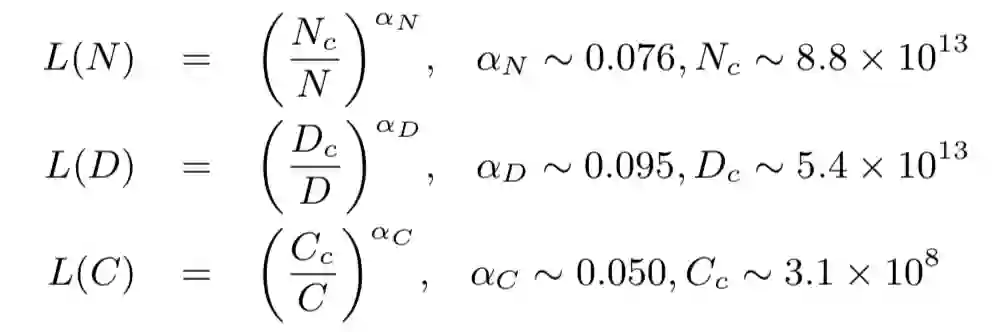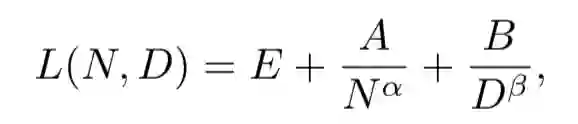今年3月末,我们在arXiv网站发布了大语言模型综述文章《A Survey of Large Language Models》的第一个版本V1,该综述文章系统性地梳理了大语言模型的研究进展与核心技术,讨论了大量的相关工作。自大语言模型综述的预印本上线以来,受到了广泛关注,收到了不少读者的宝贵意见。

在发布V1版本后的3个月时间内,为了提升该综述的质量,我们在持续更新相关的内容,连续进行了多版的内容修订(版本号目前迭代到V11),论文篇幅从V1版本的51页、416篇参考文献扩增到了V11版本的85页、610篇参考文献。V11版本是我们自五月中下旬开始策划进行大修的版本,详细更新日志请见文章结尾,已于6月末再次发布于arXiv网站。相较于V1版本,V11版本的大语言模型综述有以下新亮点:
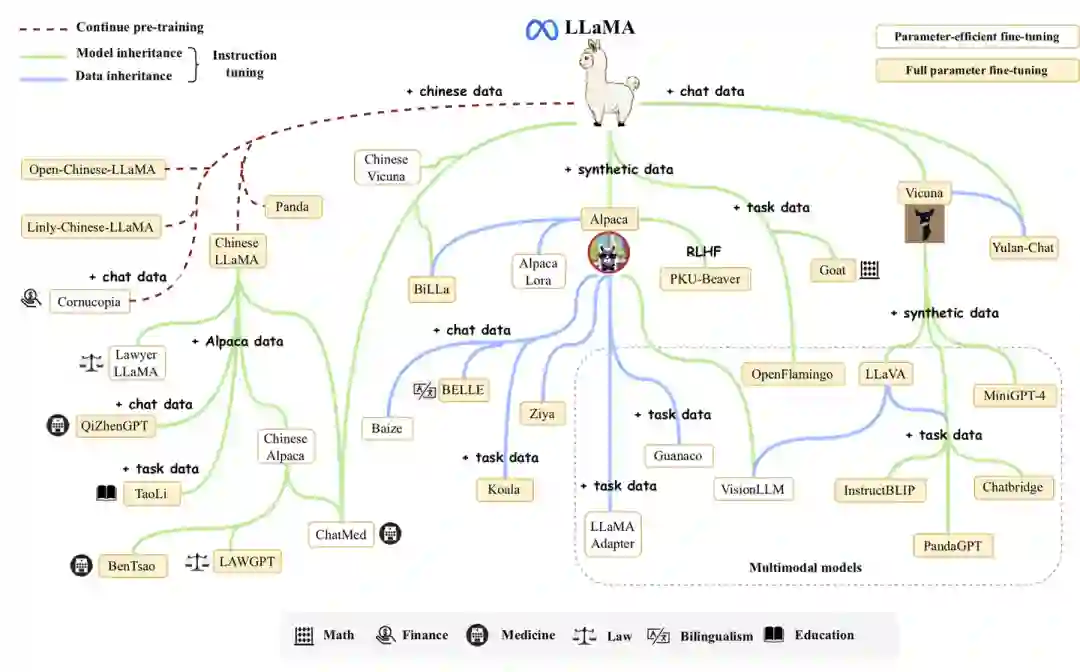
- 新增了对LLaMA模型及其衍生模型组成的LLaMA家族介绍;
- 新增了具体实验分析,包括指令微调数据集组合方式实验以及部分模型综合能力评测;
- 新增了大语言模型提示设计提示指南以及相关实验,总结了提示设计的原则、经验;
- 新增了参数高效适配和空间高效适配章节,总结了大语言模型相关的轻量化技术;
- 增加了对于规划(planning)的相关工作介绍;
- 增补了许多脉络梳理内容,以及大量最新工作介绍; 此外,我们综述的中文翻译版本也在持续更新(针对v1版本进行了翻译,并持续更新)

- 论文链接:https://arxiv.org/abs/2303.18223
- GitHub项目链接:https://github.com/RUCAIBox/LLMSurvey
- 中文翻译版本链接:https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey__Chinese_V1.pdf
1. 引言
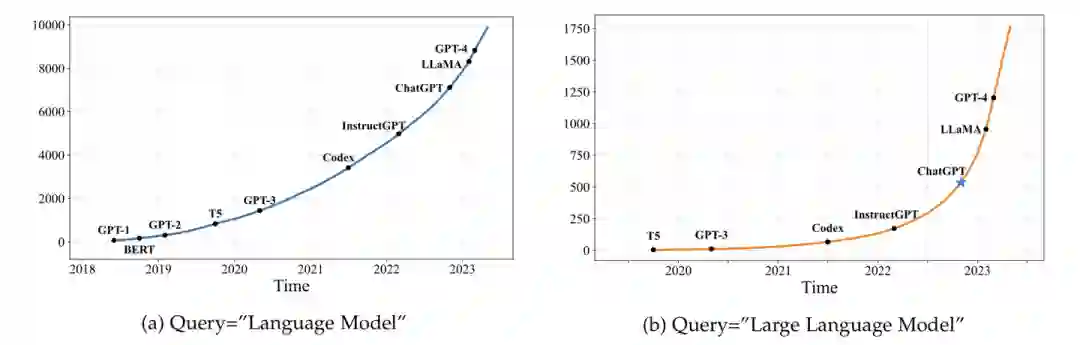
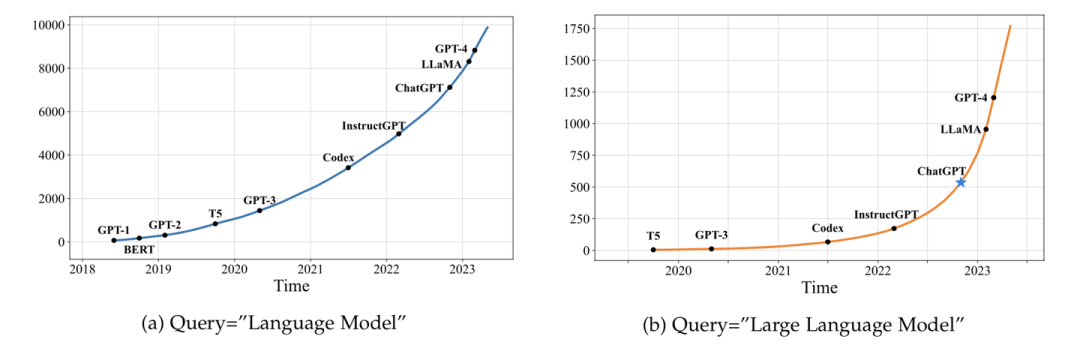
大语言模型目前已经成为学界研究的热点。我们统计了arXiv论文库中自2018年6月以来包含关键词"语言模型"以及自2019年10月以来包含关键词"大语言模型"的论文数量趋势图。结果表明,在ChatGPT发布之后,相关论文的数量呈现出爆发式增长,这充分证明大语言模型在学术界的影响力日益凸显,吸引了越来越多的研究者投入到这一领域。
2. 总览
相较于小模型,大模型扩展了模型大小、训练数据大小和总计算量,显著提升了语言模型的能力。在总览章节中,我们新增了**扩展法则(scaling law)**的讨论,其中重点介绍了KM扩展法则和Chinchilla扩展法则,这两个法则对于理解大语言模型的性能提升提供了重要参考。
- KM 扩展法则
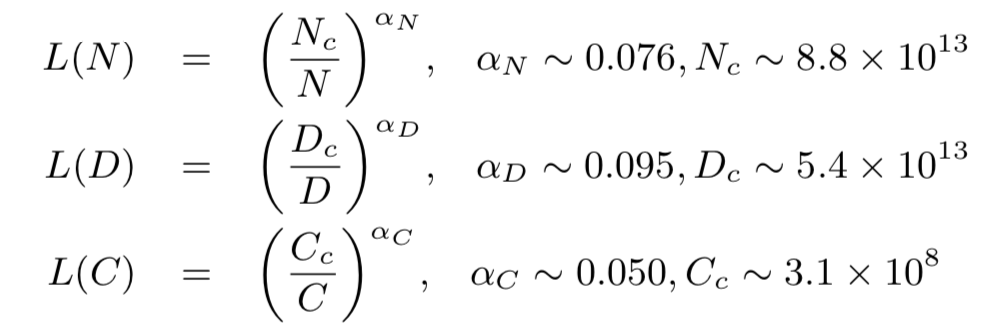
Chinchilla扩展法则
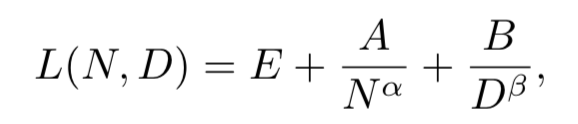
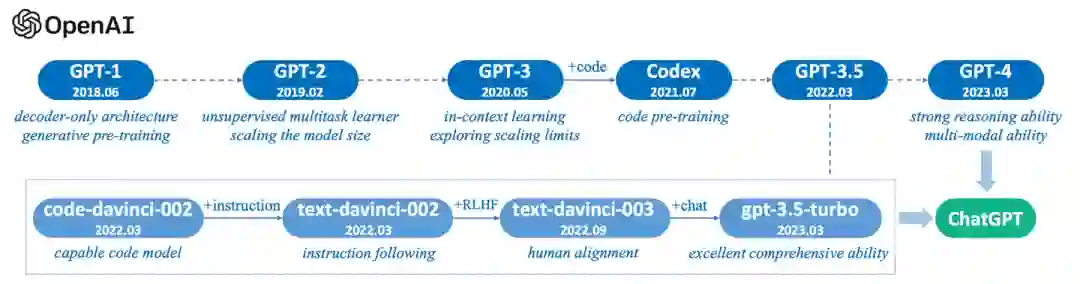
此外,我们新增了一部分关于OpenAI GPT系列语言模型的技术演进阶段的介绍(并附图)。这一部分将帮助读者了解GPT系列模型如何从最初的GPT开始,逐步演变成例如ChatGPT和GPT-4等更先进的大语言模型。
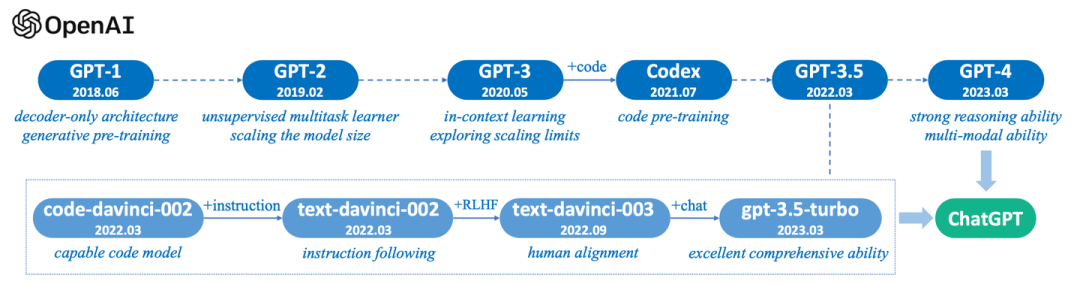
针对GPT系列的核心“预测下一个词”,还进一步加入了一些Ilya Sutskever的采访记录:

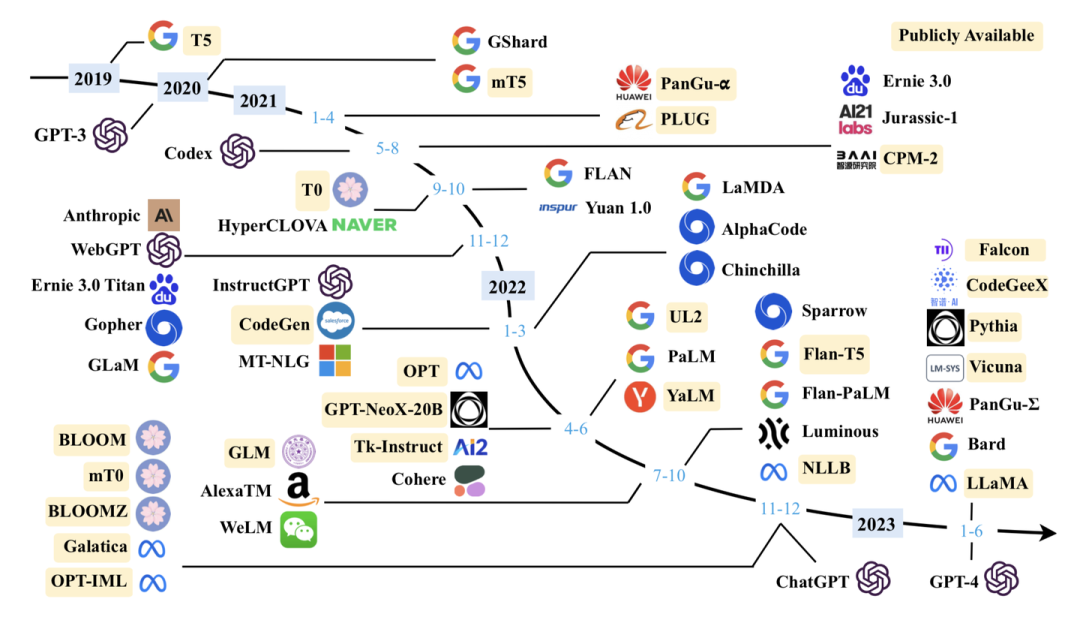
3. 大语言模型相关资源
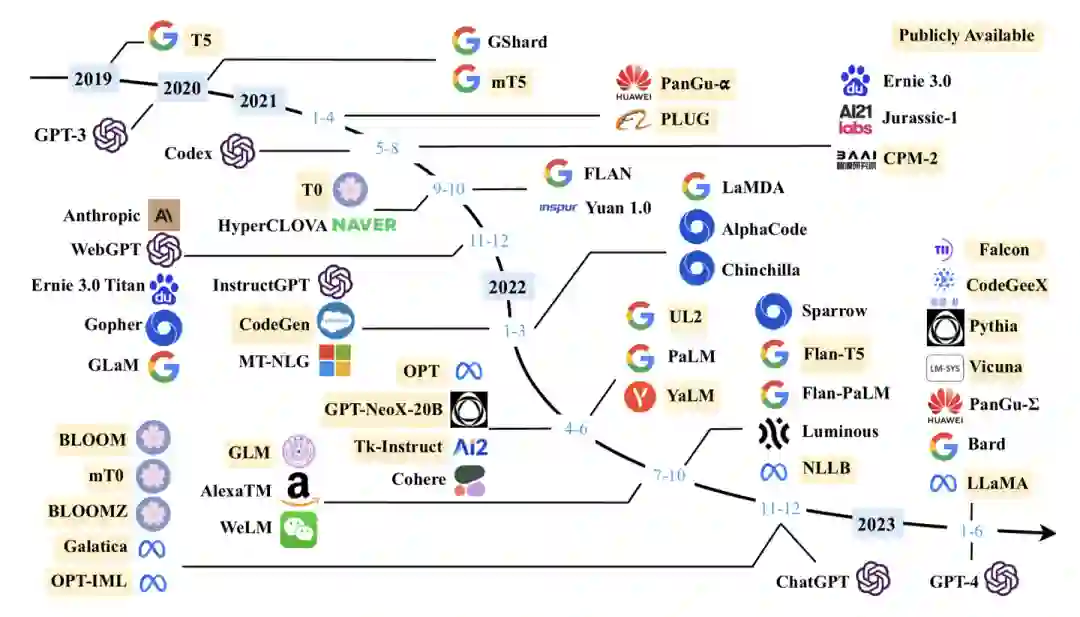
我们对于最新符合条件的模型进行了补充,持续更新了现有的10B+的模型图:
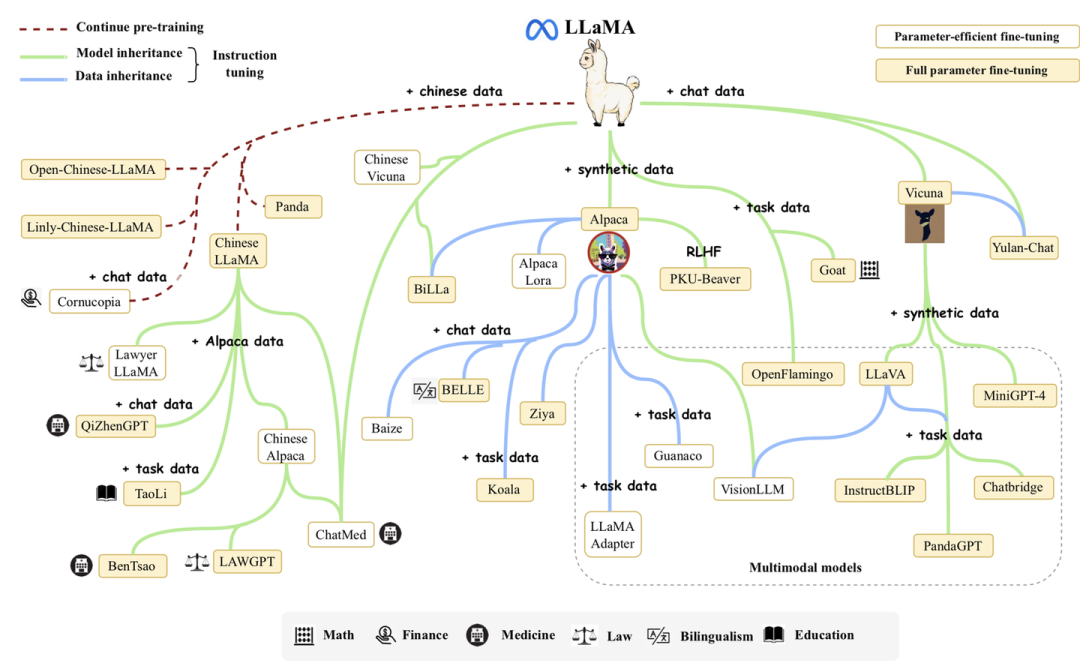
4. 大语言模型预训练技术
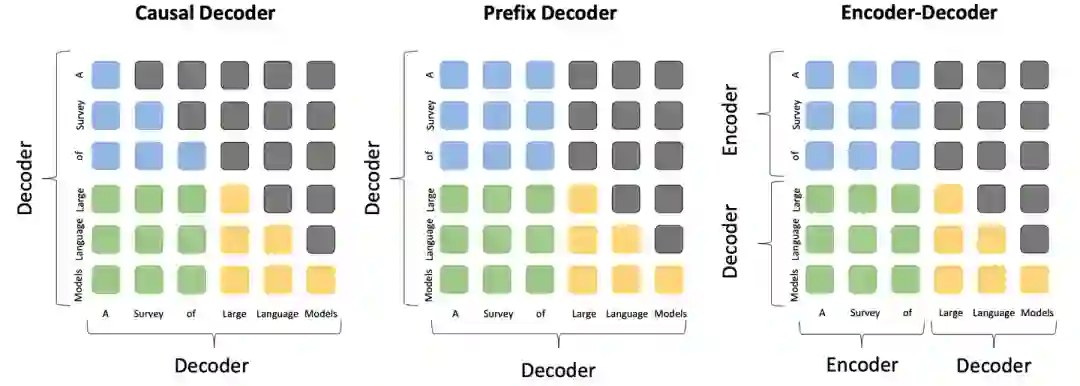
在预训练技术章节,我们大幅补充了大模型预训练各方面的技术细节。在模型架构部分,我们补充了三种主流模型架构的对比图,包括因果编码器、前缀解码器和编码器-解码器架构,从而直观的展示这三种架构的差异和联系。
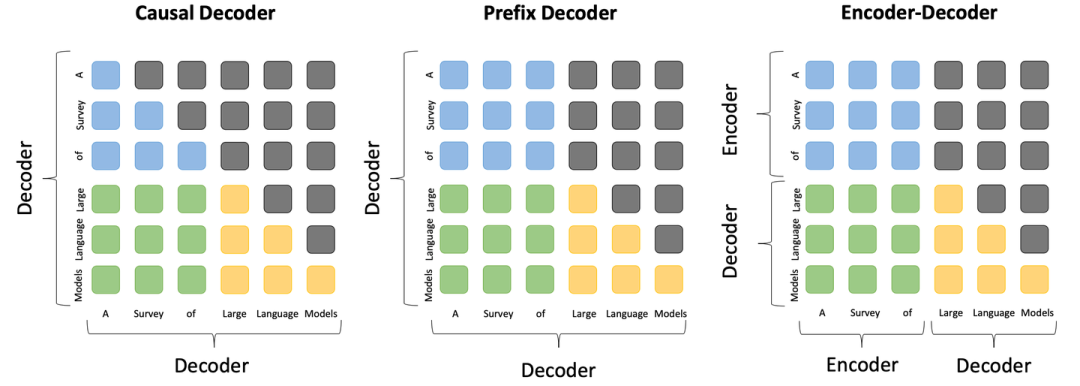
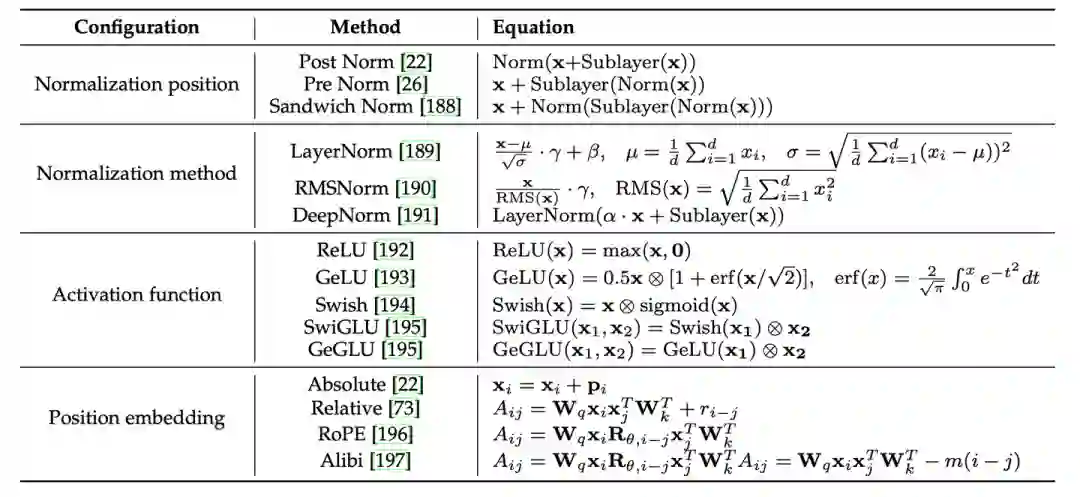
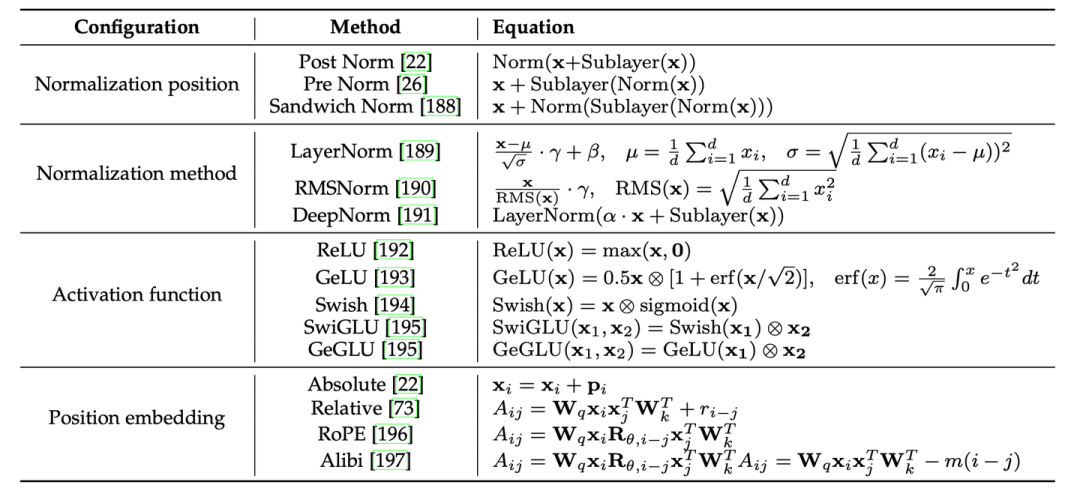
此外,我们详细补充了模型架构的各组件细节,包括分词、归一化方法、归一化位置、位置编码、注意力与偏置等等,并提供了Transformer架构多种配置的详细公式表。在最后的讨论章节,我们针对研究者广泛关注的长文本编码与生成挑战进行了讨论。

5. 大语言模型适配技术
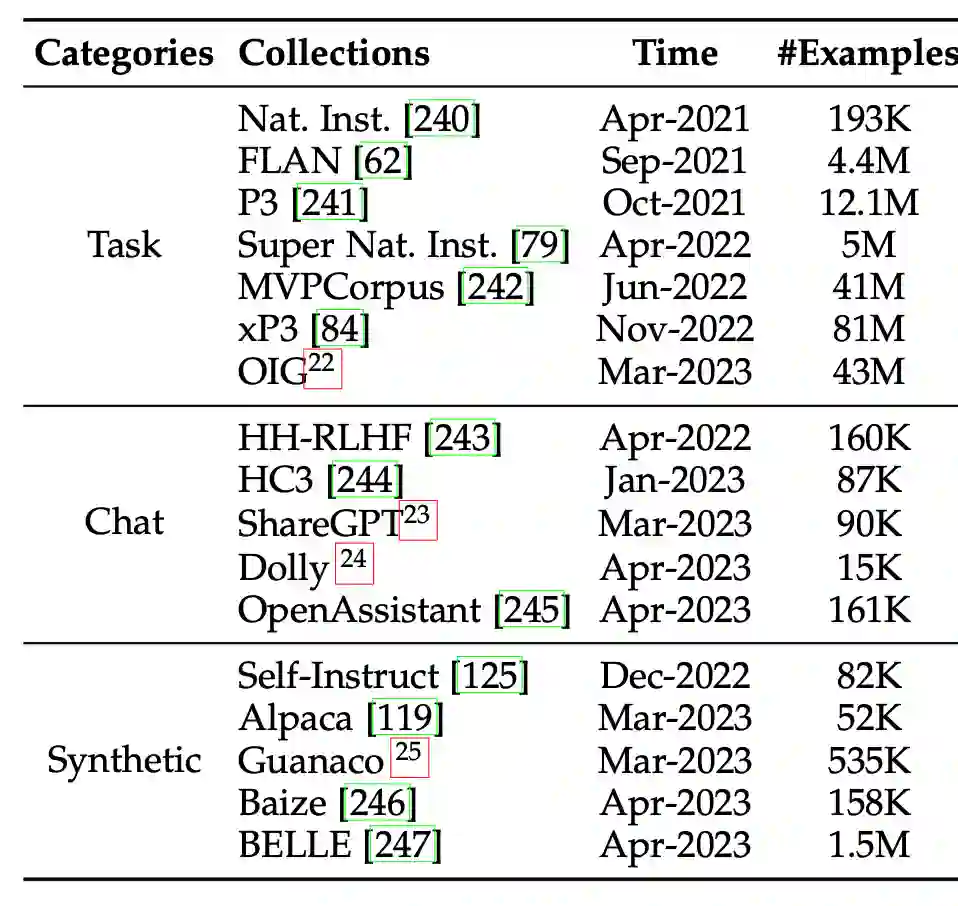
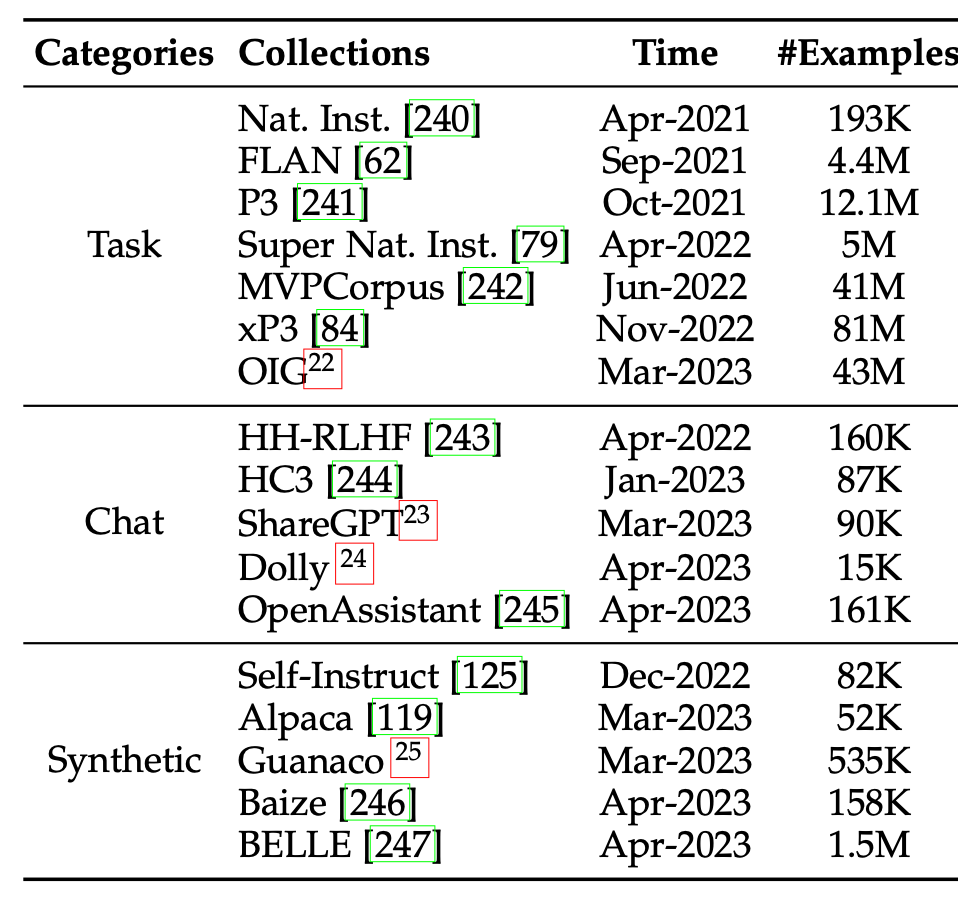
在适配技术章节,我们扩充了指令微调的技术细节,包括指令收集方法、指令微调的作用、指令微调的结果和对应分析。首先,我们按照任务指令、聊天指令、合成指令三类分别介绍了指令数据的收集方法,并收集了的指令集合。
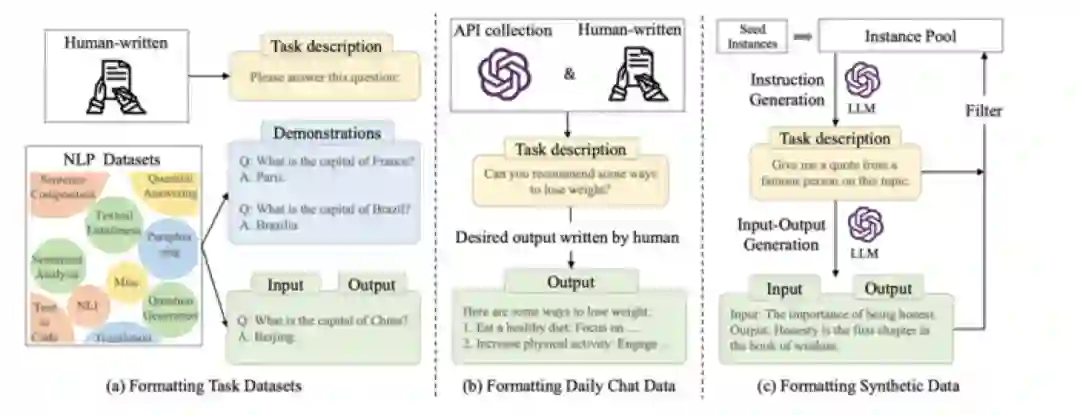
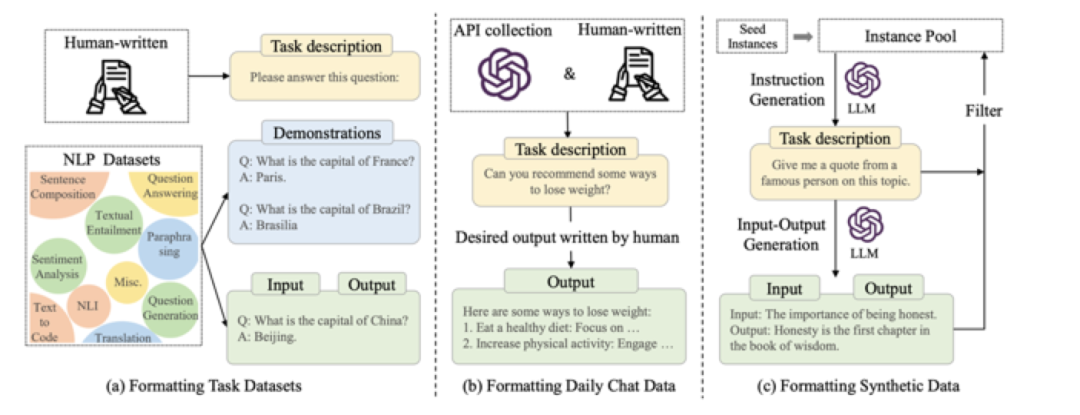
并且更新了指令集合的创建方式示意图:
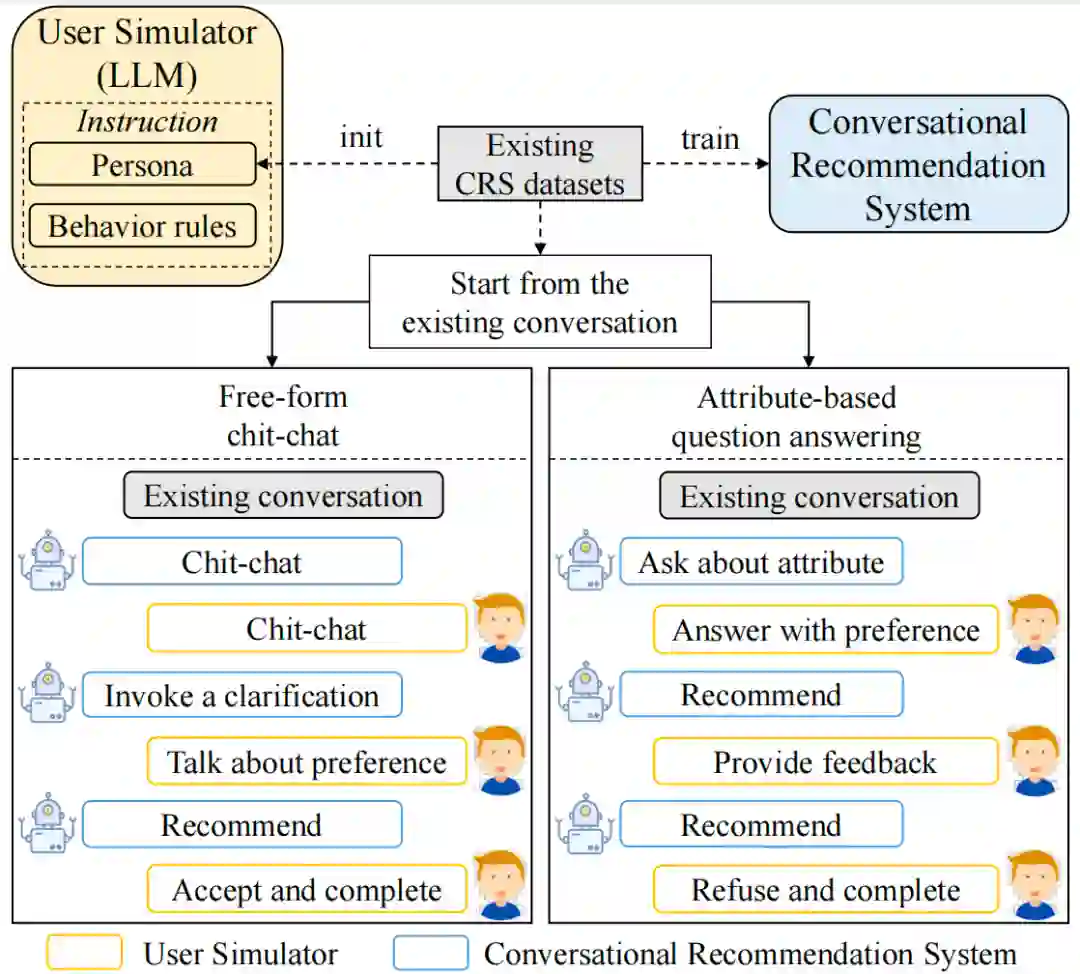
其次,为了探究不同指令数据对模型性能的影响,我们给出了不同数据混合策略下指令微调模型的实验结果供读者参考。为了让读者更好地上手指令微调,还给出了指令微调大模型的资源参考表,并给出了指令微调的实用建议。

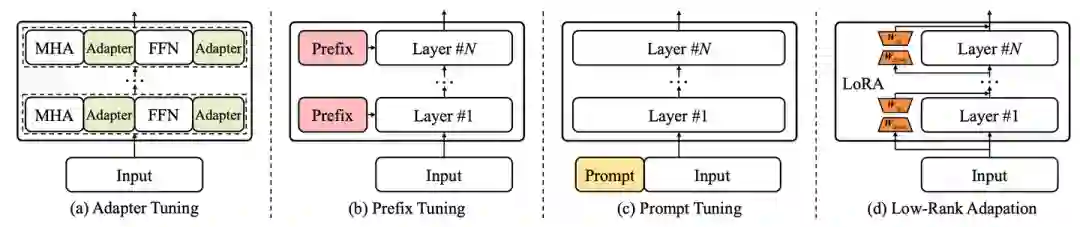
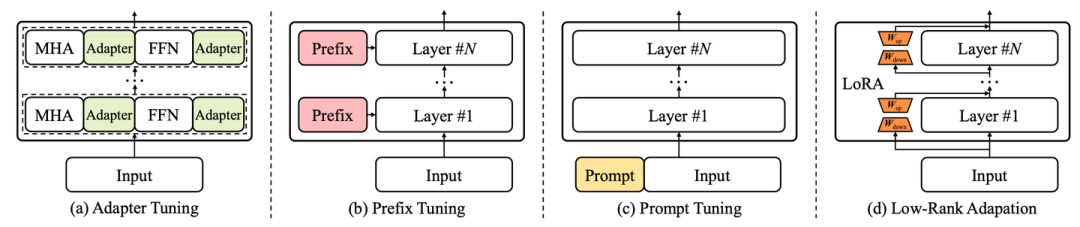
随着大语言模型的关注度日渐上升,如何更轻量地微调和使用大语言模型也成为了业界关注的热点,为此,我们新增参数高效适配章节和空间高效适配章节。在参数高效适配章节,我们介绍了常见的参数高效适配技术,包括Adapter Tuning、Prefix Tuning、Prompt Tuning、LoRA等等,并列举了近期结合这些技术在大模型上的具体实践。
同时由于大语言模型参数量巨大,在推理时需要占用大量的内存(显存),导致它们在实际应用中部署成本较高。为此,我们介绍了空间高效适配技术,讨论了如何通过模型压缩方法(模型量化)来减少大语言模型的内存占用,从而使其可以在资源有限的情况下使用。下面总结了我们讨论的一些核心结论:

6. 大语言模型使用技术
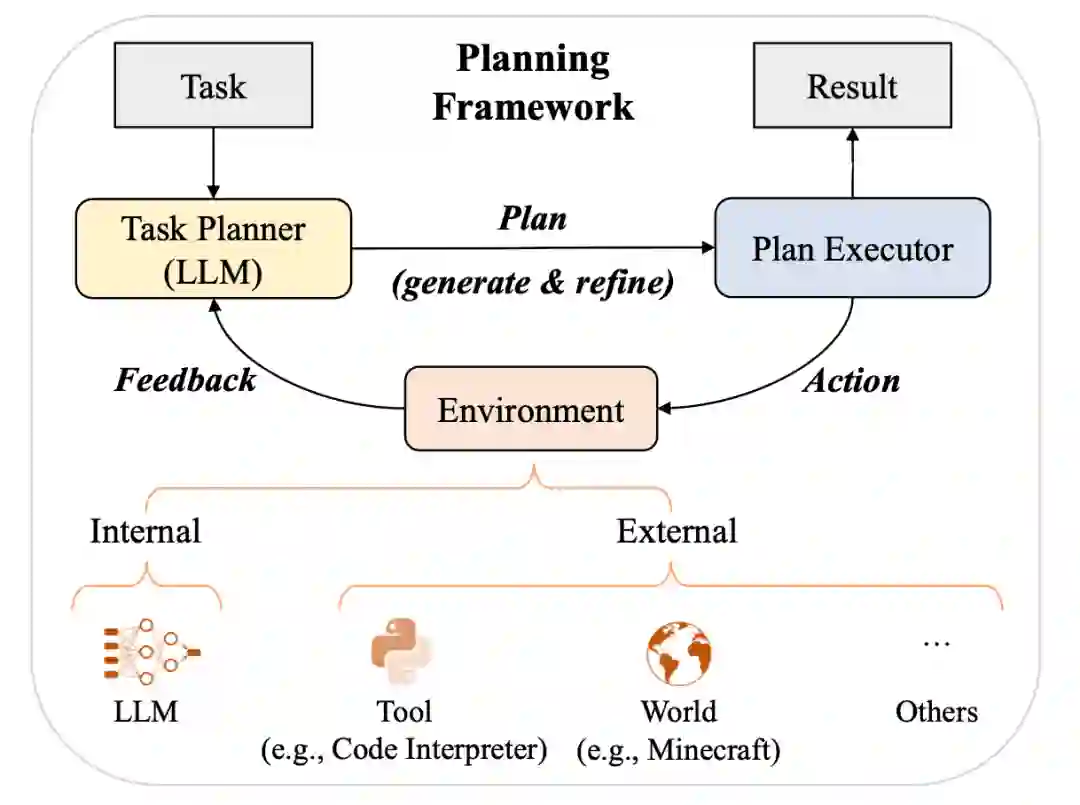
我们将大语言模型在推理阶段如何执行上下文学习的机制分析划分为两类,即任务识别和任务学习。在任务识别部分,介绍了大语言模型如何从示例中识别任务并使用预训练阶段习得的知识加以解决;在任务学习部分,介绍了大语言模型如何从示例中学习解决新任务。除了上下文学习和思维链提示,我们还介绍了另一类使用大语言模型的重要范式,即基于提示对复杂任务进行规划。根据相关工作,我们总结出了基于规划的提示的总体框架。这类范式通常包含三个组件:任务规划者、规划执行者和环境。随后,我们从规划生成,反馈获取和规划完善三个方面介绍了这一范式的基本做法。
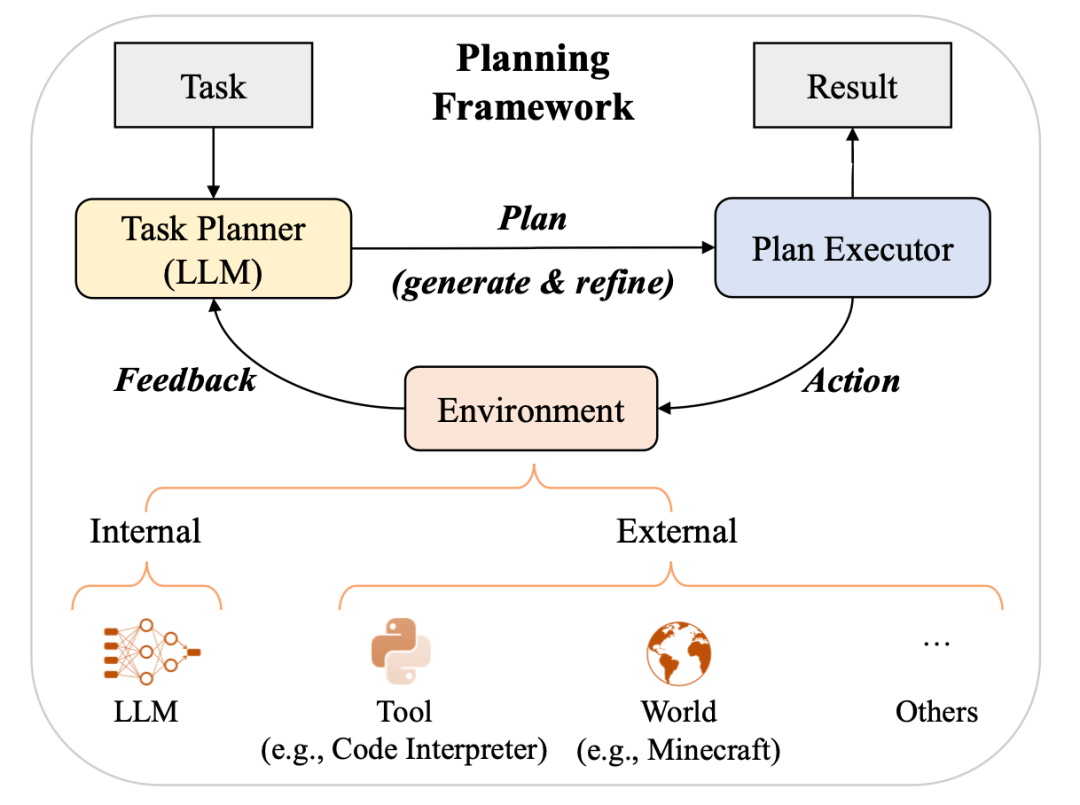
7. 大语言模型能力评估
考虑到大语言模型的条件语言生成能力日益增长,我们介绍了已有工作对大语言模型时代语言生成自动评测可靠性问题的讨论。对于大语言模型的高级能力,我们增补了最新的相关工作,并总结了大语言模型高级能力评测的常用数据集供读者参考。此外,随着大语言模型通用能力的提升,一系列工作提出了更具挑战性的基于面向人类测试的综合评测基准来评测大语言模型,我们增加了这些代表性评测基准的介绍。
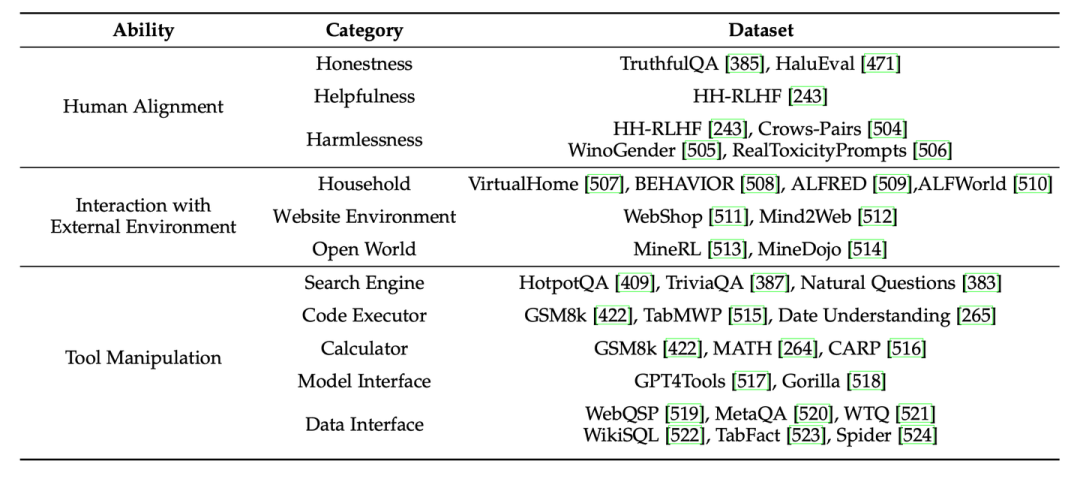
在大语言模型时代,开源和闭源的大语言模型不断涌现,我们对部分热门开源模型和闭源模型进行了细粒度的能力评测,涵盖了评测章节总结的8大基础和高级能力对应的27个代表性任务。进一步,我们对开源模型和闭源模型的评测结果进行了细致的分析。为了更好地说明大模型的现有问题,我们对于关键问题都进行了note形式的总结:

8. 大语言模型提示设计使用指南
在大语言模型时代,提示成为了人与机器交互的重要形式。然而,如何编写好的提示是一门对技巧和经验要求很高的手艺。为了让读者能够快速上手大语言模型的提示设计,我们给出了一个实用的提示设计指南。我们详细介绍了提示的关键组件,并讨论了一些关键的提示设计原则。一个完整的提示通常包含四个关键组成因素,即任务描述、输入数据、上下文信息和提示风格。为了更好的展示这些组成因素,我们给出了直观的提示样例表。

增加了相关提示的示意图:

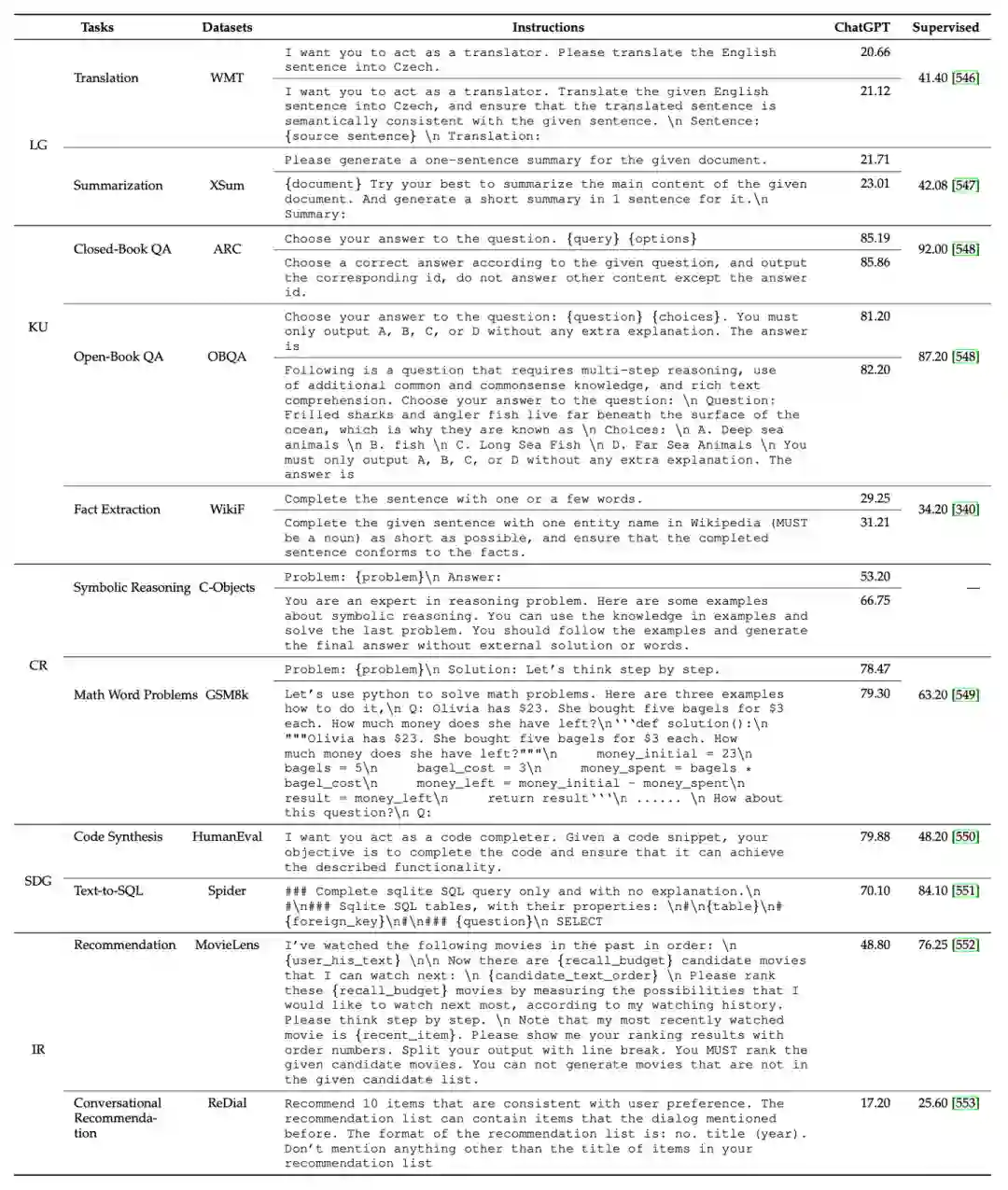
除此之外,我们还总结了一些关键的提示设计原则,包括清晰表述任务目标、将复杂任务进行分解以及使用模型友好的格式。进一步我们基于这些设计原则,展示了一系列有用的提示设计小贴士。最后,我们结合多种常见任务,基于ChatGPT具体实验了不同提示对模型性能的影响,供读者在使用提示执行具体任务时参考。
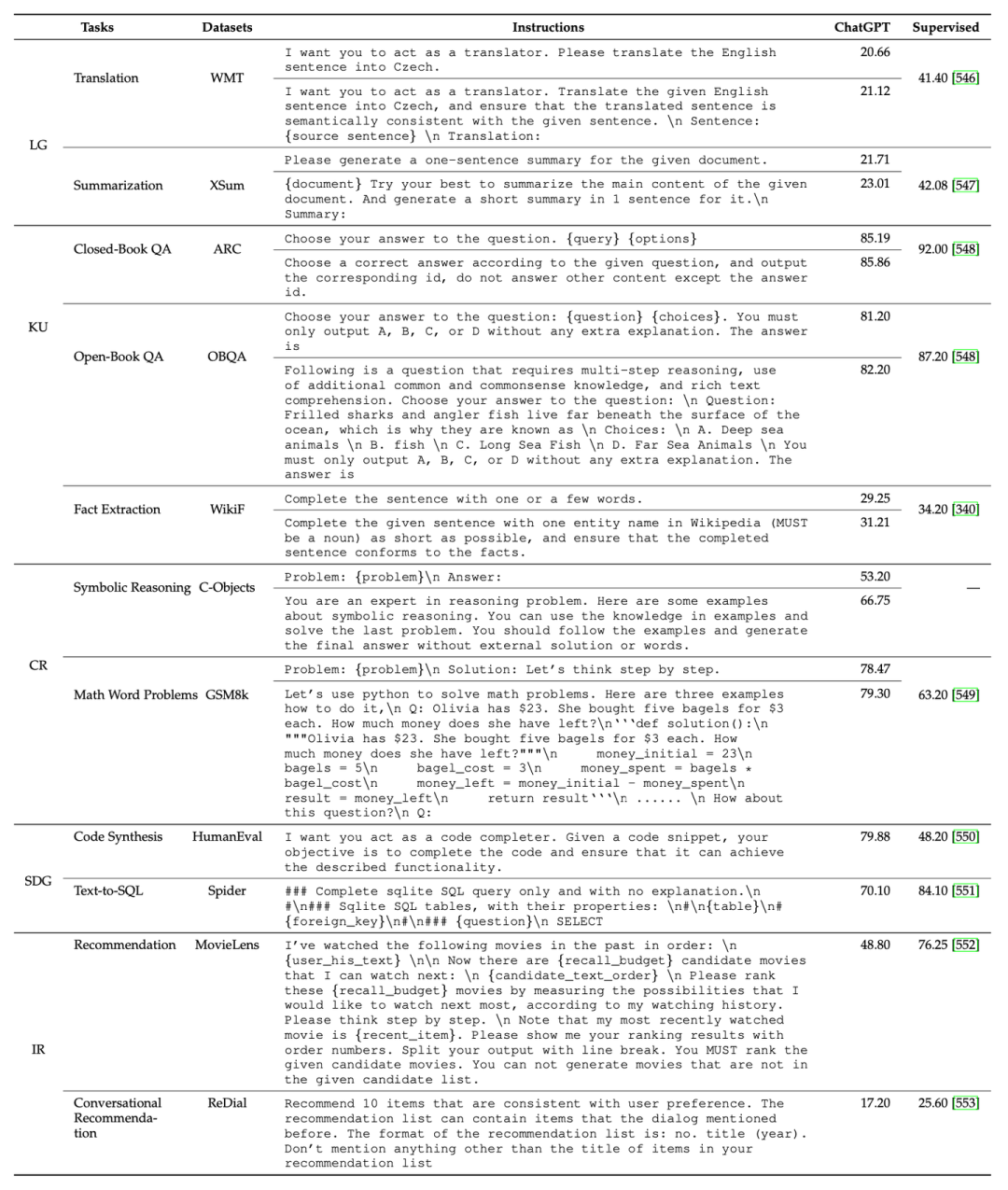
9. 大语言模型领域应用
随着大语言模型关注度的逐渐提升,研究者和工业界从业人员也尝试将大语言模型应用到各种专业领域中。为了系统地介绍这些应用实践,我们将综述中大语言模型的领域应用部分独立成了专门的章节。具体而言,我们扩充介绍了原有将大语言模型应用到医疗、教育、法律领域的相关研究,并新增了金融和科学研究领域的相关工作介绍。
10. 寻求建议与算力
一篇高质量的长篇综述文章需要大量的时间投入,所参与的老师和学生为此付出了很多的时间。尽管我们已经尽力去完善这篇综述文章,但由于能力所限,难免存在不足和错误之处,仍有很大的改进空间。我们的最终目标是使这篇综述文章成为一个“know-how”的大模型技术指南手册,**让大模型的秘密不再神秘、让技术细节不再被隐藏。**尽管我们深知目前这篇综述离这个目标的距离还比较远,我们愿意在之后的版本中竭尽全力去改进。特别地,对于预训练、指令微调、提示工程的内在原理以及实战经验等方面,我们非常欢迎读者为我们贡献想法与建议,可以通过GitHub提交PR或者邮件联系我们的作者。对于所有被采纳的技术细节,我们都将在论文的致谢部分中“实名+实际贡献”进行致谢。同时,我们自己也在围绕大模型综述的部分内容开展相关的实验探索(如能力评测、指令微调等),以保证综述中的讨论能够有据可循。由于算力所限,目前能开展的实验局限于小尺寸模型和少量比较方法。在此,我们也向社会寻求算力支持,我们将承诺所获得的算力资源将完全用于该综述文章的编写,所有使用外部算力所获得的技术经验,将完全在综述文章中对外发布。我们将在综述的致谢部分和GitHub项目主页对于算力提供商进行致谢。针对本综述文章的算力资源支持事宜,烦请致信 batmanfly@qq.com 联系我们。我们的综述文章自发布以来,收到了广泛网友的大量修改意见,在此一并表示感谢。也希望大家一如既往支持与关注我们的大模型综述文章,您们的点赞与反馈将是我们前行最大的动力。
11. 本次修订的参与学生名单
学生作者:周昆(添加了指令微调实验的任务设置与结果分析,具体安排了实验细节,添加了能力评测实验的实验设置与结果分析,协助整理code,添加了提示指南部分的实验设置与结果分析,添加了表13)、李军毅(添加了指令微调实验的数据集、改进策略和实验设置和实验表8,添加了能力评测实验的模型、任务和数据集,以及实验表11,添加了提示指南的设计原则和表12表14)、唐天一(添加第五章文字细节,添加图1、3、10,表6、7)、王晓磊(添加第六章6.1文字细节,新增6.3)、侯宇蓬(添加第四章文字细节)、闵映乾(添加第三章少数模型,LLaMA相关讨论,图4)、张北辰(添加第七章、第九章文字细节,添加表10)、董梓灿(添加图7表、4和第四章文字细节)、陈昱硕(表7实验)、陈志朋(添加第七章、第九章文字细节,表11实验)、蒋锦昊(更新图8)学生志愿者:成晓雪(表11实验)、王禹淏(表11实验)、郑博文(表11实验)、胡译文(中文校对)、侯新铭(中文校对)、尹彦彬(中文校对)、曹展硕(中文校对)
附件:更新日志
版本时间主要更新内容V12023年3月31日初始版本V22023年4月9日添加了机构信息。修订了图表 1 和表格 1,并澄清了大语言模型的相应选择标准。改进了写作。纠正了一些小错误。V32023年4月11日修正了关于库资源的错误V42023年4月12日修订了图1 和表格 1,并澄清了一些大语言模型的发布日期V52023年4月16日添加了关于 GPT 系列模型技术发展的章节V62023年4月24日在表格 1 和图表 1 中添加了一些新模型。添加了关于扩展法则的讨论。为涌现能力的模型尺寸添加了一些解释(第 2.1 节)。在图 4 中添加了用于不同架构的注意力模式的插图。在表格 4 中添加了详细的公式。V72023年4月25日修正了图表和表格中的一些拷贝错误V82023年4月27日在第 5.3 节中添加了参数高效适配章节V92023年4月28日修订了第 5.3 节V102023年5 月7 日修订了表格 1、表格 2 和一些细节V112023年6月29日第一章:添加了图1,在arXiv上发布的大语言论文趋势图;第二章:添加图3以展示GPT的演变及相应的讨论;第三章:添加图4以展示LLaMA家族及相应的讨论;第五章:在5.1.1节中添加有关指令调整合成数据方式的最新讨论, 在5.1.4节中添加有关指令调整的经验分析, 在5.3节中添加有关参数高效适配的讨论, 在5.4节中添加有关空间高效适配的讨论;第六章:在6.1.3节中添加有关ICL的底层机制的最新讨论,在6.3节中添加有关复杂任务解决规划的讨论;第七章:在7.2节中添加用于评估LLM高级能力的代表性数据集的表格10,在7.3.2节中添加大语言模型综合能力pint测;第八章:添加提示设计;第九章:添加关于大语言模型在金融和科学研究领域应用的讨论。
更多推荐