编辑 | 萝卜皮
蛋白质设计对于医学和生物技术应用变得越来越重要。由于蛋白质形成的复杂机制,新蛋白质的产生需要繁琐且耗时的计算或实验协议。同时,机器学习通过利用大量可用数据来解决复杂问题,最近在生成建模领域有了很大的改进。然而,生成模型主要应用于蛋白质设计的特定子问题。
谷歌的研究人员
解决了以分层基因本体的功能标签为条件的通用蛋白质设计问题。
由于缺少在该领域评估生成模型的规范方法,他们设计了一个评估方案,其中包含几个生物学和统计学启发的指标。
然后,该团队
开发了条件生成对抗网络 ProteoGAN,并表明它在蛋白质序列生成方面优于几个经典和最近的深度学习基线。
研究人员估计,功能条件模型可以通过组合标签来生成具有新功能的蛋白质,并为这一研究方向迈出第一步。
该研究以「Conditional generative modeling for de novo protein design with hierarchical functions」为题,于 2022 年 7 月 1 日刊载在《Bioinformatics》。
设计具有目标生物功能的新蛋白质是生物技术中的一项常见任务,并且在合成生物学和药物研究(例如药物发现)中具有广泛的应用。这项任务具有挑战性,因为蛋白质的序列-结构-功能关系极其复杂,尚未完全了解。
因此,蛋白质设计主要通过试错法完成,例如定向进化,它依赖于已知蛋白质的一些随机突变和选择压力来探索相关蛋白质的空间。这个过程既费时又费钱,而且通常只探索一小部分序列空间。同时,表征蛋白质及其功能的数据很容易获得,并为机器学习在蛋白质序列设计中的应用提供了有希望的机会。
最近提出了多种生成模型来设计用于不同任务的蛋白质,例如开发新疗法、酶、纳米抗体序列或导致抗生素耐药性的蛋白质。这些模型通常专注于蛋白质设计的子任务,因此仅限于给定的应用,通常甚至仅限于特定的蛋白质家族。这需要对一项新任务进行重新训练,这限制了模型可以从中学习的序列的多样性和数量。
在其他领域,例如密切相关的自然语言生成,人们可以观察到通用模型的趋势,然后在各种上下文中使用这些模型。谷歌团队的研究人员假设,同样在蛋白质设计中,一刀切的模型可以学习不同蛋白质类别的共同基本原理,从而提高生成序列的质量。
更进一步,它甚至可以通过结合它在不同蛋白质家族中学到的功能的不同方面来创造不仅新的序列,而且还可以创造新的功能。因此,该团队开发了 ProteoGAN,这是一种用于条件蛋白质设计的通用生成模型,基于分子功能基因本体论(the Molecular Function Gene Ontology,GO),一种描述蛋白质功能方面的标签层次结构。这些功能从结合特异性试剂到转运蛋白或传感器活性、生化反应催化等等不一而足。
此外,分层组织中编码的信息可能有助于对性能进行建模。他们的模型基于流行的生成对抗网络(GAN)框架。研究人员通过提出一种条件机制来扩展框架,将蛋白质功能的多标签层次信息纳入生成过程。
然而,开发这样的生成模型可能具有挑战性,尤其是因为缺乏针对问题的评估。评估指标需要评估生成的样本是否有效(即现实性和功能性),这本身就是一个难题,还需要快速计算大量样本。生成模型的评估仍在进行中,特别是在蛋白质设计领域。
虽然生成序列的金标准验证意味着在实验室中合成蛋白质,但缺乏计算机评估使得难以有效地比较蛋白质序列设计的方法。因此,该团队基于最大平均差异 (MMD) 统计量为生成蛋白质设计构建了一系列评估指标,以测量生成序列与真实蛋白质的分布相似性和条件一致性。同时,进一步提出了解释序列多样性的措施。
机器学习模型和最近的深度生成模型已被用于设计计算机生物序列,例如 RNA、DNA 或蛋白质序列,通常旨在创建具有所需特性的序列。实现这一目标有两种主要策略,一种是有指导的,另一种是有条件的。引导式方法使用预测器(也称为预言机)通过迭代的训练-生成-预测步骤来引导设计朝着目标属性发展。
然而,在具有多个功能标签的情况下,缺乏用于蛋白质功能的高度准确和快速的多标签预测器会损害功能性蛋白质生成中的引导生成技术。另一方面,条件方法将功能信息集成到生成机制本身中,从而无需预测器。
例如,2020 年 Madani 团队开发了 ProGen,这是一种条件转换器,可以控制生成大量功能性蛋白质,但对序列上下文的需求可能会受到实验限制,并且与从头设计不兼容。2019 年 Ingraham 团队提出了一种基于图的条件生成模型,该模型依赖于结构信息,而这种信息很少可用。2018 年 Das 团队和 Greener 团队训练条件变分自动编码器(CVAE)以生成特定蛋白质,例如金属蛋白。2020 年 Karimi 团队使用引导条件 Wasserstein-GAN 生成具有新折叠的蛋白质。
所有这些模型要么只关注蛋白质设计的子任务,要么依赖于上下文信息,例如 3D 结构或模板序列片段。而谷歌团队所提出的 ProteoGAN,是一种用于蛋白质设计的通用模型,该模型只需要指定生成所需的功能特性。
迄今为止,对于评估(条件)生成模型输出的质量、多样性和条件一致性的最佳评估措施,还没有明确的共识。大多数在计算机视觉中脱颖而出的指标,例如初始分数、Frechet 初始距离(FID)或 GAN 训练和 GAN 测试,都依赖于外部的、特定于领域的预测器。
对于功能性蛋白质设计,这样的预测器在评估和训练神经网络时既不够好也不够快,无法完全依赖它们的预测。功能注释的关键评估 (CAFA) 挑战报告了当前最佳模型(NetGO),其 F
max
得分为 0.63,其预测速度约为每小时 1000 个序列。相反,域无关对偶间隙可以在训练和测试时计算,并且已被证明与 FID 有很好的相关性。
在自然语言建模中,困惑度是一种常见的评估指标,与模型下测试集的概率有关。然而,这需要访问在某些模型中不可用的可能性,例如 GAN,并且并不总是样本质量的良好指标。另一种方法测量可以从不完整的序列中恢复多少野生型残基,然而,这与从头蛋白质设计的想法背道而驰。
尽管研究界对蛋白质生成模型的兴趣日益浓厚,但还没有明确的指标可以作为比较它们的可靠工具。
指标的元评估:Spectrum MMD 是蛋白质设计的有效指标
不同的嵌入捕获原始数据的不同方面。该团队感兴趣的是相对简单的 Spectrum 内核嵌入是否足以评估分布相似性和条件一致性,因此将其与三个生物学基础的嵌入进行了比较:ProFET,主要与单个氨基酸或序列基序的生物物理特性相关的序列特征的手工选择,UniRep,基于 LSTM 的学习嵌入和 ESM,基于 Transformer 的学习嵌入。后两者被证明可以恢复蛋白质的各个方面,包括结构和功能特性以及进化背景。
在这个比较中,ESM 嵌入可以说是最强大的,并且有望获得最好的分数。值得注意的是,Spectrum 内核嵌入也非常适合评估蛋白质的结构和功能方面,同时计算速度快几个数量级,并且需要更少的计算资源。这使得它更适合神经网络和其他模型的评估或超参数优化过程中对性能的要求。
选择 Spectrum 内核嵌入的另一个原因是它的简单性,因为它不对数据分布做任何假设:学习到的嵌入 UniRep 和 ESM 是在大量自然序列上训练的复杂非线性映射,虽然它们在自然分布数据上表现出色,但它们在生成序列上的行为仍然不可预测。
超参数分析:ProteoGAN 的条件判别器对其性能最为关键
研究人员测试了 cGAN 的各种超参数和架构选择,并在 fANOVA 框架(functional ANOVA framework)中对蛋白质设计性能指标 MMD 和 MRR 进行了分析。为了为这些模型的后续工作提供信息,研究人员可以根据经验得出一些专门用于蛋白质设计的 GAN 设计原则。
首先,较小的架构比具有四个以上隐藏层的网络表现得更好。这个大小似乎足以对蛋白质进行建模,尽管优化当然会对快速收敛(小)模型产生选择压力。判别器达到最优解,比通过较大的学习率经常找到的局部最优,更重要。
研究人员观察到分布相似性和条件一致性之间的权衡。这表现在增加 MRR 和降低 MMD 性能时,当权衡更强的 AC 的训练损失项时,以及在不同的调节机制之间切换时。
仅使用序列作为输入,而不是将生物物理特征向量附加到序列嵌入中,可以获得最佳性能。氨基酸同一性,而不是其特性,似乎对序列建模更为关键。
研究人员发现,在比较捕获标签之间的层次关系的不同标签嵌入时,标签的简单 one-hot 编码显示出最佳结果。对于模型,离散的 one-hot 标签嵌入似乎比连续的 node2vec 嵌入或双曲 Poincaré 嵌入更容易解释。虽然这些嵌入包含更多信息,但 one-hot 编码以更易于访问的形式呈现它们。此外,对于神经网络需要首先学习的许多基本概念,双曲空间需要特殊的算子。
GAN 框架的其他流行扩展,例如输入噪声、标签平滑或训练比率在上下文中没有显著影响模型性能。总而言之,一个具有调节机制且没有进一步序列或标签增强的小型模型效果最好。对架构的进一步改进应该集中在改进鉴别器上,因为影响它的超参数显示出最大的影响。
他们的最终模型 ProteoGAN 是优化性能最好的模型,具有多个投影、一个 AC、没有生物物理特征和标签信息的单热编码。
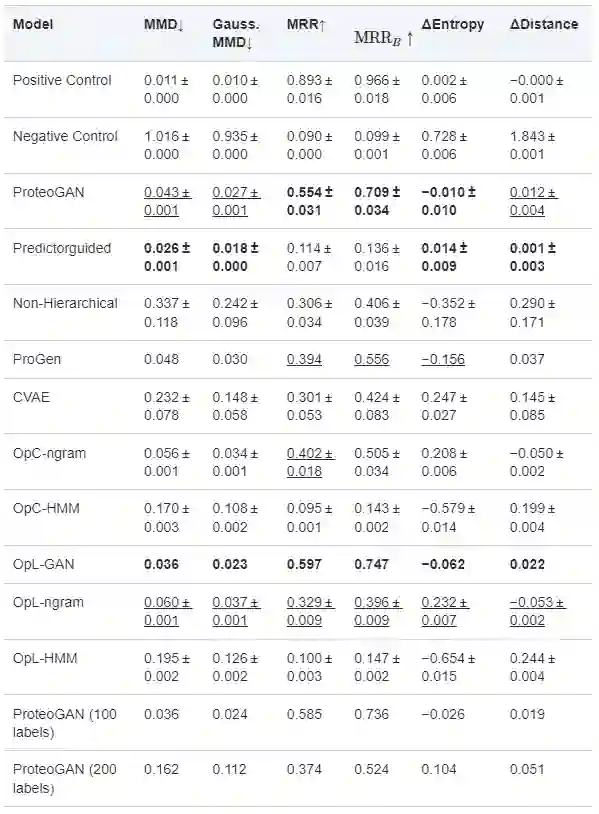
根据提出的分布相似性、条件一致性和多样性指标,研究人员评估 ProteoGAN 的性能,并将其与几个基线进行比较。通过对生物嵌入 ProFET、UniRep 和 ESM 以及嵌入的特征 KS 统计量的评估来巩固结果。
图示:基于 Spectrum 内核嵌入,使用 MMD、MRR 和多样性指标评估 ProteoGAN 和各种基线。(来源:论文)
结果表明,ProteoGAN 在所有指标和嵌入上都明显优于 HMM、n-gram 模型和 CVAE。这同样适用于 OpL 版本,每个标签训练一次。ProteoGAN 的性能也优于最先进的 ProGen 模型。
MMD 值相似,ProGen 可能会比 ProteoGAN 更好地扩展;然而,MRR 显示了 ProteoGAN 在条件生成方面的明显优势。
适用性:ProteoGAN可以支持更大序列空间的蛋白质筛选
没有湿实验室验证,很难证明生物学有效性,后续可能会进行验证。研究人员承认,MMD 值仍然与阳性对照有显著差异,并且相应的 P 值在这方面尚无定论。因此,生成的序列很可能不是开箱即用的,而是需要一些实验性调整,如定向进化。
目前,ProteoGAN 的主要应用:用比以前可能的距离已知序列空间更远的候选者进行蛋白质筛选的扩展,但比其他方法的相对新颖的候选者更可能具有功能。
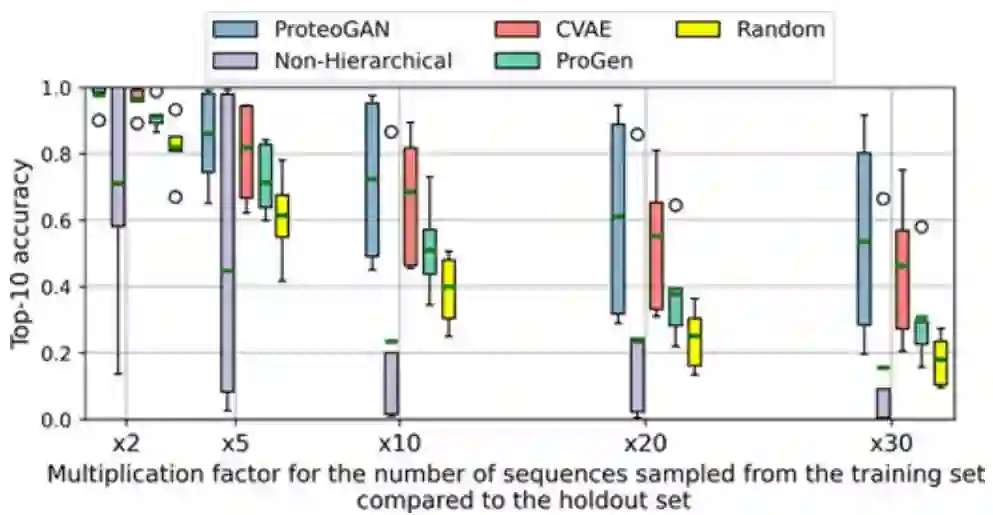
作为一个有趣的前景,该团队提供了关于 OOD 生成的初步评估。以多个标签为条件的模型通常旨在模拟给定标签的蛋白质的联合分布,即执行所有指定功能的蛋白质。因此,研究人员假设条件机制可用于将以前不相关的功能标记组合成一种蛋白质,这将能够设计出具有以前看不见的功能的全新类型的蛋白质。
研究人员强调这个目标没有明确地建立在条件机制中,因此它不适合优化冲突属性。但是,正交属性的组合可能是允许的。虽然同样在这里,生物实施是不可避免的来证明这一概念,但研究人员可以报告 ProteoGAN 和 CVAE 在五个保留标签组合上显示出有希望的 Top-X 精度。这一概念的进一步发展将为生物技术提供新的工具。
图示:具有 OOD 功能的模型的频谱嵌入 top10 准确度。(来源:论文)
代码和数据:https://github.com/timkucera/proteogan
论文链接:https://academic.oup.com/bioinformatics/article/38/13/3454/6593486?login=true
人工智能 × [ 生物 神经科学 数学 物理 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。