

要在模拟环境中训练军事单元,就必须为对方和己方部队生成具有代表性的行为。由于自动化系统难以提供代表适当军事理论的智能和自适应行为,并且无法在 "行动后回顾 "中进行解释,因此通常需要人工参与。自动化解决方案往往无法保持足够的多样性,无法在模拟任务的连续迭代中重新执行而不容易被预测。本文介绍了自动分层规划智能体的去决策方法,旨在克服这些挑战。任务式指挥智能体(MCAs)将用于多智能体目标推理的约束优化与用于路线规划的状态空间规划相结合,为模拟单元生成作战方案(COAs)。详细介绍了这两个步骤的扩展,以便在帕累托前沿为多个实际(如距离)、条令(如掩护和隐蔽)和行为(如风险容忍度或攻击性)目标生成一组 COA。
将使用这一新方法生成的 COA 与之前的 MCA 结果进行了比较,后者使用的是一种更为传统的方法,即将目标或偏好汇总到一个加权效用函数中,并根据该联合效用进行优化,以找到多个最优和接近最优的解决方案。以前的行为往往反映了效用或定位方面的许多微小差异,与之相比,分析多个目标之间的权衡会产生更有意义的多样化解决方案。在体验式培训的背景下,这种多样性可支持具有不同偏好和优先级的自动单元重放场景。我们通过评估指标总结了我们的成果,这些指标表明,一组 COA 可以适当地代表条令约束,并在目标之间进行多样化、合理和可解释的权衡。
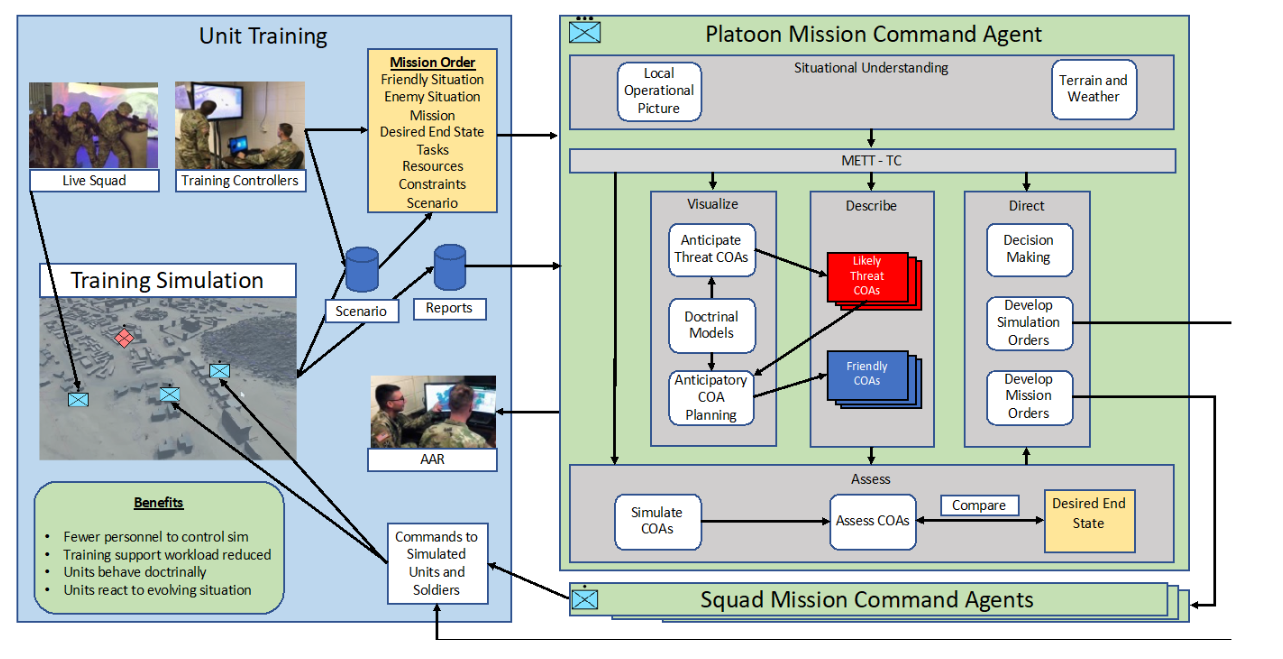
图 1. 用于模拟单元智能 COA 规划的任务式指挥智能体
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2024年1月1日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
85+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2024年1月1日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
85+阅读 · 2023年3月21日