复旦大学:利用场景图针对图像序列进行故事生成 | AAAI 2020

作者 | 王瑞泽
编辑 | Tokai
本文介绍了复旦大学研究团队在AAAI 2020上录用的一篇关于多模态文本生成工作: 《Storytelling from an Image Stream Using Scene Graphs》,利用场景图针对图像序列进行故事生成。
该文章认为将图像转为图结构的表示方法(如场景图),然后通过图网络在图像内和跨图像两个层面上进行关系推理,有助于表示图像,并最终有利于描述图像。实验结果证明该方法可以显著的提高故事生成的质量。

论文链接: http://www.sdspeople.fudan.edu.cn/zywei/paper/2020/wang-aaai-2020.pdf
对于大多数人,观察一组图像然后写一个语义通顺的故事是很简单的事情。尽管近年来深度神经网络的研究取得了令人鼓舞的成果,但对于机器来说,这仍然是一件困难的事情。
近年来,视觉叙事(visual storytelling)越来越受到计算机视觉(CV)和自然语言处理(NLP)领域的关注。不同于图像标注(image captioning)旨在为单个图像生成文字描述,视觉叙事任务则更具挑战性,它进一步研究了机器如何理解一个图像序列,并生成连贯故事的能力。
目前的视觉叙事方法都采用了编码器-解码器结构,使用通过一个基于CNN的模型提取视觉特征,使用基于RNN的模型进行文本生成。其中有些方法引入了强化学习和对抗学习等方法,来产生更加通顺、有表现性的故事。但是仅使用CNN提取到的特征来表示所有的视觉信息,这不大符合直觉而且损害了模型的可解释性和推理能力。
回想一下人是如何看图写故事的呢?人会先分辨出图像上面有什么物体,推理他们的关系,接下来把一个图像抽象成一个场景,然后依次看观察图像,推理图像间的关系。对于视觉叙事这个任务,本文认为也可以采用类似方法。
本文认为把图像转为一种图结构的表示(如场景图),随后在图像内(within-image)和跨图像(cross-image)这两个层面上建模视觉关系,将会有助于表示图像,并最终对描述图片有所帮助。
一、方法描述
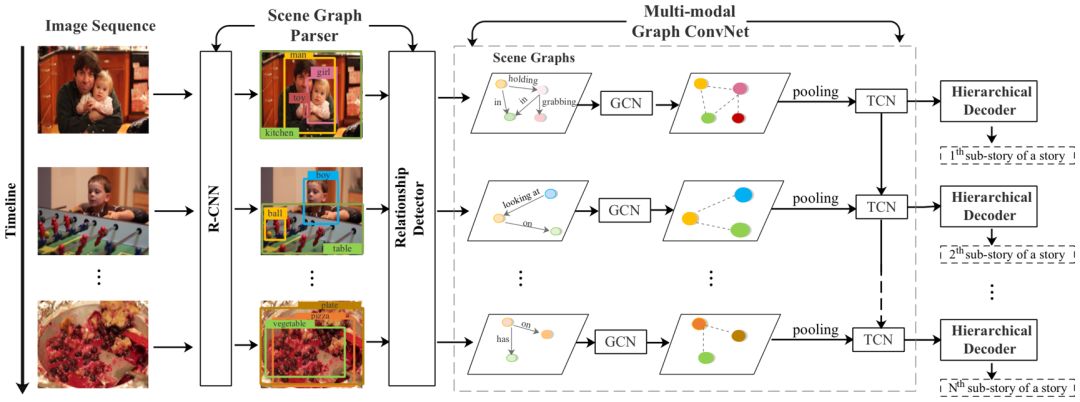
本文提出了一种基于图网络的模型SGVST (如图2所示),它可以在图像内和跨图像这两个层面上建模视觉关系。
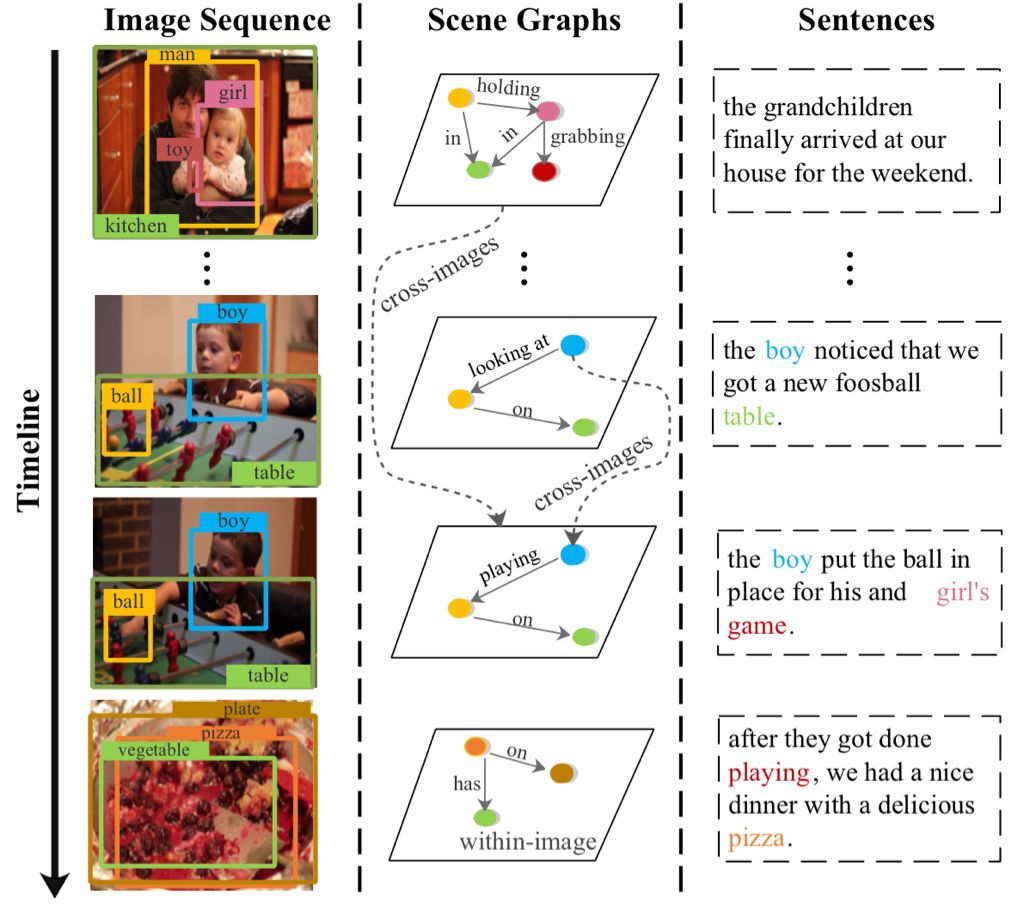
简单来说,首先将图像In通过Scene Graph Parser转化为场景图Gn=(Vn, En)。场景图包含了检测到的物体Vn={vn,1,…,vn,k},以及物体之间的视觉关系En。
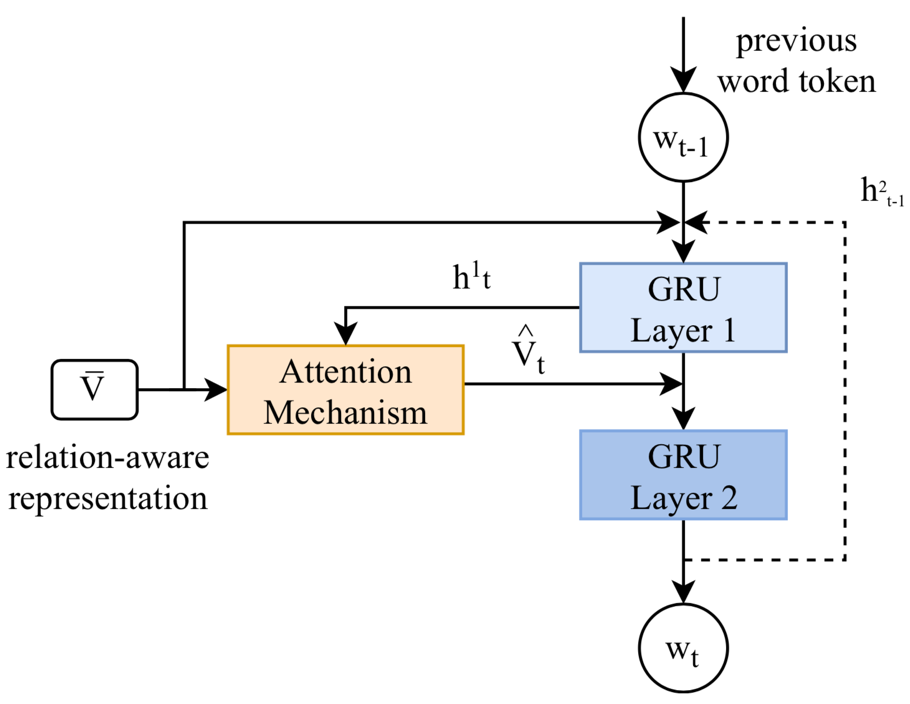
如图2所示,一个男人抱着一个孩子,那么男人和孩子就可以作为图中的节点,他们的视觉关系作为边。接着将场景图通过Multi-modal Graph ConvNet:在图像内的层面,使用图卷积神经网络(GCN)来对场景图中的节点特征进行增强。在跨图像层面,为了建模图像之间的交互,使用时序卷积神经网络(TCN)来沿着时间维度进行卷积,进一步优化图像的特征表示。最后得到了集合了图像内关系和跨图像关系的relation aware的特征,输入到层次化解码器(Hierarchical Decoder)中来生成故事。
二、实验结果
1. 定量分析
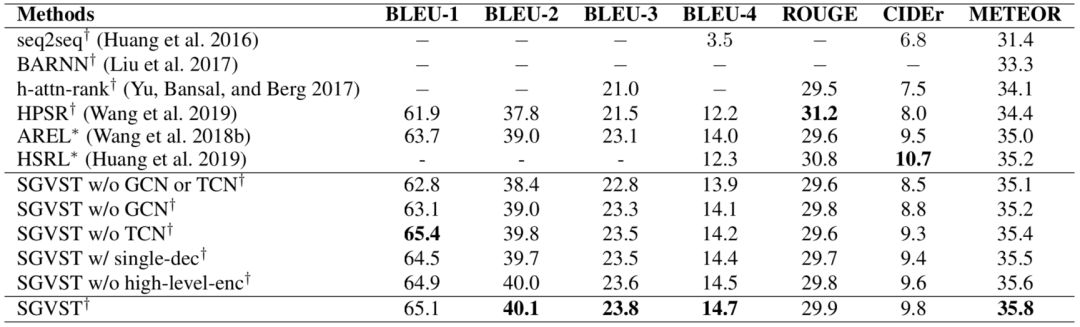

表1显示了不同模型在七个自动评价指标上的性能。结果显示作者提出的SGVST模型几乎在所有指标上都优于其他用MLE和RL优化的模型具有更好的性能,SGVST的BLEU-1、BLEU-4和METEOR得分比其他基于MLE优化的最佳方法分别提高了3.2%、2.5%和1.4%,这被认为是在VIST数据集上的显著进步。这直接说明将图像转换为基于图的语义表示(如场景图),有利于图像的表示和高质量的故事生成。
本文还进行了消融实验,和提出模型的5个变种模型进行了比较,来验证模型每个模块部分的重要性。从表1中可以看在不使用GCN和TCN的时候,模型性能有一个很大的下降。这说明图网络在该模型中是最为重要的,因为它可以给模型带来了推理视觉关系的能力。
2. 定性分析
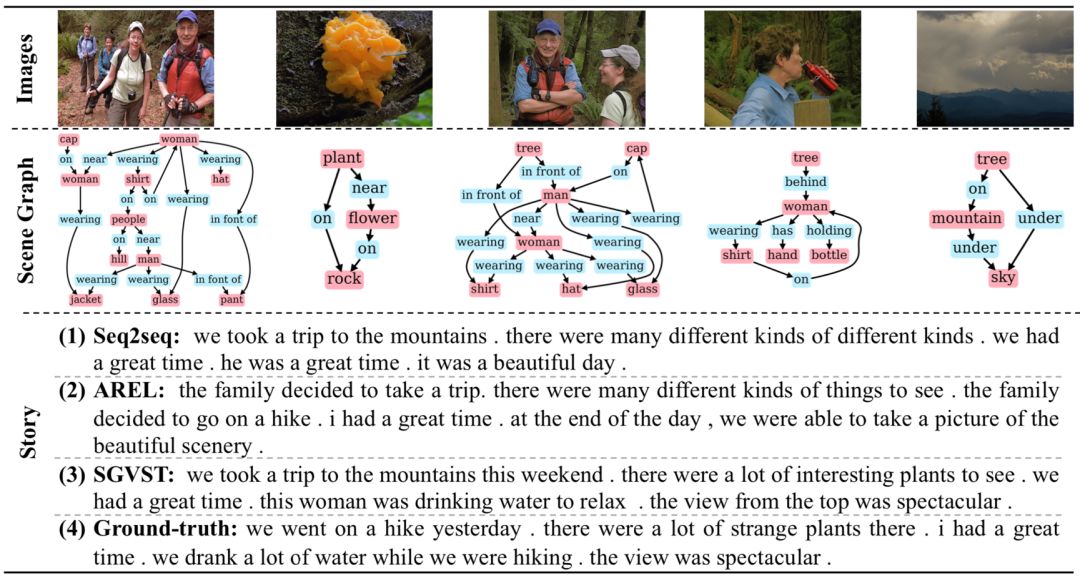
图4:不同模型定性分析的例子.
图4展示了3种不同模型生成的故事和真实故事的样例。第一行是输入的一个图像序列。第二行是生成出的场景图。第三行是不同模型生成的故事。可以看出SGVST生成的故事更通顺,而且信息更丰富、更有表现力。
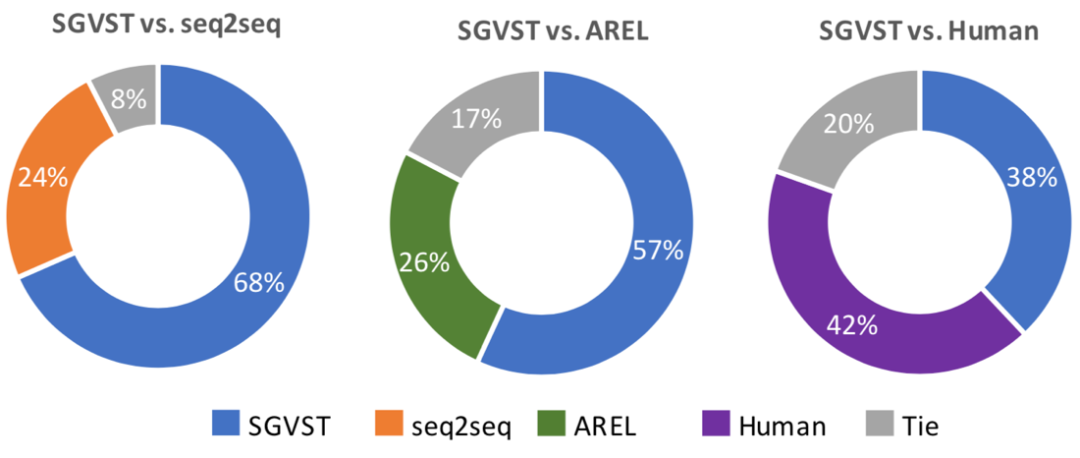
图5:每种颜色代表了相对应模型产生的故事,被评价人员认为更加像人写的、更有表现力所占的比例。灰色的”Tie”代表了打平.

表2:人工评估结果。在AMT上的评估人员根据对每个问题的同意程度来评价故事的质量,评分范围为1-5.
为了更好地评价生成的故事的质量,作者通过Amazon Mechanical Turk(AMT)进行了两种人工评价。(1)图5是不同模型两两比较的一个实验结果,给评价人员2个生成出的故事,然后让他来选择哪一个写的更好。(2)表2是在6个指标上进行的人工评估实验结果。可以看出本文提出的模型和其他模型相比有着巨大的优势,而且和人类相比,也取得了有竞争力的表现。
四、总结
1. 将图像转为图结构的语义表示(如场景图),可以更好的表示图像,有利于高质量的故事生成。
2. 本文提出了一个基于图网络的模型,可以将图像转为场景图,然后在图像内和跨图像两个层面上进行关系推理。
3. 实验结果表明,本文提出的模型取得了优秀的表现,并且能产生信息更加丰富、语言更加连贯的故事。
4. 场景图生成的质量限制了本文模型的性能,如果能有更好的场景图生成方法,本文模型的性能还能取得进一步提高。
AAAI 论文解读系列: