

在过去的一年里,多模态大型语言模型(MM-LLMs)经历了实质性的进展,通过成本效益高的训练策略,增强了现成的大型语言模型(LLMs),以支持多模态的输入或输出。这些结果模型不仅保留了LLMs固有的推理和决策能力,还增强了多种多模态任务的能力**。在这篇论文中,我们提供了一份全面的综述,旨在促进对MM-LLMs的进一步研究。具体而言,我们首先概述了模型架构和训练流程的一般设计公式。随后,我们简要介绍了26种现有的MM-LLMs,每种都有其特定的公式化特征**。此外,我们回顾了MM-LLMs在主流基准测试上的表现,并总结了关键的训练秘诀以增强MM-LLMs的效能。最后,我们探索了MM-LLMs的有希望的发展方向,同时实时跟踪网站1上不断更新该领域的最新发展。我们希望这份综述能够对MM-LLMs领域的持续发展做出贡献。
近年来,多模态(MM)预训练研究取得了显著进展,持续推动着下游任务的性能界限(Li et al., 2020; Akbari et al., 2021; Fang et al., 2021; Yan et al., 2021; Li et al., 2021; Radford et al., 2021; Li et al., 2022; Zellers et al., 2022; Zeng et al., 2022b; Yang et al., 2022; Wang et al., 2022a,b)。然而,随着模型和数据集规模的不断扩大,传统的MM模型在从头开始训练时会产生巨大的计算成本。考虑到MM研究位于各种模态的交汇处,一个合乎逻辑的方法是利用现成的预训练单模态基础模型,特别强调功能强大的大型语言模型(LLMs)(OpenAI, 2022)。这一策略旨在减轻计算成本并提高MM预训练的效能,从而催生了一个新领域:MM-LLMs。
MM-LLMs利用LLMs作为认知动力源以支持各种MM任务。LLMs具有诸如强大的语言生成、零样本迁移能力和情境内学习(ICL)等理想属性。同时,其他模态的基础模型提供高质量的表征。考虑到不同模态的基础模型各自经过预训练,MM-LLMs面临的核心挑战是如何有效地连接LLM与其他模态的模型,以实现协同推理。该领域的主要关注点一直是优化模态间的对齐,并通过多模态预训练(PT)+ 多模态指令调优(IT)流程与人类意图保持一致。
随着GPT-4(Vision)(OpenAI, 2023)和Gemini(Team et al., 2023)的首次亮相,展示出令人印象深刻的多模态理解和生成能力,对多模态大型语言模型(MM-LLMs)的研究热情被点燃。最初的研究主要关注多模态内容理解和文本生成,例如(Open)Flamingo(Alayrac et al., 2022; Awadalla et al., 2023)、BLIP-2(Li et al., 2023c)、Kosmos-1(Huang et al., 2023c)、LLaVA/LLaVA-1.5(Liu et al., 2023e,d)、MiniGPT4(Zhu et al., 2023a)、MultiModal-GPT(Gong et al., 2023)、VideoChat(Li et al., 2023d)、VideoLLaMA(Zhang et al., 2023e)、IDEFICS(IDEFICS, 2023)、Fuyu-8B(Bavishi et al., 2023)和QwenAudio(Chu et al., 2023b)。为了追求能够处理多模态输入和输出的MM-LLMs(Aiello et al., 2023),一些研究还探索了生成特定模态,如Kosmos2(Peng et al., 2023)和MiniGPT-5(Zheng et al., 2023b)引入了图像生成,SpeechGPT(Zhang et al., 2023a)引入了语音生成。最近的研究努力专注于模拟人类的任意模态转换,为通往人工通用智能的道路提供了启示。一些努力旨在将LLMs与外部工具结合,以实现接近“任意到任意”的多模态理解和生成,如Visual-ChatGPT(Wu et al., 2023a)、ViperGPT(Surís et al., 2023)、MMREACT(Yang et al., 2023)、HuggingGPT(Shen et al., 2023)和AudioGPT(Huang et al., 2023b)。相反,为了减轻级联系统中传播的错误,诸如NExT-GPT(Wu et al., 2023d)和CoDi-2(Tang et al., 2023b)等项目开发了能够处理任意模态的端到端MM-LLMs。
MM-LLMs的时间线如图1所示。在这篇论文中,我们提供了一份全面的综述,旨在促进对MM-LLMs的进一步研究。为了让读者全面理解MM-LLMs,我们首先从模型架构(第2节)和训练流程(第3节)概述了一般设计公式。我们将一般模型架构分解为五个部分:模态编码器(第2.1节)、输入投影器(第2.2节)、LLM骨干(第2.3节)、输出投影器(第2.4节)和模态生成器(第2.5节)。训练流程阐述了如何增强预训练的仅文本LLM以支持多模态输入或输出,主要包括两个阶段:多模态PT(第3.1节)和多模态IT(第3.2节)。在这一部分,我们还提供了多模态PT和IT的主流数据集概述。接下来,我们讨论了26种最先进(SOTA)的MM-LLMs,每种都有其特定的公式化,并在第4节总结了它们的发展趋势。在第5节中,我们全面回顾了主要MM-LLMs在主流基准测试上的表现,并提炼了增强MM-LLMs效能的关键训练秘诀。在第6节中,我们提出了MM-LLMs研究的有希望的方向。此外,我们建立了一个网站(https://mm-llms.github.io)来跟踪MM-LLMs的最新进展,并促进众包更新。最后,我们在第7节总结了整篇论文,并在附录A中讨论了与MM-LLMs相关的综述。我们希望我们的综述能帮助研究人员更深入地了解这一领域,并激发设计更有效的MM-LLMs。
模型架构
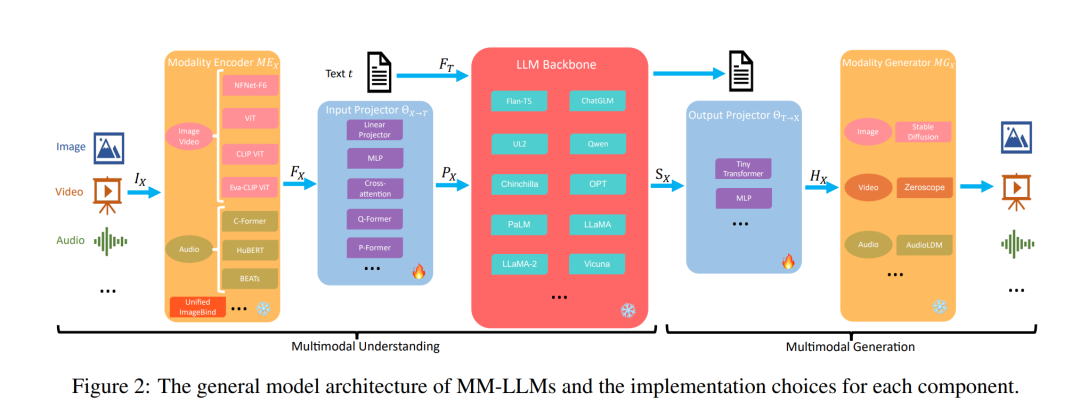
在这一部分中,我们将提供一个详细的概述,介绍构成一般模型架构的五个组成部分,以及每个部分的实施选择,如图2所示。只强调多模态理解的MM-LLMs包括前三个组件。在训练期间,模态编码器、LLM骨干和模态生成器通常保持冻结状态。主要的优化重点在于输入和输出投影器。考虑到投影器是轻量级组件,MM-LLMs中可训练参数的比例与总参数数相比显著较小(通常约为2%)。总体参数数取决于MM-LLMs中使用的核心LLM的规模。因此,MM-LLMs可以有效地训练以支持各种多模态任务。
训练流程
MM-LLMs的训练流程可以划分为两个主要阶段:多模态PT(MM PT)和多模态IT(MM IT)。
多模态PT
在PT阶段,通常利用X-Text数据集,通过优化预定义目标来训练输入和输出投影器,以实现不同模态之间的对齐(有时将PEFT应用于LLM骨干)。对于多模态理解模型,优化仅关注方程式(2),而对于多模态生成模型,优化涉及方程式(2)、(4)和(5)。在后一种情况下,方程式(2)还包括真实信号标记序列。 X-Text数据集包括图像-文本、视频-文本和音频-文本,图像-文本有两种类型:图像-文本对(“
多模态IT
多模态IT是一种方法,它涉及使用一组指令格式化的数据集对预训练的MM-LLMs进行微调(Wei et al., 2021)。通过这个调优过程,MM-LLMs可以通过遵循新的指令来泛化到未见任务,从而增强零样本性能。这种简单却影响深远的概念促进了NLP领域后续努力的成功,例如InstructGPT(Ouyang et al., 2022)、OPT-IML(Iyer et al., 2022)和InstructBLIP(Dai et al., 2023)的研究工作。 多模态IT包括监督微调(SFT)和基于人类反馈的强化学习(RLHF),旨在与人类意图或偏好保持一致并增强MM-LLMs的交互能力。SFT将PT阶段的部分数据转换为指令感知格式。以视觉问答(QA)为例,可以采用多种模板,如(1)<图像>{问题} 该问题的简短回答是;(2)<图像>检查图像并对以下问题给出简短回答:{问题}。答案:;等等。接下来,它使用相同的优化目标微调预训练的MM-LLMs。SFT数据集可以结构化为单轮QA或多轮对话。
在SFT之后,RLHF涉及对模型的进一步微调,依赖于关于MM-LLMs响应的反馈(例如,手动或自动标记的自然语言反馈(NLF))(Sun et al., 2023)。这个过程采用强化学习算法有效地整合不可微分的NLF。模型被训练为基于NLF生成相应的响应(Chen et al., 2023h; Akyürek et al., 2023)。SFT和RLHF数据集的统计信息在附录F的表4中呈现。
现有MM-LLMs在多模态PT和IT阶段使用的数据集多种多样,但它们都是表3和表4中数据集的子集。

最新多模态大型语言模型(SOTA MM-LLMs)
根据之前定义的设计公式,我们对26个SOTA MM-LLMs的架构和训练数据集规模进行了全面比较,如表1所示。随后,我们将简要介绍这些模型的核心贡献,并总结它们的发展趋势。 (1)Flamingo(Alayrac et al., 2022)代表了一系列用于处理交错的视觉数据和文本、生成自由格式文本输出的视觉语言(VL)模型。 (2)BLIP-2(Li et al., 2023c)引入了一个更资源高效的框架,包括轻量级的Q-Former来弥合模态差距和冻结LLMs的利用。利用LLMs,BLIP-2可以通过自然语言提示引导零样本图像到文本生成。 (3)LLaVA(Liu et al., 2023e)率先将IT技术转移到MM领域。针对数据稀缺问题,LLaVA引入了一个使用ChatGPT/GPT-4创建的新型开源MM指令遵循数据集,以及MM指令遵循基准LLaVA-Bench。 (4)MiniGPT-4(Zhu et al., 2023a)提出了一种简化的方法,其中训练一个线性层就可以将预训练的视觉编码器与LLM对齐。这种高效的方法使得复制GPT-4展示的能力成为可能。 (5)mPLUG-Owl(Ye et al., 2023)提出了一种用于MM-LLMs的新型模块化训练框架,纳入了视觉上下文。为了评估不同模型在MM任务中的表现,该框架包括了一个名为OwlEval的指令评估数据集。 (6)X-LLM(Chen et al., 2023b)扩展到了包括音频在内的多种模态,并展示出强大的可扩展性。利用Q-Former的语言转移能力,X-LLM在汉藏语系中文环境下成功应用。 (7)VideoChat(Li et al., 2023d)是首个高效的面向聊天的视频理解对话MM-LLM,为该领域未来研究树立了标准,并为学术界和工业界提供了协议。 (8)InstructBLIP(Dai et al., 2023)基于预训练的BLIP-2模型进行训练,在MM IT过程中仅更新Q-Former。通过引入指令感知的视觉特征提取和相应指令,该模型能够提取灵活多样的特征。 (9)PandaGPT(Su et al., 2023)是首个通用型模型,能够理解和执行跨6种不同模态的指令:文本、图像/视频、音频、热成像、深度和惯性测量单元。 (10)PaLIX(Chen et al., 2023g)使用混合的VL目标和单模态目标(包括前缀补全和掩蔽标记补全)进行训练。这种方法对于下游任务结果和微调设置中实现帕累托前沿都证明是有效的。 (11)Video-LLaMA(Zhang et al., 2023e)引入了一个多分支跨模态PT框架,使LLMs能够同时处理给定视频的视觉和音频内容,并与人类进行对话。这个框架将视觉与语言以及音频与语言对齐。 (12)Video-ChatGPT(Maaz et al., 2023)是专门为视频对话设计的模型,能够通过整合时空视觉表征来生成关于视频的讨论。 (13)Shikra(Chen et al., 2023d)引入了一个简单且统一的预训练MM-LLM,专为参考对话任务而设计,涉及对图像中的区域和对象的讨论。这个模型展示了值得称赞的泛化能力,有效地处理了未见设置。 (14)DLP(Jian et al., 2023)提出P-Former来预测理想提示,基于单模态句子的数据集进行训练。这证明了单模态训练提高MM学习的可行性。 (15)BuboGPT(Zhao et al., 2023d)是通过学习共享语义空间构建的模型,用于全面理解MM内容。它探索了图像、文本和音频等不同模态之间的细粒度关系。 (16)ChatSpot(Zhao et al., 2023b)引入了一种简单而强大的方法,用于微调精确的指代指令以便于MM-LLM,促进细粒度交互。精确的指代指令的纳入,包括图像和区域级指令,增强了多粒度VL任务描述的整合。 (17)Qwen-VL(Bai et al., 2023b)是一个支持英语和中文的多语言MM-LLM。Qwen-VL还允许在训练阶段输入多个图像,提高了其理解视觉上下文的能力。 (18)NExT-GPT(Wu et al., 2023d)是一个端到端、通用的任意到任意MM-LLM,支持图像、视频、音频和文本的自由输入和输出。它采用了轻量级对齐策略,在编码阶段使用以LLM为中心的对齐,在解码阶段使用指令遵循对齐。 (19)MiniGPT-5(Zheng et al., 2023b)是一个与生成voken的反演和与稳定扩散的整合的MM-LLM。它擅长执行交错的VL输出以用于MM生成。训练阶段包括无分类器引导,提高了生成质量。 有关剩余七个MM-LLMs的介绍,请参阅附录D,其中包括(20)LLaVA-1.5(Liu et al., 2023d),(21)MiniGPT-v2(Chen et al., 2023c),(22)CogVLM(Wang et al., 2023),(23)DRESS(Chen et al., 2023h),(24)XInstructBLIP(Panagopoulou et al., 2023),(25)CoDi-2(Tang et al., 2023a),以及(26)VILA(Lin et al., 2023)。
结论
在本文中,我们提供了一份关于多模态大型语言模型(MM-LLMs)的全面综述,重点关注了近期的进展。起初,我们将模型架构分类为五个部分,提供了一般设计公式和训练流程的详细概述。随后,我们介绍了各种最新的MM-LLMs,每个都有其特定的公式化特征。我们的综述还阐明了这些模型在多种多模态基准测试中的能力,并展望了这一快速发展领域的未来发展。我们希望这份综述能为研究人员提供洞见,为MM-LLMs领域的持续进步做出贡献。
