
军事防御现代化规划通常涉及复杂的系统,必须了解这些系统,以便为设计、规划、实施和采购决策提供信息。为了获得对系统的基本了解并确定关键的初始参数,仿真实验可以用来在一个大型参数空间内有效地生成数据。虽然机器学习模型可用于模拟后的分析,以确定关键参数,但当目的是为决策者提供支持时,其可解释性和黑盒性质会带来挑战。在本文中,应用了一种可解释机器学习预测的模型诊断方法,称为沙普利加和解释(SHapley Additive exPlanations,SHAP),用于从基于Agent的模拟中获得数据,该模拟是一个军事作战场景。该场景是由加拿大陆军对其情报、监视和侦察资产进行现代化的举措所激发的,并对其进行了抽象化,以尽量减少建模系统的复杂性并验证SHAP的结论。

关键词:基于Agent的仿真,数据耕耘,可解释机器学习。
1 引言
军事防御现代化计划通常涉及复杂的系统,必须了解这些系统,以便为设计、规划、实施和采购决策提供信息--这些决策通常与数百万到数十亿美元的预算相联系。例如,加拿大政府为实现加拿大武装部队(CAF)和国防部的密码能力现代化,拨款范围在2000万到4900万美元之间,为实现CAF轻型和重型后勤车辆能力的现代化,拨款范围在10亿到49.9亿美元之间(加拿大政府2020)。
仿真实验可以帮助对系统的基本了解,找到稳健的决策或方案,并比较不同决策或方案的优劣(Kleijnen等人,2005)。数据耕耘是指利用仿真实验在一个大的参数空间内有效地增长数据,以支持决策。它是一个跨学科的协作过程,使用快速原型设计、仿真建模、实验设计、高性能计算以及数据分析和可视化;详细概述见Horne等人(2014)。数据耕耘过程可以帮助操作仿真模型,学习仿真模型的行为,并确定关键信息,包括输入和输出之间的因果关系(Sanchez 2015)。实验设计应该是灵活的,以考虑不同的元模型、数据挖掘和图形分析技术,因为通常一种单一的方法将不适合全面评估模拟输出(Sanchez 2015)。
数据耕耘过程最早在20世纪90年代末提出(Horne 1999),此后被应用于海洋领域(Cheang 2016, Dobias and Eisler 2017, Morgan et al. 2018, Kesler 2019)、陆地领域(Kallfass and Schlaak 2012)、网络领域(Horne and Robinson 2016)和多领域(Huber and Kallfass 2015, Gordon 2019)等各种军事应用。数据耕耘已被用于研究各种类型的军事行动,包括战斗(Kallfass和Schlaak 2012)、人群控制(Kryza等人2012)、伤员疏散(Featherstone 2009)、空袭(Huber和Kallfass 2015)和国土安全,如关键基础设施的保护行动、海洋环境中部队保护的非致命武器选择,以及城市恐怖袭击的应急响应(Lucas等人2007)。
数据耕耘的挑战之一是模拟后的分析和可视化。这一步的重点是突出有用的信息,提取结论,并支持决策,这需要高度有效的分析技术,以充分利用可能产生的大量数据(Horne等人,2014)。鉴于机器学习模型处理和评估大数据的能力,它们很适合这项任务。然而,许多机器学习模型的黑箱性质可能具有挑战性,因为主要目标不是预测而是理解模拟。在以前的数据耕耘的军事应用中,模拟后的分析往往侧重于描述性统计(Huber和Kallfass 2015,Horne和Robinson 2016,Dobias和Eisler 2017)或描述性统计和可解释性模型的组合,如逐步回归和分区树(Featherstone 2009,Kallfass和Schlaak 2012,Cheang 2016,Gordon 2019,Kesler 2019)。
与可解释的模型相比,在黑箱模型中,如神经网络或随机森林,不可能直接有意义地检查其组成部分并获得洞察力(Ribeiro, Singh, and Guestrin 2016)。然而,这些更复杂的黑箱模型可以实现更高的预测准确性,在可解释性和准确性之间形成了一种权衡(Lundberg和Lee 2017)。为了应对这种权衡,已经开发了模型诊断方法来解释任何机器学习模型的预测。在最近的一个数据耕耘的军事应用中,Amyot-Bourgeois、Serré和Dobias(2021年)对随机森林模型的输出应用了互换特征重要性,这是一种模型无关的方法。特征重要性措施表明每个特征,或数据耕耘背景下的模拟参数,在预测感兴趣的结果方面的有用程度。识别重要参数有助于简化决策过程,但除非能够理解重要参数和感兴趣的结果之间的关系,否则价值有限。SHapley Additive exPlanations(SHAP)提供了一种替代包络特征重要性的方法,也可用于研究特征的价值与对感兴趣的结果的影响之间的关系(Molnar 2021)。根植于博弈论的Shapley值,SHAP的计算要求是NP-Hard;然而,基于树的机器学习模型有一个低阶多项式时间算法,也可用于研究特征的相互作用(Lundberg等人,2020)。
本文扩展了Amyot-Bourgeois、Serré和Dobias(2021)的工作,将SHAP作为模拟后分析的一部分,以评估它是否能对一个模拟的军事作战场景提供有意义的解释。在加拿大陆军(CA)对其情报、监视和侦察(ISR)资产进行现代化的倡议的激励下,模拟场景也对ISR支持稳定行动进行了模拟,但考虑了两种ISR资产定位方案,并纳入了一种额外的ISR资产类型。该场景在新西兰国防技术局开发的基于Agent的模拟环境中实施,该环境被称为地图感知非统一自动机(MANA)。选择MANA的部分原因是它的数据耕作能力,可以利用它在广泛的参数选项空间内运行模拟。该方案在第2节有更全面的描述。关于模拟参数、实验设计、指标和模拟后分析方法的细节将在第3节介绍。第4节介绍了仿真实验和SHAP分析的结果。最后,在第5节中提供了一些结论性意见。
2 场景
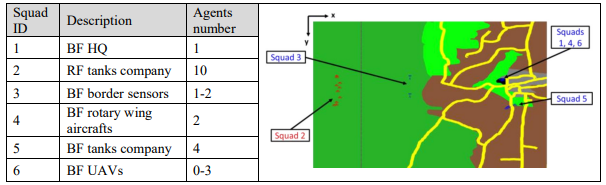
仿真场景是一个简化的小插曲,它是为了证明利用ISR能力来支持加拿大军队的各种任务(加拿大公共工程和政府服务部2020)。它代表了一种情况,即加拿大军队将与一个多边伙伴,如北大西洋公约组织(NATO),领导或促进国际和平行动和稳定任务,这是加拿大国防政策 "强大、安全和参与 "的核心任务之一(加拿大政府2017年)。地点是北约的一个成员国受到一个邻国,一个非北约近邻对手的入侵威胁。因此,受到威胁的北约成员国援引了北约第5条,并成立了一个北约联盟来协助受到威胁的国家。北约联盟(蓝军,BF)监视边界,并与任何越境的红军(RF)交战。
下面的表1列出了情景中包括的所有小队,以及每个小队的地形和初始位置的表述。红军试图到达蓝军总部(蓝军 HQ)。当红军向蓝军总部推进时,它进入了蓝军边境传感器的探测和分类范围。在MANA中,探测是指在某一位置感知到特工的存在,而分类是指将探测到的特工的忠诚度分为友军(蓝军)或敌军(红军)的行为。一旦探测到并被归类为敌方,边界传感器就会将探测到的特工的忠诚度和位置传达给边界总部,后者则提示4、5和6小队(列于表1)向确定的RF位置移动。4号和5号小队的任务是与红军交战,而由无人驾驶飞行器(UAV)组成的6号小队的任务是持续跟踪红军并提示蓝军总部进行间接火力支援。如果所有的红军都失去了能力,或者达到了最大的时间限制,模拟就会结束。
表1: 基于Agent的模型中每个小队的描述和初始位置。
3 方法
3.1 场景参数和实验设计
选择用于参数化的自变量是蓝军边界传感器的数量、蓝军边界传感器的探测和分类范围(称为传感器范围)、蓝军边界传感器探测到的特工被正确分类为红军或蓝军的概率(称为分类概率)、蓝军边界传感器对RF传感器的隐蔽程度(称为传感器隐蔽性),以及蓝军无人机的数量。实验设计遵循网格状结构,每个设计点重复进行一百次迭代。表2显示了参数的范围。
仿真实验首先进行,同时保持蓝军边界传感器的固定位置,如表1所示为双传感器情况,而对于单传感器情况,则位于两个传感器之间的中点。然后重复模拟实验,将两个传感器和单个传感器随机放置在与两个固定的蓝军边界传感器之间的距离相对应的方框内(同时在双传感器情况下保持20个网格的最小分离距离)。在分析部分,这两种配置的传感器部署被称为固定或随机的传感器位置。
表2:变量的参数化范围。

3.2 衡量标准
仿真实验的目的是评估传感器组合(即给不同传感器的配置参数,如表2所列)在情景中的性能。已经提出并监测了几个指标来评估ISR资产的系统,如第一个探测步骤、所有红军坦克的平均探测步骤和探测范围、探测到的红军坦克的比例,以及一些蓝军的生存能力和致命性指标(Amyot-Bourgeois, Serré, and Dobias 2021)。在本研究中,在监测到的指标中选择了两个衡量有效性(MOEs)的例子进行更彻底的分析:第一个检测步骤和检测到的RF坦克的比例。第一个检测步骤是指从模拟开始到蓝军传感器第一次检测到红军坦克并将其分类的延迟时间(以用户定义的时间步长为1到10,000步,后者是模拟的最大分配时间)。检测到的RF坦克的比例是指至少被蓝军 ISR资产之一检测到并分类的RF坦克与RF坦克总数的比率,在整个实验过程中,该比率保持为10。
3.3 仿真实施
该场景使用MANA实现,MANA是一种对抽象表示有用的提炼工具(Anderson 2013)。MANA拥有数据耕耘能力,但可同时变化的参数数量限制在两个,而且只能与相同的固定小队相关联。这使得我们无法使用MANA内部的数据耕作能力来生成各种设计点。然而,方案文件被保存为XML文件,不同的相关参数可以使用XML编辑器直接修改。整套设计点是用Python的ElementTree软件包生成的,并保存为XML文件。仿真是使用高性能计算进行的,因为总的迭代次数上升到接近200万次,而且事实证明并行化对减少计算时间很有用。然后用Python脚本处理所有迭代的输出文件,以提取感兴趣的MOEs,并将实验结果整理成便于模拟后分析的格式。
3.4 模拟仿真后的分析方法
在机器学习中,主要目标是根据一组特征变量来预测结果或目标变量。在数据农业的背景下,场景参数被视为特征变量,MOE被视为目标变量。根据目标变量是分类的还是定量的,机器学习问题被分别称为分类问题或回归问题。随机森林是一种常见的机器学习模型,本研究之所以选择它,部分原因是它被发现通常表现良好,只需要很少的模型调整(Hastie, Tibshirani, and Friedman 2009, 590)。随机森林最早是由Brieman(2001)提出的,它由一大组通过引导训练数据建立的决策树组成。每次在树中考虑拆分时,只有一个随机的特征变量子样本被认为是拆分的候选人。正是这个特征抽样过程使树去掉了相关性,导致这组树的平均值比单树模型的变量更少,更可靠(Gareth等人,2017,320)。然后,随机森林通过多数票或树的预测平均值对测试观测值进行分类或预测。
本研究中关注的两个MOE,即第一个检测步骤和检测到的RF罐的比例,是定量的目标变量。耕耘模拟数据以70/30的比例被随机分成训练和测试集。然后使用Python的Scikit-Learn软件包的0.24.1版本(Pedregosa等人,2011)对随机森林回归器进行训练和测试。使用随机森林回归器的默认设置,除了将分裂内部节点所需的最小样本数增加到30,将叶子节点所需的最小样本数增加到10,并将最大深度设置为10以限制单个树的大小。在寻找最佳分割时,确定最大特征数的方法也从默认的使用总特征数改为使用特征数的(近似)平方根。在构建随机森林时通常选择平方根法(Gareth等人,2017,319)。为了评估随机森林的回归者,使用了决定系数(R2)。R2表示拟合度,是衡量未见过的观察结果被模型预测的程度(Scikit-Learn, n.d., chap 3.3)。它的最佳分值是1,而0分表示一个恒定的模型(即一个模型总是预测预期的目标值,而忽略特征变量)。它也可以是负数,因为一个模型有可能比恒定模型的表现更差。
SHAP方法计算Shapley值,它基于联盟博弈理论,代表了一个特征值与数据集的平均预测值相比对模型预测的贡献(Molnar 2021)。SHAP值是局部解释(即针对单个数据点),可以汇总起来解释一个模型的全局行为(Lundberg等人,2020)。作为SHAP值的延伸,Lundberg、Erion和Lee(2019)提出了同样基于博弈论的SHAP交互值,以直接捕捉成对的交互效应。由于随机森林是一个基于树的模型,使用Python的SHAP包中的TreeExplainer可以获得计算SHAP值和SHAP交互值的高速精确算法(Lundberg等人,2020)。0.38.1版的SHAP包提供了一系列的图形总结,包括SHAP特征重要性。为便于比较,还提供了互换特征重要性,它是用Python的ELI5软件包0.11.0版本的算法计算的(ELI5, n.d.)。互换特征重要性类似于Brieman(2001)首次提出的用于随机森林的方法。它通过确定当一个特征不可用时对模型性能(在本研究中用R2衡量)的影响来衡量其重要性。变量的去除是通过在测试集中用自身的随机置换来完成的。
4 分析
表3总结了每个MOE以及固定和随机传感器位置的随机森林回归器的性能。在所有情况下,随机森林模型都明显优于常数模型,后者的R2为零。对于第一个检测步骤,固定和随机传感器位置的特征变量解释了MOE中80%以上的变异。对于检测到的红军坦克的比例,拟合度没有那么强,固定传感器位置的特征变量解释了MOE中略高于60%的变异,随机传感器位置的特征变量解释了MOE中略低于60%的变异。
图1和图2分别列出了第一个检测步骤的排列特征重要性和SHAP特征重要性,以及检测到的RF坦克的比例。这些方法在识别最重要的特征方面基本一致,尽管在某些情况下确切的排序有所不同,特别是在不太重要的特征中。在图1(a)中,传感器范围是预测第一个检测步骤的最重要特征。对于固定和随机的传感器位置,如果将传感器范围从随机森林模型中删除,R2将下降到零以下,表明性能比恒定模型差。在图1(b)中,传感器范围也是最重要的特征。对模型输出的幅度(即预测的第一个检测步骤)的平均影响由SHAP值的绝对值的平均值给出。尺度与目标,即第一个检测步骤的单位相同。在图2(a)中,有两个特征对预测探测到的红军坦克的比例很重要:无人机的数量和传感器的范围。请注意,这两个特征的重要性顺序对于固定和随机的传感器位置是不同的。在图2(b)中,同样的两个特征被SHAP方法确定为最重要。请注意,在这种情况下,无人机的数量对于固定和随机的传感器位置都是排在第一位的。
表3:随机森林模型的性能得分。


图1:第一个检测步骤的特征重要性总结
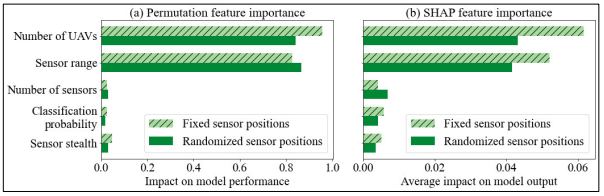
图2:检测到的红军坦克比例的特征重要性总结
虽然标准的特征重要性柱状图提供了关于一个特征的相对重要性的见解,但正如Lundberg、Erion和Lee(2019)所述,"它们并不代表该特征对模型输出的影响范围和分布,以及该特征的价值与影响的关系"。他们提出了SHAP总结图作为替代方案,图3显示了第一个检测步骤,图4显示了检测到的红军坦克的比例。每个点代表一个设计点的SHAP值,并以相应的单个特征的值来着色,蓝色代表低值,红色代表高值。这些特征按其整体影响(即SHAP值的绝对值之和)排序。正(或负)的SHAP值表示与数据集的平均预测值相比,对预测(模型的输出)有正(或负)的贡献。
在图3(a)和图3(b)中,传感器范围的颜色的平滑渐变表明,随着传感器范围的缩小,模型的输出(预测的第一个检测步骤)平滑增加。这种行为在模拟中是可以预期的:第一次检测一般由边界传感器完成,当它们的范围较大时,它们会更早地进行第一次检测。当传感器位置固定时,图3(a)显示,当有一个边界传感器(蓝点)时,与有两个边界传感器(红点)时相比,第一个检测步骤比平均时间早(负SHAP值)。对模拟的检查也证实了这一结果:单个固定传感器的位置倾向于与穿越边界的红军坦克的路径一致,使单传感器的情况比双传感器的情况有优势。在图3(b)中,SHAP值的模式在传感器的数量上几乎完全颠倒。当边界传感器的位置在每次迭代中被随机分配时,在固定传感器配置中,单传感器情况比双传感器情况的优势被消除了。因此,在这种配置下,从单传感器到双传感器情况下,传感器区域覆盖的增加更加有效,红军坦克路径有更大的机会穿过两个传感器覆盖的区域,而不是一个传感器覆盖的区域。
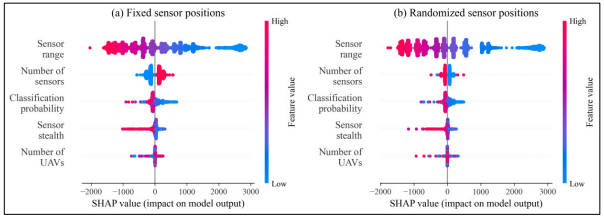
图3:第一个检测步骤的SHAP总结图。
图4显示了探测到的红军坦克比例的SHAP汇总图。无人机的数量是对全球影响最大的特征。对于这个特征,蓝点代表没有蓝军无人机的设计点,这降低了模型的输出(预测检测到的RF坦克的比例)。这种行为在模拟中是预料之中的:一旦蓝军无人机被触发,它们就会被送到第一个探测到的RF坦克的位置,在跟踪它的同时,可以探测到其他RF坦克。因此,拥有一些无人机与没有无人机相比,可以增加探测到的红军坦克的比例。同样,低传感器范围也会降低检测到的红军坦克的比例。如图3所示,较低的传感器范围与较晚的第一次检测步骤有关,无人机在第一次检测之前不会被触发。虽然固定和随机传感器位置的三个不太重要的特征的排序不同,但传感器隐身性的右尾巴长,但左尾巴短,表明在这两种配置中,高传感器隐身性可以明显增加探测到的红军坦克的比例,但低传感器隐身性并没有明显减少探测到的红军坦克的比例。这可以解释为隐身性更强的边境传感器的生存能力更强,导致使用时间更长,有更多机会进行多次探测。

图4:探测到的RF坦克比例的SHAP总结图。
SHAP值侧重于特征效应,而SHAP交互作用值则可以将特征效应分解为主效应和交互作用。与SHAP值一样,SHAP交互值的全球影响也可以通过对单个SHAP交互值的绝对值进行总结。图5和图6分别列出了第一个检测步骤和检测到的红军坦克比例的这些总结。每个图中的比例代表了特征交互作用的相对全球影响。在图5中,对于固定的和随机的传感器位置,传感器范围和传感器数量、传感器隐蔽性和分类概率之间的相互作用影响最大。在图6中,对于固定和随机的传感器位置,只有一种交互作用的全局影响远远大于其他交互作用:传感器范围和无人机数量的交互作用。基本的互动模式可以用依赖图来进一步研究。为了说明这一点,图7显示了传感器范围和无人机数量的SHAP交互值。两种传感器配置的模式相似,并显示了在可能的传感器范围内检测到的红军坦克比例的明显转变。对于低于50的传感器范围,相对于没有无人机,至少有一个无人机增加了检测到的RF坦克的比例。然而,一旦传感器范围至少达到50,这种模式就会逆转。这可以追溯到模拟中的行为:在另一个蓝军小队或特工(即边境传感器或总部)检测到至少一辆RF坦克之前,无人机不会参与。一旦边境传感器的探测范围足够大,无人机的额外探测能力对探测到的红军坦克比例的影响就会减少。

图5:第一个探测步骤的SHAP交互值摘要

图6:检测到的RF坦克比例的SHAP交互作用值的汇总。
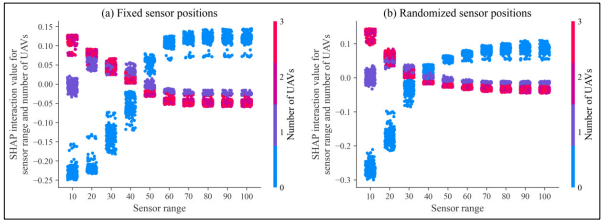
图7:探测到的RF坦克比例的传感器范围和无人机数量之间的SHAP交互效应的依赖图。
5 结论
本文的目的是评估SHAP在基于Agent的模拟中的数据养殖上的使用,以改善军事行动场景的模拟后分析。虽然机器学习模型,如随机森林,非常适合于大数据,但当分析的主要目标是获得对系统的基本了解以告知决策者时,其黑箱性质构成了挑战。SHAP是一种与模型无关的方法,用于解释任何机器学习模型的预测结果。TreeExplainer的作者Lundberg等人(2020年)提出,结合许多局部解释(即SHAP值)可以保留 "对模型的局部忠实性,同时仍然捕捉到全局模式,从而对模型的行为有更丰富、更准确的表述"。
提出了标准的特征重要性柱状图,使用基于排列组合的算法和SHAP值进行计算,强调这些图对模型行为的洞察力有限。虽然这两种计算特征重要性的方法在确定预测两个感兴趣的MOE的前一或两个特征方面基本一致,但SHAP总结图、交互值和依赖图对随机森林模型的行为提供了更多的了解。SHAP总结图显示了模型的预测对不同特征值的变化(例如,随着传感器范围的缩小,预测的第一个探测步骤平稳增加),并确定了极端值的影响(例如,高传感器的隐蔽性可以大大增加探测到的红军坦克的比例)。SHAP的交互值和依赖性图提供了进一步的洞察力,以了解所发现的两个最重要的特征对探测到的红军坦克比例的综合影响。SHAP还成功地识别了固定和随机传感器位置之间的关键差异,证实了在确定传感器组合时,位置,而不仅仅是传感器的数量,是一个重要的考虑。使用SHAP可以验证所发现的见解,因为模拟场景被有意抽象化,以尽量减少其复杂性并保持对战场动态的直观理解。这意味着可以根据对实施的直接了解或通过在MANA中交互运行模拟来查看Agent的行为来确认这些见解。
虽然SHAP在改进模拟后的分析方面表现出了显著的前景,但它解释了在养殖数据上训练的机器学习模型的预测。因此,它不是对模拟场景的直接解释,在机器学习模型性能不强的情况下,可能产生误导性的结果。对机器学习模型的适当训练和测试仍然是模拟后分析的关键步骤。尽管如此,这项研究仍然可以用来向决策者展示数据农业的潜力,以及它如何利用抽象的模拟实验帮助人们对一个复杂的系统有基本的了解。这在军事现代化项目的早期阶段可能特别有帮助;研究结果可以用来确定参数或选项,以便进行更详细的研究。未来的研究将考虑更复杂的场景和更广泛的机器学习模型。
作者
MAUDE AMYOT-BOURGEOIS是加拿大国防研究与发展部作战研究与分析中心的初级国防科学家。自2019年以来,她与加拿大陆军作战研究和分析小组的同事合作进行各种作战模拟研究。Maude Amyot-Bourgeois在加拿大渥太华大学获得物理学硕士学位。她的电子邮件地址是:maude.amyot-bourgeois@ecn.forces.gc.ca。
BRITTANY ASTLES自2021年1月起担任加拿大国防研究与发展部作战研究与分析中心的学生国防科学家。她之前的工作是利用机器学习研究全球恐怖袭击趋势和U型分形事件。她目前是地理学硕士的候选人,专业是数据科学。她的电子邮件是:brittany.astles@ecn.forces.gc.ca

