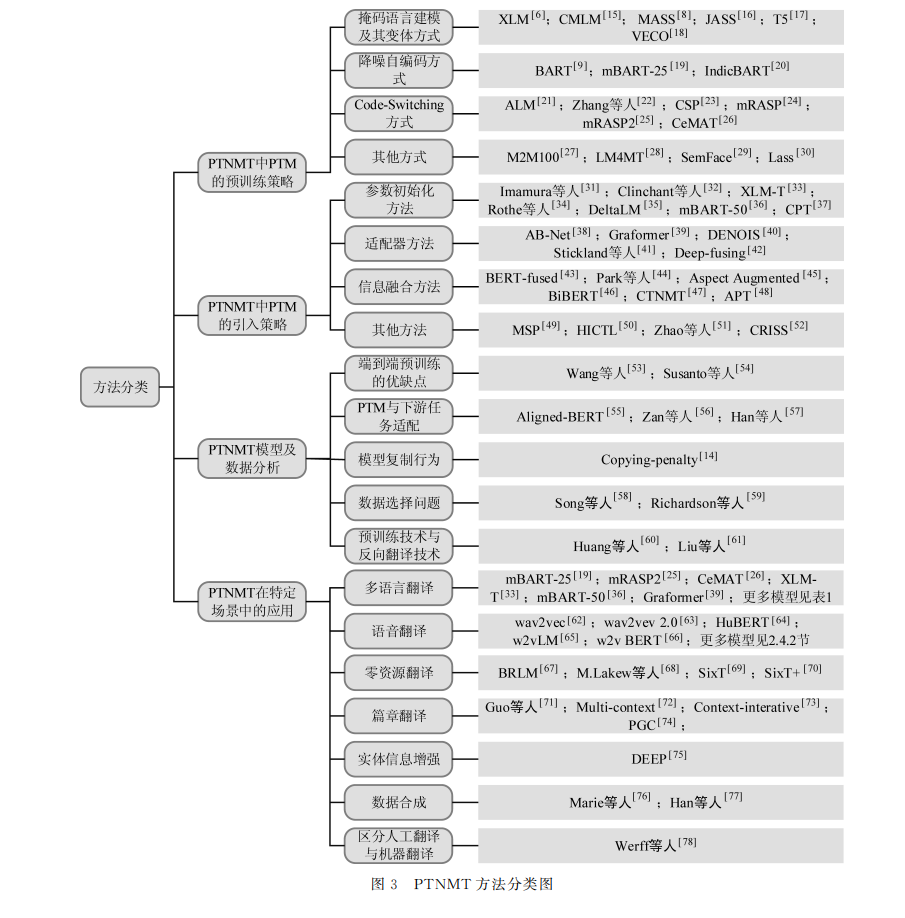
神经机器翻译(NMT)模型通常使用双语数据进行监督训练,而构建大规模双语数据集是一个巨大挑战。相比之下,大部分语言的单语数据集较为容易获取。近年来,预训练模型(PTM)能够在海量的单语数据上进行训练,从而得到通用表示知识,来帮助下游任务取得显著的性能提升。目前基于预训练的神经机器翻译(PTNMT)在受限资源数据集上已被广泛验证,但如何高效地在高资源NMT模型中利用PTM仍亟待研究。该文致力于对PTNMT的现状和相关问题进行系统性的整理和分析,从引入PTM的预训练方法、使用策略以及特定任务等角度对PTNMT方法进行详细的分类,并对PTNMT方法解决的问题进行总结,最后对PTNMT的研究进行展望。
机器翻译是自然语言处理领域中一个重要的研 究方向,其主要实现的功能是将源语言翻译成目标语 言。近年来,随着深度学习技术在人工智能领域的发 展,神 经 机 器 翻 译 (Neural Machine Translation, NMT)已经 成 为 机 器 翻 译 方 向 中 的 主 流 方 法。从 2013年发 展 至 今,研 究 人 员 提 出 许 多 模 型 来 实 现 NMT,例如,CNN [1]、RNN [2]、Transformer [3]等,最终 基于自注意力网络设计的 Transformer成为了 NMT 的主流范式[4]。 Transformer的出现,不 仅 带 动 了 NMT 的 发 展,也带动了整个自然语言处理领域的发展。其中, 受 Transformer 影 响 出 现 的 大 规 模 预 训 练 模 型 (Pre-TrainedModel,PTM)在许多自然语言处理任务上都取得了先进的性能。大量工作表明[5-9],在大 规模无标签数据上训练的 PTM 可以学习到“通用 表示知识”,这使 PTM 拥有强大的语言理解和生成 能力。PTM 的“通用表示知识”也引起了机器翻译 研究人员的关注,研究人员期望通过引入 PTM 来 提高 NMT 的性能。这种将 PTM 引入 NMT 的方 法被称为预训练神经机器翻译(Pre-trainedNeural MachineTranslation,PTNMT)。 与不引入 PTM 的 NMT 相 比,PTNMT 的 优 势可以总结为以下几点: (1)PTM 可以使 NMT 模型很好地利用无标 签数据; (2)PTM 可以提高 NMT 模型的泛化能力和 鲁棒性; (3)PTM 可 以 帮 助 NMT 搭 建 通 用 的 翻 译 模型。 当前,PTNMT 存在大量的工作,但尚不存在独 立地对其进行总结的综述文章,已有的 PTNMT 相 关整理工作都是以一节的形式出现在 PTM 综述文 章里。一部分工作[10-11]仅简单地对 PTNMT 进行 介绍,另一部分工作[12]则是从单语言和多语言角度 对 PTNMT 的部分工作进行分类说明。虽然也存 在对PTNMT 整体发展进行描述的报告[13],但这些 工作都缺少对 PTNMT 相关工作的系统性整理和 分析。本文主要以 PTNMT 的构建、问题分析和应 用为切入点,对相关工作进行详细的分类,侧重于对 不同方法进行对比,涵盖了最新的相关工作,分析了 PTNMT 的优缺点及其对其他任务的启发,首次完 成对 PTNMT 相关工作的系统性整理和分析工作。 本文组织结构如下:第 1 节简单介绍 NMT、 PTM 和 PTNMT 的背景;第2节介绍 PTNMT 相 关工作的分类对比;第3节总结 PTNMT 的优缺点 并进行相关分析;第4节对 PTNMT 研究的未来进 行展望;第5节总结本文内容。