
今年3月末,我们在arXiv网站发布了大语言模型综述文章《A Survey of Large Language Models》的第一个版本V1,该综述文章系统性地梳理了大语言模型的研究进展与核心技术,讨论了大量的相关工作。自大语言模型综述的预印本上线以来,受到了广泛关注,收到了不少读者的宝贵意见。

在发布V1版本后的5个月时间内,为了提升该综述的质量,我们在持续更新相关的内容,连续进行了多版的内容修订(版本号目前迭代到V12),**论文篇幅从V1版本的51页、416篇参考文献,到V11版本的85页、610篇参考文献,现在进一步扩增到V12版本的97页、683篇参考文献。**继6月末发布于arXiv网站的大修版本V11,V12版本是我们两个多月以来又一次进行大修的版本。 相较于V11版本,V12版本的大语言模型综述有以下新亮点:
- 新增了对于新兴架构、注意力方式和解码策略的简要介绍;
- 新增了指令微调实用技巧的相关介绍;
- 新增了关于RLHF与非RL对齐方法的概要介绍;
- 具体实验分析更加完善,在指令微调与能力评测实验新增了最新的模型;
- 新增了对评测方法的讨论,并对已有的评测工作进行总结;
- 增补了许多脉络梳理内容,以及大量最新工作介绍; 此外,我们综述的中文翻译版本也在持续更新(目前针对v10版本进行了翻译,并持续更新):

- 论文链接:https://arxiv.org/abs/2303.18223
- GitHub项目链接:https://github.com/RUCAIBox/LLMSurvey
- 中文翻译版本链接:https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey_Chinese.pdf
以下是综述部分章节的主要更新内容介绍,详细内容请参阅我们的英文综述。
1. 大语言模型相关资源
我们对于最新符合条件的模型进行了补充,持续更新了现有的10B+的模型图和表格(如有遗漏,欢迎读者来信补充):
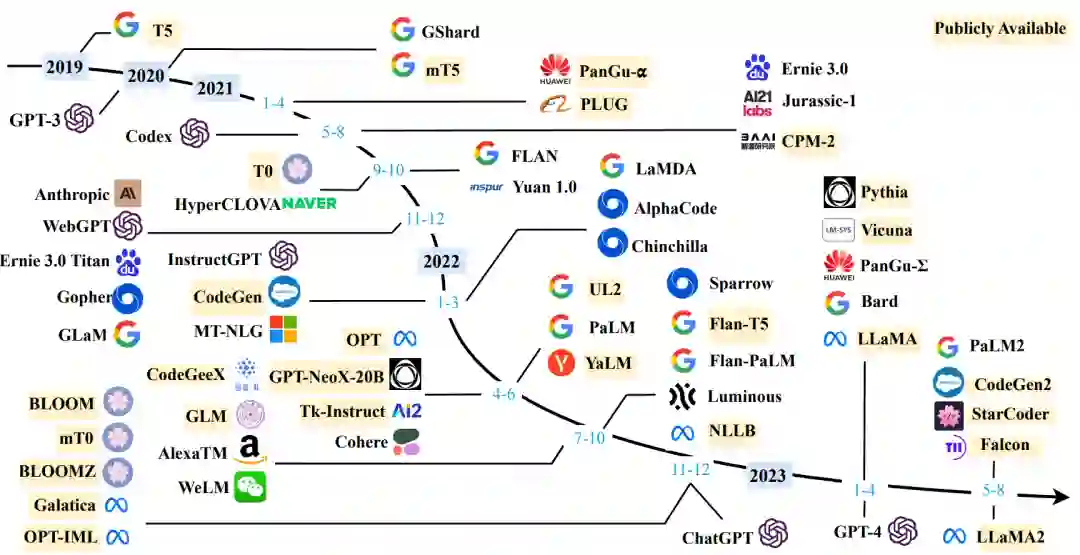
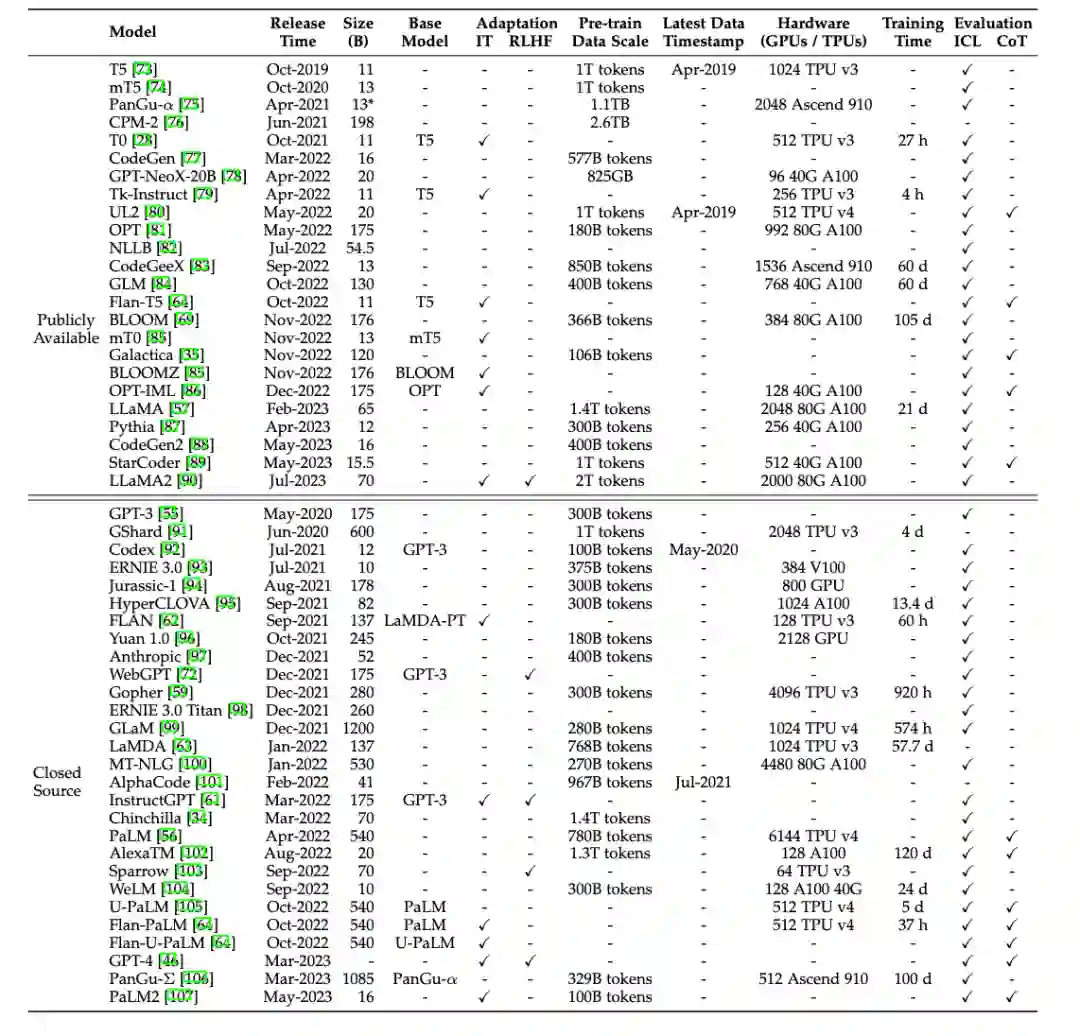
2. 大语言模型预训练技术
在模型架构部分,由于经典 Transformer 架构的注意力机制需要平方级别的时间复杂度进行计算,最近也出现一系列对语言建模新架构的探索,如S4、RWKV、RetNet 等,希望既可以具备 Transformer 在 GPU 上进行并行化训练的优势,也可以低复杂度、高效地进行解码与推断。此外也有一些工作致力于改进传统 Transformer架构的注意力机制或计算方式,使其高效训练和部署。我们新增了几种注意力机制的介绍,包括grouped-query attention,FlashAttention-2,以及PagedAttention。围绕这些内容,我们进行了简要介绍。此外,我们新增了解码策略子章节,介绍了常见的两种解码策略:贪心搜索和随机采样,并整理了针对这两种策略的改进算法,例如束搜索、top-p采样、top-k采样等策略。此外, 我们介绍了针对大模型的高效解码策略,以及具体模型和API解码时的常用设置。
3. 大语言模型适配技术
在适配技术章节,我们增加了大量讨论及实验分析。在指令微调部分中,我们新增了指令微调的实用技巧介绍。在指令微调实验部分,我们加入了LLaMA-13B模型的指令微调实验针对不同混合数据集的分析。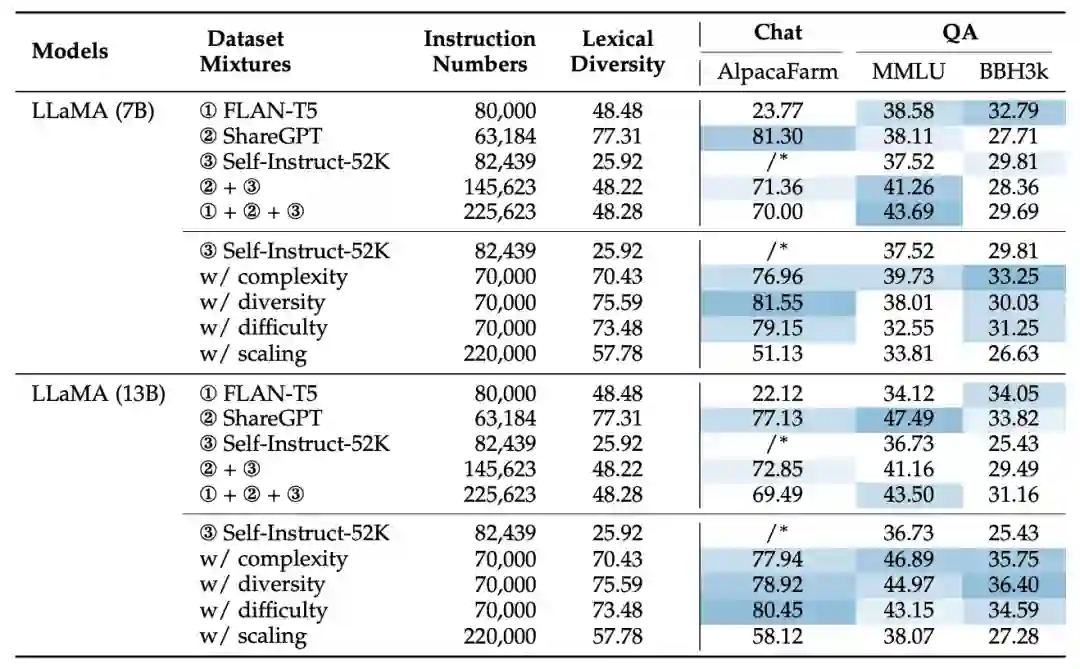
4. 大语言模型使用技术
经过预训练或适应性调整后,使用LLM的一个主要方法是设计合适的提示策略来解决各种任务。我们新增了表9对现有提示的代表性工作进行了总结,包括典型的LLM运用方法及其ICL、CoT和规划的重点。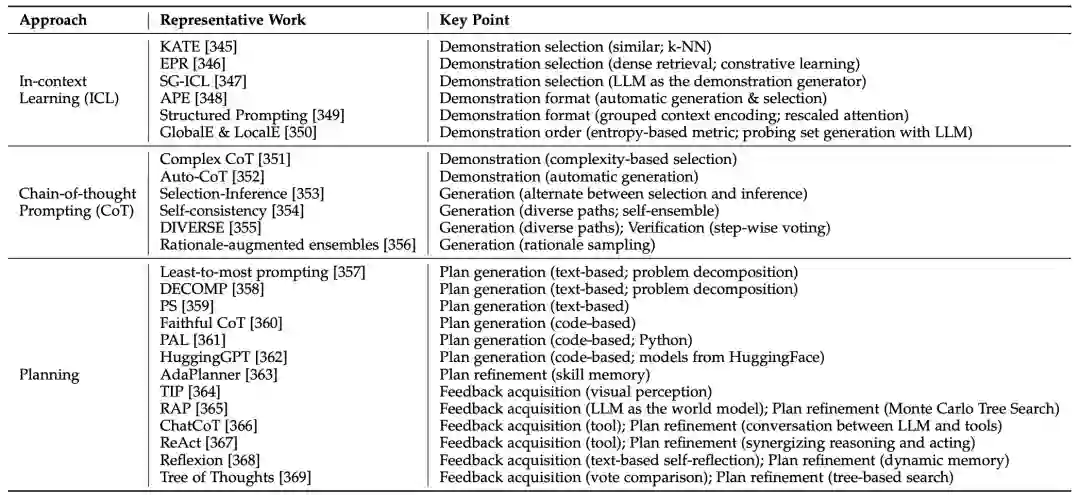

5. 大语言模型能力评估
大模型能力评估方面,我们增加了一个子章节对评测方法进行讨论,分别介绍了对基座模型、微调模型和专业模型的相关评测工作。我们总结了已有的评测工作,讨论了基准评测、人类评测和模型评测三类评测方法的优缺点。我们在表中总结了现有评测工作。
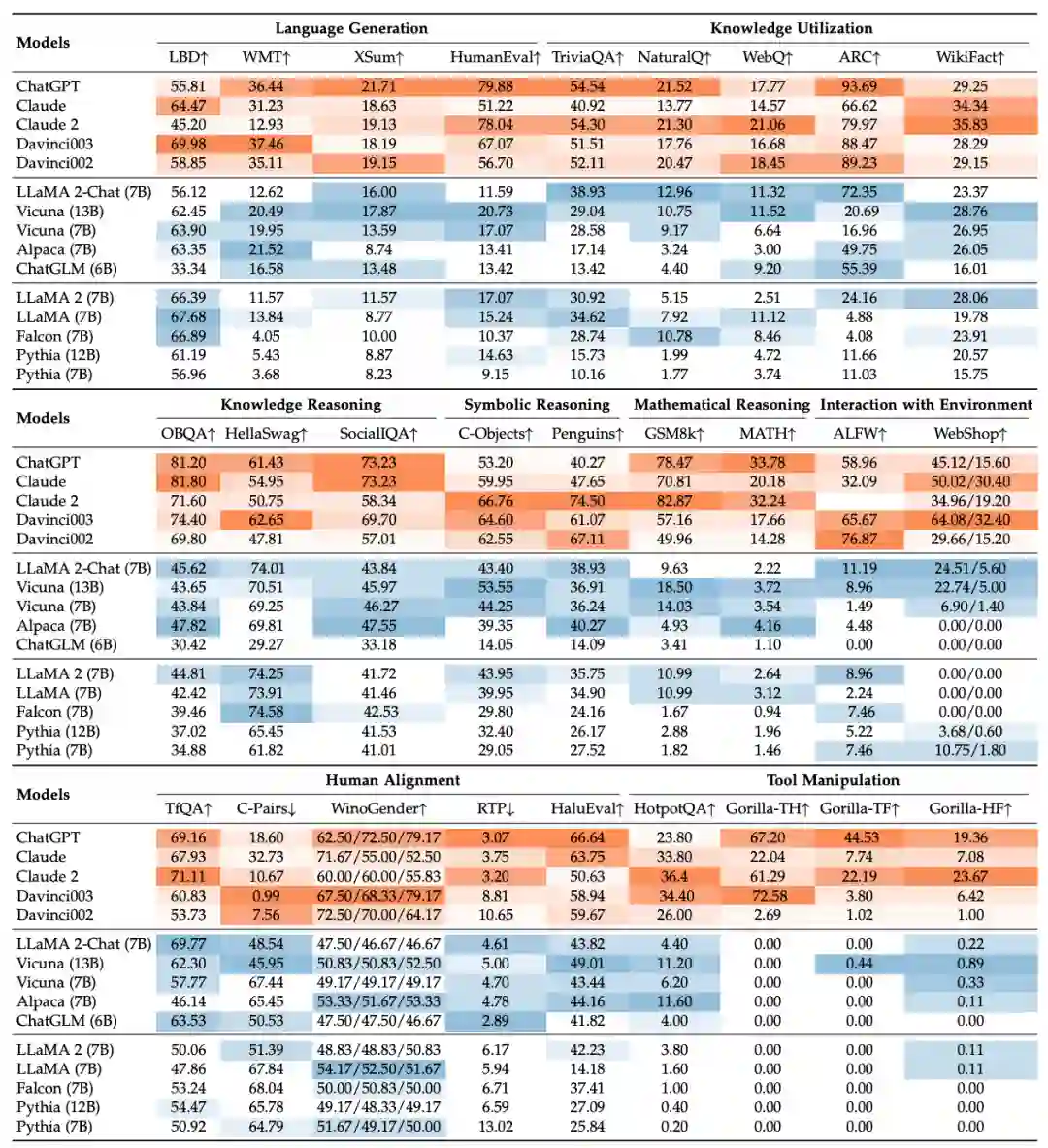
此外,随着新的大语言模型发布,我们在经验评测章节新增了多个热门大语言模型的评测结果,包括LLaMA 2 (Chat) 7B、Claude-2和Vicuna 13B,并补充了对新增模型的实验讨论。
6. 综述定位
一篇高质量的长篇综述文章需要大量的时间投入,所参与的老师和学生为此付出了很多的时间。尽管我们已经尽力去完善这篇综述文章,但由于能力所限,难免存在不足和错误之处,仍有很大的改进空间。我们的最终目标是使这篇综述文章成为一个“know-how”的大模型技术指南手册,让大模型的秘密不再神秘、让技术细节不再被隐藏。尽管我们深知目前这篇综述离这个目标的距离还比较远,我们愿意在之后的版本中竭尽全力去改进。特别地,对于预训练、指令微调、提示工程的内在原理以及实战经验等方面,我们非常欢迎读者为我们贡献想法与建议,可以通过GitHub提交PR或者邮件联系我们的作者。对于所有被采纳的技术细节,我们都将在论文的致谢部分中“实名+实际贡献”进行致谢。我们的综述文章自发布以来,收到了广泛网友的大量修改意见,在此一并表示感谢。也希望大家一如既往支持与关注我们的大模型综述文章,您们的点赞与反馈将是我们前行最大的动力。7. 本次修订的参与学生名单学生作者:周昆(新增了指令微调实验的任务设置与结果分析,添加了能力评测实验的实验设置与结果分析,添加了指令微调的实用技巧介绍,添加了RLHF实用策略的介绍)、李军毅(添加了非RL对齐方法的介绍)、唐天一(添加解码策略的介绍)、王晓磊(添加评测方法介绍)、侯宇蓬(添加第四章文字细节,更新图5)、闵映乾(添加第三章少数模型及相关介绍,更新表1、图2)、张北辰(添加表10)、陈昱硕(表8实验)、陈志朋(表12实验)、蒋锦昊(表12实验)、任瑞阳(表12实验)、汤昕宇(表12实验)学生志愿者:成晓雪(表12实验)、王禹淏(表12实验)、郑博文(表12实验)
附件:更新日志
版本时间主要更新内容V12023年3月31日初始版本V22023年4月9日添加了机构信息。修订了图表 1 和表格 1,并澄清了大语言模型的相应选择标准。改进了写作。纠正了一些小错误。V32023年4月11日修正了关于库资源的错误V42023年4月12日修订了图1 和表格 1,并澄清了一些大语言模型的发布日期V52023年4月16日添加了关于 GPT 系列模型技术发展的章节V62023年4月24日在表格 1 和图表 1 中添加了一些新模型。添加了关于扩展法则的讨论。为涌现能力的模型尺寸添加了一些解释(第 2.1 节)。在图 4 中添加了用于不同架构的注意力模式的插图。在表格 4 中添加了详细的公式。V72023年4月25日修正了图表和表格中的一些拷贝错误V82023年4月27日在第 5.3 节中添加了参数高效适配章节V92023年4月28日修订了第 5.3 节V102023年5 月7 日修订了表格 1、表格 2 和一些细节V112023年6月29日第一章:添加了图1,在arXiv上发布的大语言论文趋势图; 第二章:添加图3以展示GPT的演变及相应的讨论; 第三章:添加图4以展示LLaMA家族及相应的讨论; 第五章:在5.1.1节中添加有关指令调整合成数据方式的最新讨论,在5.1.4节中添加有关指令调整的经验分析,在5.3节中添加有关参数高效适配的讨论,在5.4节中添加有关空间高效适配的讨论; 第六章:在6.1.3节中添加有关ICL的底层机制的最新讨论,在6.3节中添加有关复杂任务解决规划的讨论; 第七章:在7.2节中添加用于评估LLM高级能力的代表性数据集的表格10,在7.3.2节中添加大语言模型综合能力评测; 第八章:添加提示设计; 第九章:添加关于大语言模型在金融和科学研究领域应用的讨论。 V122023年9月11日第三章:表格1新增模型,图2新增模型; 第四章:在4.2.1节中新增对新型架构的讨论,在4.2.2节中新增对几种注意力机制的介绍,新增4.2.4 节解码策略的介绍; 第五章:在5.1.2节中新增指令微调的实用技巧,在5.1.4节和表格 8中新增LLaMA-13B的指令微调实验分析,在5.2.3节中新增RLHF的实用策略,新增 5.2.4节不使用RLHF的对齐方法介绍,新增 5.2.5节关于SFT和RLHF的讨论; 第六章:新增表格 9 总结了提示的代表性工作,在 6.3节中更新了规划部分对记忆的介绍; 第七章:新增7.3.2节对评测方法的讨论,新增表格11对已有评测工作进行了总结,更新了7.4节经验能力评测及表格12的评测结果。
