
蛋白质是生命的通用组成部分,几乎在每个细胞过程中都发挥至关重要的作用。为特定目的设计新型蛋白质的能力有助于解决许多医疗挑战。 2022年6月22日,来自西班牙赫罗纳大学信息学与应用研究所的Noelia Ferruz等人在Nat Mach Intel杂志发表文章,讨论了人工智能领域的最新进展--语言模型在蛋白质设计中的潜力和影响。

蛋白质序列在本质上类似于自然语言:氨基酸以多种组合方式排列,形成承载功能的结构,就像字母组成单词和句子承载意义一样。因此自然语言处理(NLP)的许多技术被应用于蛋白质研究问题。
过去几年里,NLP领域有了革命性的突破。Transformer预训练模型的实施使文本生成具有类似人类的能力。我们预计专用Transformer将会在不久的将来主导定制的蛋白质序列的生成。 对蛋白质家族的预训练模型进行微调,将使他们能够使用可能高度不同但仍具有潜在功能的新序列来扩展它们的库。细胞区室或功能等控制标签的组合将进一步实现新蛋白质功能的可控设计。此外,最近的模型可解释性方法将使我们能够打开”黑盒子",从而增强我们对折叠原理的理解。 早期的研究显示了生成性语言模型在设计功能序列方面的巨大潜力。我们认为,使用生成性文本模型来创造新的蛋白质是一个很有前途的、在很大程度上未被开发的领域,本文讨论了它对蛋白质设计可预见的影响。
主要内容 蛋白质设计的目的是创造出能发挥所需功能的定制结构。这一巨大的挑战通常被称为逆向蛋白质折叠问题:我们的目标不是寻找一个序列折叠的结构,而是获得一个采用某种折叠的最佳序列。在数学上,这个问题是通过搜索由能量函数定义的序列-结构的全局最小值的优化算法来解决的。 尽管最广泛使用的能量函数相对简单,但每个位置的旋转异构体和可能的组合的数量带来了组合的爆炸。由于这种复杂性,新蛋白质的设计通常需要相当长的时间和精力,而且绝大多数的功能性蛋白质设计都是通过预先选择天然存在的骨架、并随后在迭代中优化其功能而实现的,而不是同时设计序列和结构以执行某种功能。 蛋白质最不寻常的特性之一,是它们在氨基酸序列中完全编码了其结构和功能,并且它们以极高的效率做到这一点。在没有生物物理约束的情况下,仅靠序列就能捕捉到蛋白质的特性,这为利用自然语言处理(NLP)方法进行蛋白质研究打开了一扇未被开发的大门。下文总结了自然语言和蛋白质序列之间的异同,并展示了NLP研究已经如何影响了蛋白质科学。**我们将强调该领域中最引人注目的发展,即Transformer架构。**随后的章节将介绍Transformer的独特生成能力是如何重塑蛋白质设计领域的。 我们希望本文能触及人工智能和生物学领域,并鼓励进一步合作,开发和调整NLP技术用于蛋白质设计。 蛋白质的语言 有几个特征证明了人类语言和蛋白质序列之间的相似性,其中最明显的可能是它们的分层组织。与人类语言类似,蛋白质是由字符串的连接表示的:20个标准氨基酸。然后字母组合成单词,氨基酸组合成二级结构或保守的蛋白质片段。然后,就像单词组合成带有意义的句子一样,片段可以组合成带有功能的不同蛋白质结构(图1a)。
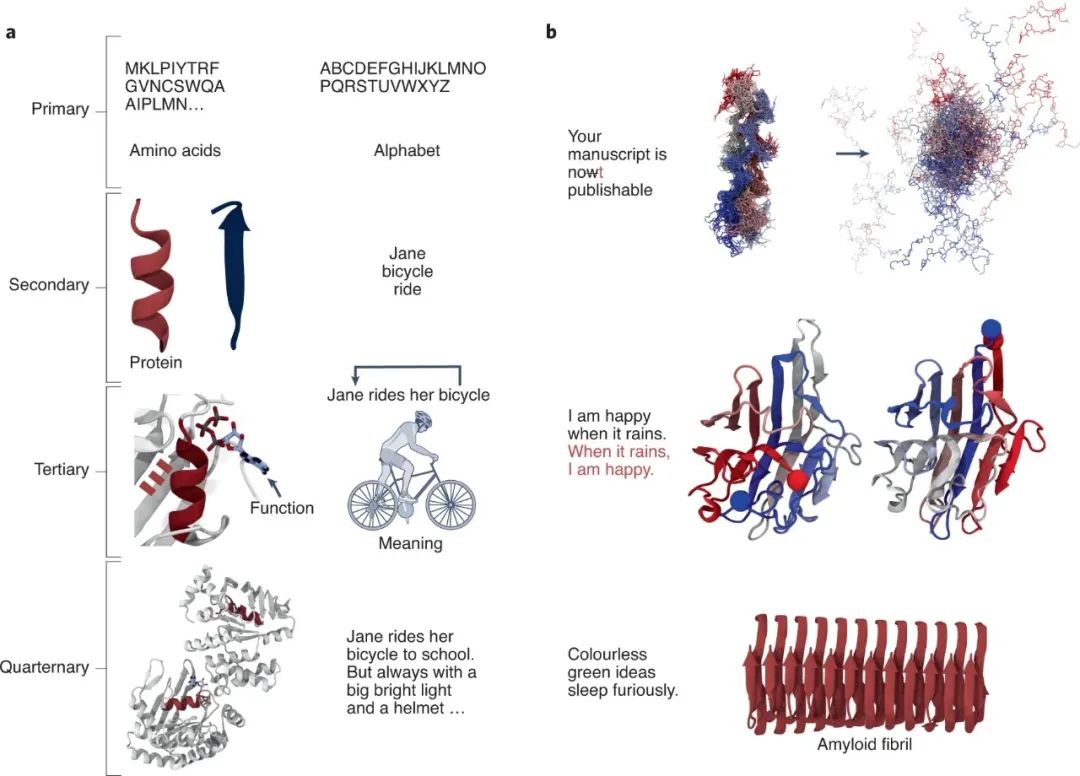
图1:蛋白质和语言之间的相似性 **语言和蛋白质的起源和演变也显示出相似之处。**今天,有超过8000种语言,分为140多个语系,所有这些语言都起源于5万至7万年前在非洲中部使用的一种共同祖先语言。同样,所有生活在地球上的生物都有一个(最后的普遍)共同祖先--LUCA--一种生活在40亿年前的微生物,它已经包含了大多数现代蛋白质结构域,这些结构域通过进化而发展。
然而,必须注意的是,蛋白质和人类语言也存在差异,这对将NLP应用于蛋白质研究构成了挑战。
首先,许多人类语言在书面文本中提供了清晰可辨的词汇定义(中文是一个突出的例外),但在蛋白质中,"词的边界”却不那么明显。 其次,目前对蛋白质语言缺乏了解,类似于我们目前对许多已灭绝的语言缺乏了解。尽管我们有训练蛋白质语言的语料库,但对生成的序列的正确解释仍将是一个挑战,需要广泛的实验测试来破译其功能。 再者,蛋白质的进化也明显不同于语言的进化,它受到随机性和环境压力的影响,而且其语法不可避免地会包含许多不规则的地方。 总的来说,人类语言和蛋白质序列之间的不相似性给NLP在蛋白质设计中的应用带来了巨大的挑战。然而,尽管有这些挑战,这两个领域之间的明显联系为蛋白质研究领域提供了一个新的视角。
NLP对蛋白质研究的数十年影响 虽然不明显,但NLP领域一直影响着蛋白质研究。图2a总结了这两个领域之间的相似之处。
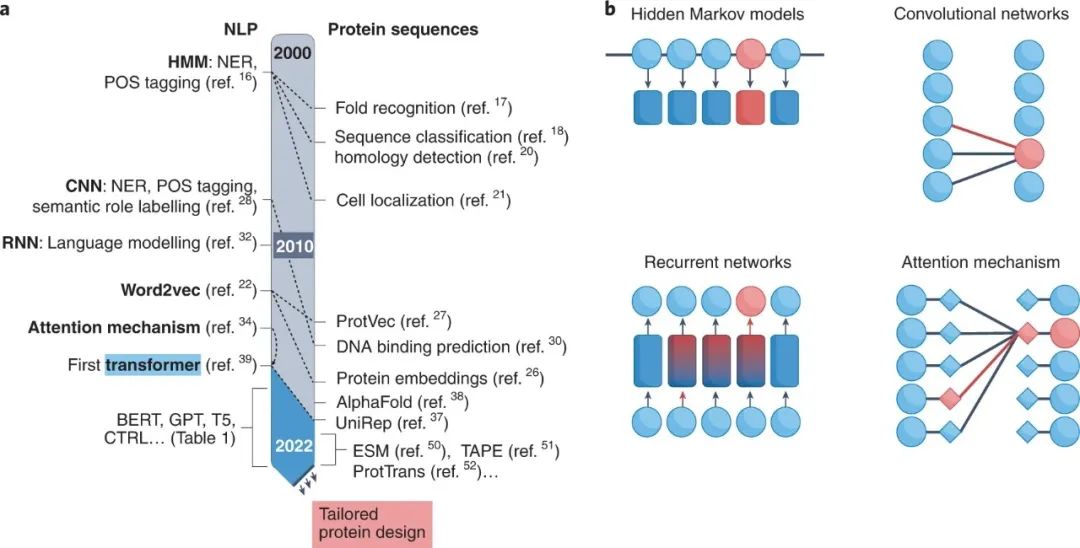
图2:最常用于NLP问题的方法概述 CNN的适用性很快就扩展到了蛋白质研究,以预测蛋白质的紊乱、DNA结合位点和折叠分类。然而,CNN未能对长距离信息进行建模,而长距离信息对于全局文本的理解是至关重要的。由于这个原因,NLP研究人员转向了循环神经网络(RNN),特别是长短期记忆(LSTM)。
**传统的LSTM很快被注意力机制****所取代,这影响了最近在蛋白质研究方面的突破,如AlphaFold。**在注意力模型的基础上,谷歌发布了Transformer,以更低的计算成本改善了大多数NLP任务的结果。第一个Transformer开启了NLP的新时代,从那时起,无数的改造被实施(图2a)。 值得一提的是生成式预训练Transformer(GPT)及其后续的GPT-2和GPT-3。这些预训练的模型在大多数NLP任务中都表现出了卓越的性能,并且第一次能够生成类似人类的、长的、连贯的文章。NLP领域的这些最新发展具有很大的潜力,可以适用于蛋白质研究。以下各节将对预训练的语言模型如何在未来几年内改变和主导蛋白质设计提供见解。 注意力机制和Transformer Transformer是当前NLP的一场革命。他们的成功来自于一系列建立在彼此之上的概念的演变,其中注意力机制可能是这些进展中最值得注意的。 注意力机制起源于对传统的序列到序列(seq2seq)模型的解决方案,该模型被广泛用于处理从一个领域到另一个领域的序列的任务,如机器翻译或文本总结。在seq2seq模型中,输入在一个被称为编码器的模块中被逐步处理,以产生一个传递给解码器的上下文向量,解码器负责生成一个输出(图3a)。传统上,编码器和解码器的架构通常是RNNs或LSTMs(图2b),上下文向量对应于最后一个编码器步骤的最终输出(图2b)。由于这种固有的顺序性,RNNs出现了性能下降和训练时间随序列长度增加的主要缺点。注意力机制的引入为这一问题提供了一个解决方案,它允许解码器分析整个输入并关注其中的特定部分,这一概念类似于人类头脑中的注意力。
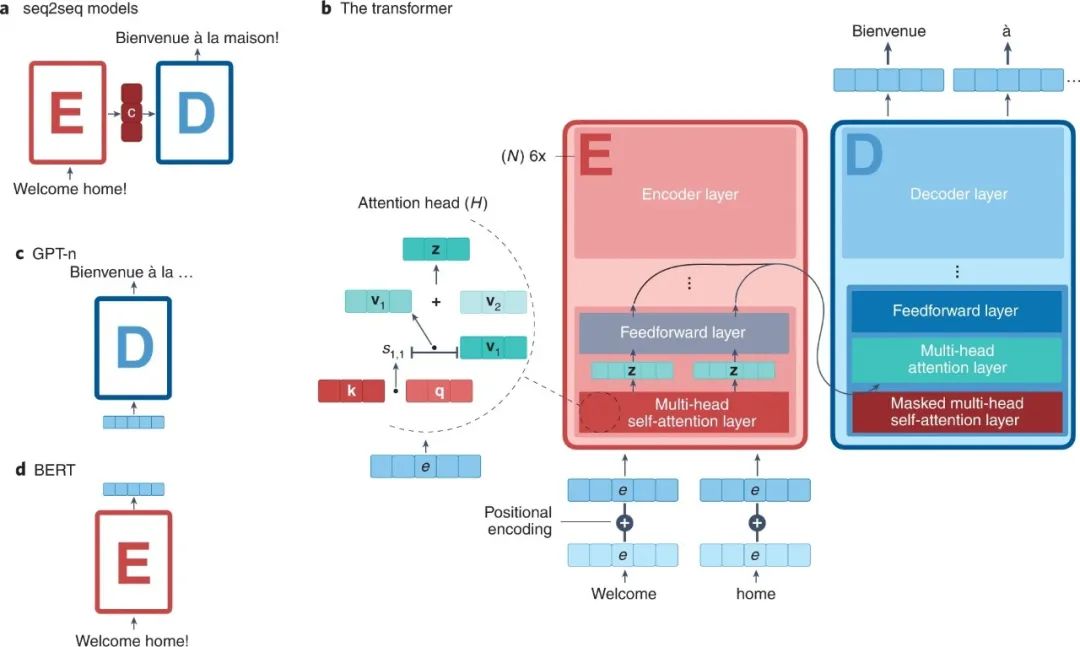
图3:最常用的Transformer的示意图 虽然注意力机制在许多类型的神经网络中已经无处不在,但在2017年变得特别突出,当时谷歌的研究人员发表了他们的开创性工作” Attention is all you need",它引入了一个架构,不仅在模块之间应用注意力,而且在整个模块中也应用注意力。这种新的设计允许编码器专注于输入序列的特定部分,在许多任务中产生更好的表现。 表1 Transformer模型汇总
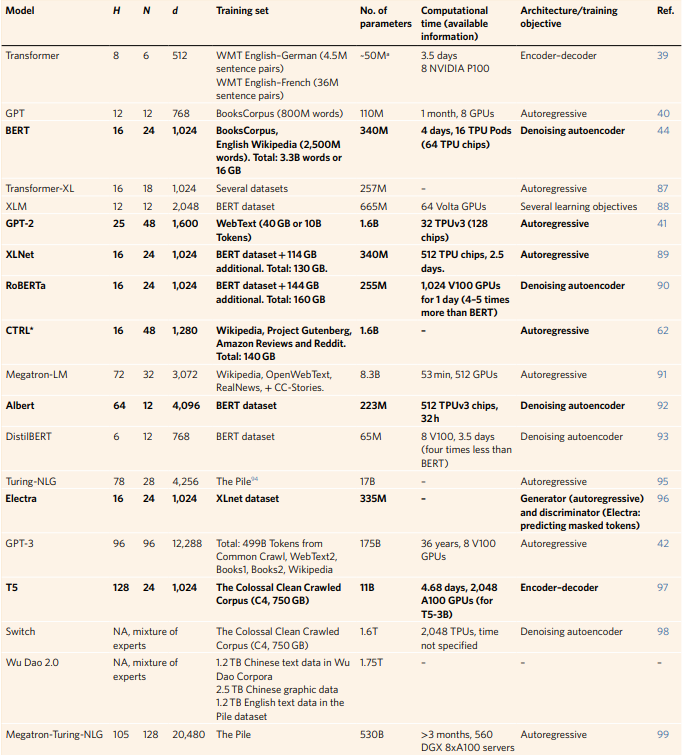
在Transformer架构的激励下,OpenAI发布了GPT(生成式预训练Transformer),这是一系列高性能预训练模型中的第一个。最近,OpenAI公布了它的第三代GPT模型,GPT-3,它包含的参数是GPT-2的100倍(表1)。并且能够以零样本的方式表现良好,即使是在从未受过训练的任务上,例如编写代码。
NLP领域的另一个突出发展来自谷歌人工智能语言团队,他们预先训练了BERT(来自Transformer的双向编码器表示法),以创建一个语言模型。BERT也是受Transformer结构的启发,但是,鉴于在这种情况下,兴趣在于创建文本输入的表示,它只使用编码器模块(图3d)。 除了这两个有代表性的仅有编码器和解码器架构的Transformer的例子外,在过去的三年里,已经有成千上万的Transformer被发表。许多已经可以在HuggingFace资源库中找到。 蛋白质序列是Transformer的理想对象 事实上,上一代Transformer的巨大成功,部分原因是它们所训练的语料库不断增加(表1),这反过来又允许创建更大和更强大的模型。图4a显示了表1中的Transformer的发布日期和参数数量(以对数为单位)。
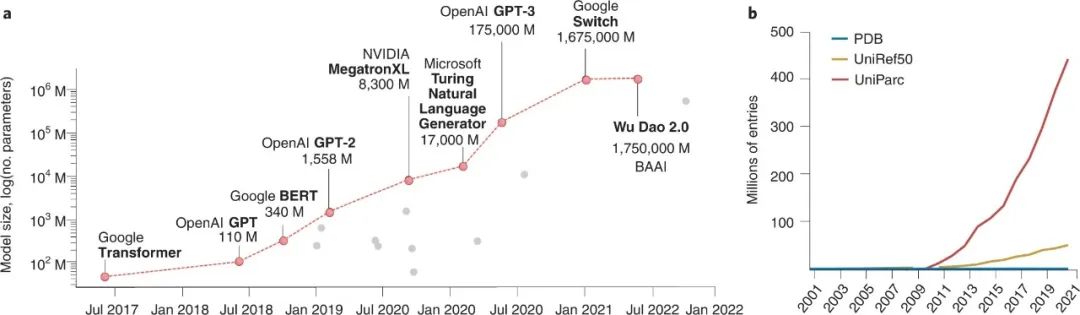
图4:模型大小和数据库随时间的增长 生物数据库的规模也在大幅增长,这一趋势在蛋白质序列中最为明显。图4b说明了过去20年中序列和结构数据库的数据获取趋势,表明蛋白质序列的表征比其对应结构的增长速度要快得多。
尽管最近开发的高性能结构预测方法,如AlphaFold,使科学家们能够将结构的增长与序列等同起来,但它并没有解决功能注释这一耗时的问题。因此,我们面对的是一个未标注数据与标注数据之比广泛增加的领域(这一现象被称为序列-结构差距),鉴于半监督方法的成功,我们可以推测Transformer也可以类似地利用庞大的蛋白质空间,并在蛋白质研究领域激发一场类似的革命。 用于蛋白质设计的Transformer 最近NLP的革命性发展已经影响了一些开创性的蛋白质研究,一些研究已经将语言模型的概念应用于蛋白质序列。 第一个基于Transformer的蛋白质语言模型,ESM和TAPE,可以追溯到2019年。ESM-1b是由Facebook AI领导的一项工作,是一个在2.5亿个蛋白质序列上训练的编码器Transformer,其结构和训练目标与BERT相同(图3d),但是,在这种情况下,33个编码器层在UniParc数据库(图3d)上被预先训练,以产生编码蛋白质序列的矢量表示。ESM-1b的表示,类似于捕捉语言语法的BERT句子表示,编码蛋白质的内部组织,从氨基酸的生物化学特性水平到蛋白质之间的进化关系。 最近,来自慕尼黑、Nvidia和Google AI的科学家合作开发了ProtTrans,这是一个令人印象深刻的对以前发布的六个基于Transformer的架构(Transformer-XL、BERT、Albert、XLnet、T5和Electra;表1)的改进,可以完全为社区所接受。这项研究利用了迄今为止最大的训练数据集,包含了来自UniParc和Big Fantastic数据库的超过3900亿个氨基酸。他们的工作表明,蛋白质嵌入--Transformer输出的矢量表示--能够准确地预测每个残基的二级结构和亚细胞定位。 这些早期的研究证明了学习蛋白质表征在下游应用中的潜力,包括分类或回归任务。**最近,有几项工作发表,使用预先训练好的模型来生成蛋白质序列。**虽然没有明确采用语言模型,但提到了两个从传统的蛋白质设计范式--基于搜索能量函数最小值--转向神经网络方法。首先,受DeepDream(谷歌的CNN)的生成能力的启发,Anishchenko等人在一个逐步的过程中应用trRosetta,以高通量的方式生成理想化的蛋白质结构。其次,Huang等人最近生成了SCUBA,一种新型的自适应核邻接计数神经网络(NC-NN)方法,产生了具有新拓扑结构的新结构。 关于语言模型的特殊情况,最近有几项工作正在利用Transformer进行蛋白质设计。Castro等人实现了ReLSO,这是一个经过训练的自动编码器,可以联合生成序列并预测输入标记数据集的适用性。Moffat等人实施了DARK,这是一个有1.1亿个解码器的Transformer,能够设计新的结构,Ferruz等人发布了ProtGPT2,这是一个基于GPT-2结构的7.38亿个Transformer模型,能够在蛋白质空间的未开发区域生成新的序列。
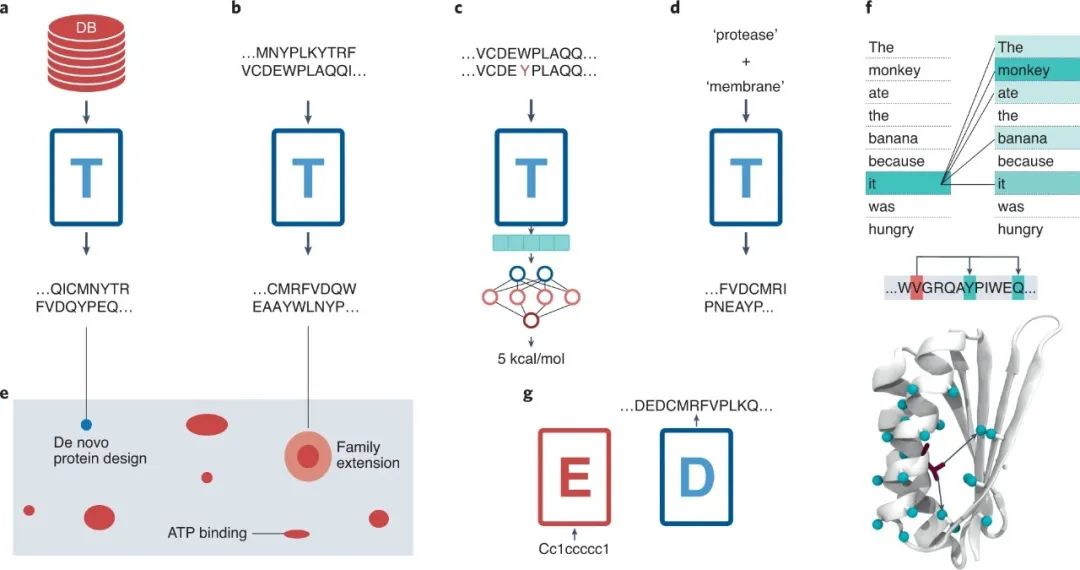
图5:利用Transformer模型在蛋白质工程领域的可能性概述
定制的蛋白质设计 NLP及其应用于定制蛋白质设计的下一个重要步骤是在训练中加入功能标签。最近,Gligorijević等人实现了一个去噪自动编码器Transformer,在这个Transformer中,一定的输入序列被转化为质量上乘的输出序列和一定的功能。然而,在实现可控文本生成方面最重要的工作之一是开发了条件Transformer语言(CTRL),这是一个自回归模型,包括能够不依赖输入序列而可控地生成文本的条件标记(表1)。 这些研究突出了一个有前途的新研究领域:用条件Transformer可控制地生成蛋白质序列。在基于Transformer的蛋白质语言模型中加入条件标签,不仅可以像以前的这些工作那样生成新的序列,而且有可能对这些蛋白质的特性进行控制。 通过提示语言模型产生定制序列的能力将是蛋白质研究中的一个变革性里程碑,但其实施并非没有挑战。监督序列标记的过程依赖于注释序列的质量。 **不过,最近在序列注释方面的工作可能为更快的自动注释过程打开了一扇新的大门。Bileschi等人最近使用神经网络来预测功能注释,将Pfam数据库扩展了9.5%以上。尽管这可能是一个漫长而具有挑战性的过程,但在这个方向上的努力可能会推动在可预见的未来对蛋白质空间的很大一部分进行注释,从而促进条件Transformer的实施。 酶、受体和生物传感器设计 2018年,IBM研究院发布了IBM RXN for Chemistry,这是一个基于云的应用程序,将有机化学与人类语言联系起来,可以使用编码器-解码器架构预测化学反应最可能结果(图3a)。 鉴于最近IBM对化学反应的矢量表示进行编码的方法,我们可以设想另一种模型,将化学反应作为输入,产生蛋白质序列作为输出。这种模型将为酶的设计提供一种创新的途径,**包括能够催化自然界中没有的反应的工程酶。 可解释的蛋白质设计 传统上,最广泛使用的NLP技术,如HMMs或SVMs(图2),本质上是可以解释的,因此被归为”白盒”。最近,深度学习方法的爆炸性增长在整个NLP任务中达到了很高的性能,带来了开发新技术来解释这些模型的挑战。针对”黑盒”模型的XAI技术已经取得了实质性的进展,其中五个主要技术是:特征重要性(feature importance)、代理模型(surrogate model)、例子驱动(example-driven)、基于出处(provenance-based)和声明性归纳(declarative induction)。 将Transformer的内部运作可视化的可能性可以为更好地理解蛋白质的折叠和设计带来巨大的机会。 蛋白质设计的未来是否掌握在大公司手中 近年来发表的Transformer模型是由大公司主导的(图4a)。据估计,**用1750亿个参数训练GPT-3--迄今为止第二大的模型--花费了1200万美元,需要超过10000天的GPU时间。**其他的模型也是通过使用大量的TPU资源来训练的。训练这样的深度学习模型是一种商品,像OpenAI或谷歌这样的大公司可能可以获得,但对于初创公司和许多学术研究团体来说,可能是无法达到的。他们在经济上的可及性是一个问题。 迄今为止发表的9个基于蛋白质的Transformer模型中的7个(表1)是由大公司领导或参加。 根据蛋白质的特定属性(如由于必须形成三维结构而产生的偏差)来调整模型,可能会在降低计算成本的情况下提高性能。 结论 **本文设想了将目前的NLP方法转移到蛋白质研究领域的六个直接应用。**按照目前的NLPTransformer对蛋白质序列的适用程度排序,我们可以:(1)在蛋白质空间的未观察到的区域生成序列;(2)对天然蛋白质家族的序列进行微调,以扩展它们的库;(3)利用其编码的矢量表示作为其他下游模型的输入,用于蛋白质工程任务;(4)生成具有特定功能特性的条件序列;(5)利用编码器-解码器Transformer设计完全新颖的、目的明确的受体和酶;(6)更全面地了解序列-结构-功能关系,包括通过解释这些语言模型来支配蛋白质折叠的规则。 毋庸置疑,**这些进展并非没有挑战,模型的大小和功能注释的困难都是最值得注意的两个问题。**此外,正如早期研究指出的那样,基准将是比较模型性能的首要条件,这在序列生成方面尤其具有挑战性。 对生成的序列进行适当的评估,需要实施高通量的实验特征分析。最终评估这些序列的相关功能(例如它们的催化活性)是否超越当前的蛋白质工程策略(可能是在实验反馈改进模型的迭代轮次中)将是至关重要的。 尽管有这些困难,我们相信基于Transformer的蛋白质语言模型将彻底改变蛋白质设计领域,并为许多当前和未来的社会挑战提供新的解决方案。 参考资料 Ferruz, N., Höcker, B. Controllable protein design with language models. Nat Mach Intell 4, 521–532 (2022). https://doi.org/10.1038/s42256-022-00499-z
--------- End ---------

