

文本分类是自然语言处理中最基本和最重要的问题。虽然许多最近的文本分类模型应用了序列深度学习技术,但基于图神经网络的模型可以直接处理复杂的结构化文本数据,并利用全局信息。许多实际的文本分类应用可以自然地转换为图形,捕捉单词、文档和语料库的全局特征。在本调查中,我们将方法的覆盖范围扩展到2023年,包括语料库级别和文档级别的图神经网络。我们详细讨论了这些方法,处理了图构建机制和基于图的学习过程。除了技术调查外,我们还关注了使用图神经网络进行文本分类所涉及的问题背后和未来方向。我们还涵盖了数据集、评估指标、实验设计,并提供了在公开可用基准测试中发布的性能总结。请注意,我们在本调查中对不同技术进行了全面比较,并确定了各种评估指标的优缺点。
1. 引言
文本分类旨在将给定文档分类到某些预定义的类别中,被认为是自然语言处理(NLP)中的基本任务。它包括许多下游任务,如主题分类[141]和情感分析[108]。传统的文本分类方法使用N-gram[15]或词频-逆文档频率(TF-IDF)[33]对文本进行表示,并应用传统的机器学习模型(如SVM[41])对文档进行分类。随着神经网络的发展,更多的深度学习模型已经应用于文本分类,包括卷积神经网络(CNN)[47]、循环神经网络(RNN)[109]、基于注意力机制的模型[114]以及大型语言模型[23]。然而,这些方法要么无法处理单词与文档之间的复杂关系[133],要么无法有效地探索上下文感知的词汇关系[143]。为了解决这些障碍,引入了图神经网络(GNN)。GNN用于图结构数据集,因此需要为文本分类构建图。构建图有两种主要方法:语料库级别的图和文档级别的图。数据集可以构建为表示整个语料库的单个或多个语料库级别的图,也可以构建为众多文档级别的图,每个图代表一个文档。语料库级别的图可以捕获整个语料库的全局结构信息,而文档级别的图可以明确地捕获文档内单词与单词之间的关系。两种将图神经网络应用于文本分类的方法都取得了良好的性能。 本文主要关注基于图神经网络(GNN)的文本分类技术、数据集及其性能。对于语料库级别和文档级别的图表构建方法都进行了详细介绍。以下几个方面的论文将被回顾:
基于GNN的文本分类技术 用于文本分类的数据集 GNN方法的性能评估 语料库级别和文档级别图表的构建方法
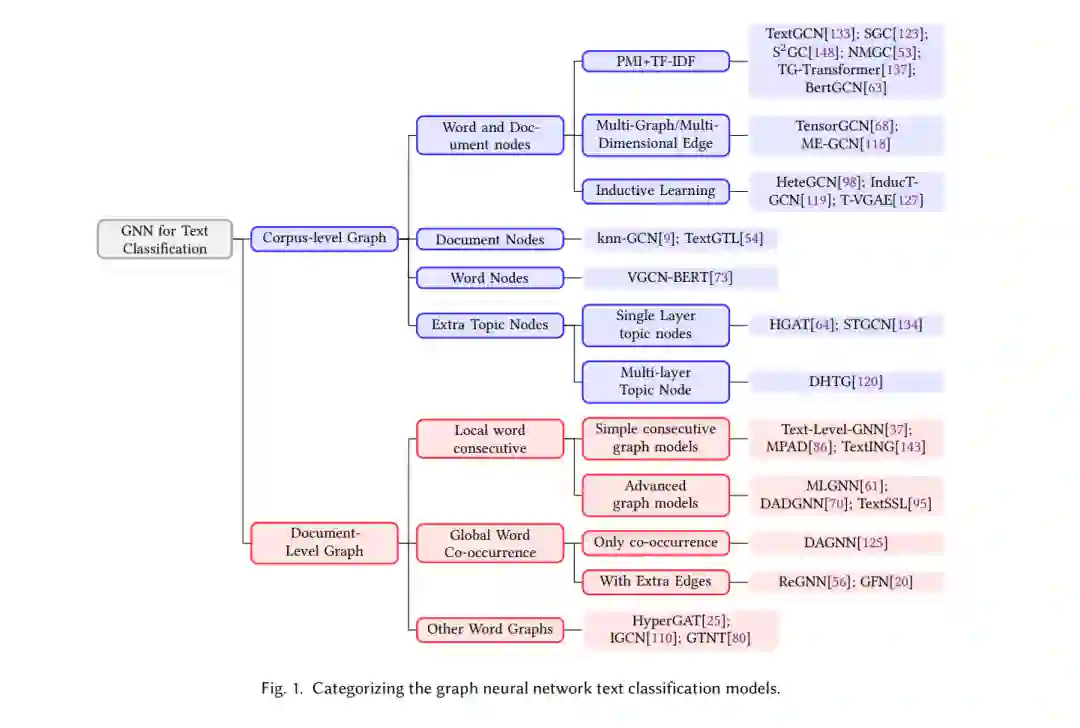
在2019年之前,文本分类综述论文[2, 35, 46, 116, 129]主要关注传统的基于机器学习的文本分类模型。最近,随着深度学习技术的快速发展,[55, 82, 147, 149] 回顾了各种基于深度学习的方法。此外,一些论文不仅回顾了SoTA模型结构,还总结了整个工作流程[10, 39, 42, 49, 83],或者用于文本分类的特定技术,如词嵌入[102],特征选择[22, 96, 103],词项加权[3, 91]等。同时,一些不断发展的潜在文本分类结构也得到了调查,如CNNs [132],注意力机制[78]。由于具有表示非欧几里得关系的强大能力,图神经网络(GNN)已经应用于多个实际领域并得到了评估,例如金融应用[117],交通预测[72],生物信息学[142],电力系统[60],推荐系统[27, 59, 131]。此外,[8, 14, 126, 139, 144]全面回顾了GNN的通用算法和应用,以及一些主要关注特定视角的调查,包括图构建[105, 112],图表示[34],训练[128],池化[65]等。然而,只有[55, 82]简要介绍了一些SoTA基于GNN的文本分类模型。最近的一篇简短综述论文[75]回顾了几个SoTA模型,但没有提供该领域的全面概述。本次调查的贡献包括: • 这是第一篇专注于图神经网络用于文本分类的综述,对超过二十种GNN文本分类模型进行了全面描述和关键性讨论。 • 我们将现有的GNN文本分类模型分为两个主要类别和多个子类别,所有模型的树结构显示在图1中。 • 我们从图构建、节点嵌入初始化和图学习方法三个方面对这些模型进行比较。我们还比较了这些模型在基准数据集上的性能,并讨论了关键发现。 • 我们讨论了GNN文本分类模型面临的现有挑战以及一些潜在的未来工作。1.2 文本分类任务 文本分类涉及为给定的文本序列分配预定义标签。该过程通常包括将预处理过的原始文本编码为数值表示,并使用分类器预测相应的类别。典型的子任务包括情感分析、主题标注、新闻分类和仇恨言论检测。某些框架可以扩展到高级应用,如信息检索、摘要、问答和自然语言推理。本文专注于用于典型文本分类的基于GNN的模型。 • 情感分析是一项旨在识别输入文本(如评论、微博等)中表达的情感状态和主观观点的任务。这可以通过二分类或多分类实现。有效的情感分析可以帮助根据用户反馈做出明智的商业决策。 • 主题分类是一种监督深度学习任务,用于自动理解文本内容并将其分类为多个特定领域的类别,通常多于两个。数据来源可能来自不同领域,包括维基百科页面、报纸、科学论文等。 • 垃圾信息检测涉及检测不当的社交媒体内容。社交媒体提供商通常使用诸如仇恨言论、辱骂性语言、广告或垃圾邮件检测等方法,以高效地消除此类内容。
1.3 文本分类发展
许多传统的机器学习方法和深度学习模型被选作与基于GNN的文本分类器进行比较的基线。我们主要将这些基线归纳为三种类型:
传统机器学习:在早期,诸如支持向量机(SVM)[140]和逻辑回归[29]等传统方法采用词袋(BoW)和TF-IDF等稀疏表示。然而,最近的进展[62, 99, 135]关注稠密表示,如Word2vec、GloVe和Fasttext,以减轻稀疏表示的局限性。这些密集表示还被用作复杂方法的输入,例如深度平均网络(DAN)[38]和段落向量(Doc2Vec)[51],以实现新的最先进结果。
序列模型:RNN和CNN已被用于捕获输入文本主体中连续单词的局部语义和句法信息。已经提出了升级模型,如LSTM [31]和GRU [17],以解决由普通RNN引起的消失或爆炸梯度问题。基于CNN的结构已应用于通过一个或多个卷积和池化层捕获N-gram特征,例如Dynamic CNN [43]和TextCNN [47]。然而,这些模型只能捕获连续单词的局部依赖关系。为了捕捉长期或非欧几里得关系,提出了改进的RNN结构,如Tree-LSTM [108]和MT-LSTM [66],以及全局语义信息,如TopicRNN [24]。此外,还提出了图[92]和树结构[84]增强的CNN,以了解更多关于全局和长期依赖关系。
注意力和Transformers:注意力机制[6]已被广泛采用以捕获长距离依赖关系,如层次注意力网络[1]和基于注意力的混合模型[132]。基于自注意力的Transformers模型通过在某些任务上进行预训练以生成强大的上下文单词表示,在许多文本分类基准上实现了最先进的性能。然而,这些模型只关注学习输入文本主体之间的关系,而忽略了全局和语料库级别的信息。研究人员已经提出将注意力机制和图神经网络(GNN)的优势相结合,以学习输入文本主体之间的关系以及全局和语料库级别的信息,例如VGCN-BERT [73]和BERTGCN [63]。
1.4 大纲
本综述的大纲如下: • 第1节提出了研究问题,并概述了将图神经网络应用于文本分类任务,以及本综述的范围和组织结构。 • 第2节提供了关于文本分类和图神经网络的背景信息,并从设计者的角度介绍了将GNN应用于文本分类的关键概念。 • 第3节和第4节分别讨论了语料库级图神经网络和文档级图神经网络的先前工作,并对这两种方法的优缺点进行了比较分析。 • 第5节介绍了GNN文本分类中常用的数据集和评估指标。 • 第6节报告了各种GNN模型在一系列文本分类基准数据集上的性能,并讨论了关键发现。 • 第7节讨论了现有方法的挑战和一些潜在的未来工作。 • 在第8节,我们总结了关于GNN文本分类的综述,并讨论了未来工作的潜在方向。
本文主要讨论GNN如何应用于文本分类任务。在介绍这一领域的具体应用之前,我们首先从设计人员的角度介绍将GNN应用于文本分类的关键概念。我们假设为了解决文本分类任务,需要设计一个图G=(V,E)。一般过程包括图的构建,初始节点表示,边表示,训练设置。
用于文本分类的语料库级GNN
我们将语料库级图神经网络定义为“构建一个图来表示整个语料库”,因此,对于给定的语料库,只会构建一个或多个图。根据图中显示的节点类型,将语料库级GNN分为四个子类。
用于文本分类的文档级GNN
通过对每个文档构建图,图分类模型可以作为文本分类模型。由于每个文档都由一个图表示,并且可以为测试文档构建新的图,因此该模型可以轻松地以归纳的方式工作。
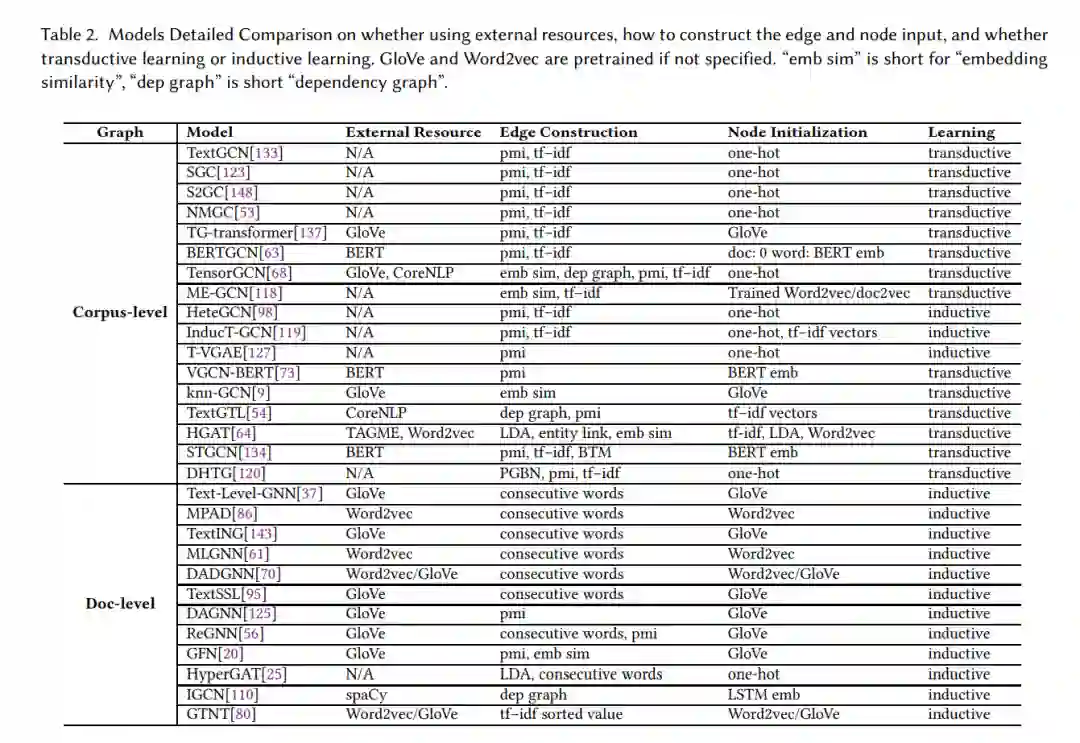
大多数文档级GNN将连续的单词作为图中的边连接起来,并应用图神经网络模型,这使它们类似于CNN,当图模型深入时,感受野会扩大。此外,文档级GNN之间的主要差异是图模型的细节,例如不同的池化方法和不同的注意力计算,这削弱了这些工作的贡献的影响。与语料库级GNN相比,文档级GNN采用更复杂的图模型,并且在文档中单词数量较大时存在内存不足的问题。表2展示了文档级GNN的详细比较。
数据集
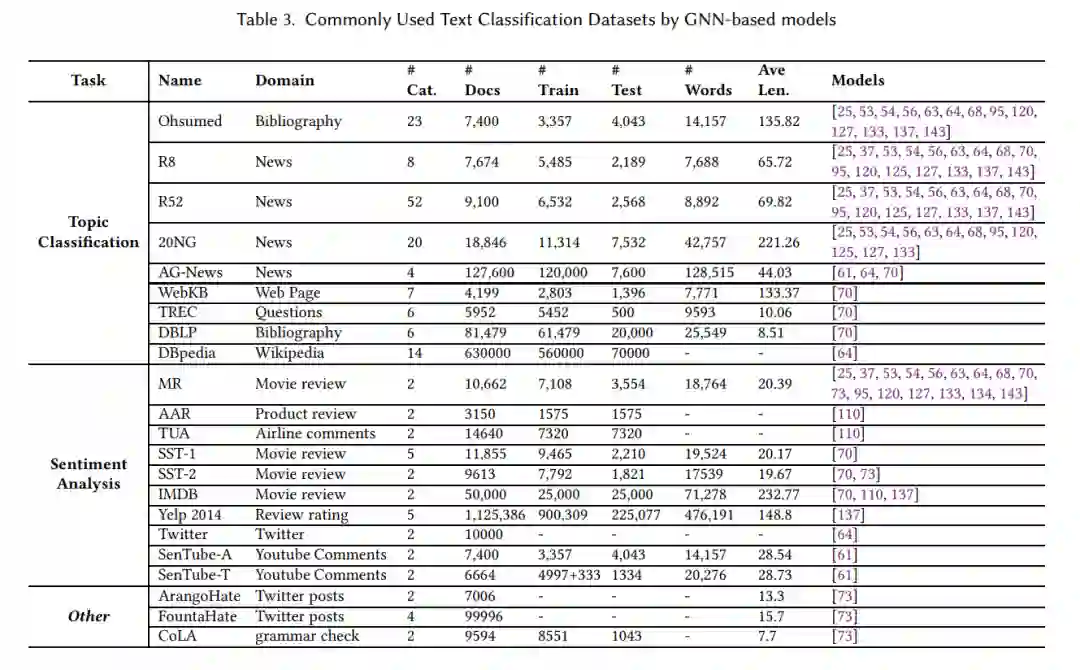
目前有许多流行的文本分类基准数据集,本文主要关注基于GNN的文本分类应用所使用的数据集。根据应用的目的,将常用的数据集分为主题分类、情感分析和其他三类。这些文本分类数据集大多只包含单个文本主体的目标标签。表3列出了每个数据集的关键信息
性能
虽然不同的GNN文本分类模型可能在不同的数据集上进行评估,但这些模型中有一些常用的数据集,包括20NG、R8、R52、Ohsumed和MR.在这五个数据集上评估的各种模型的准确性如表4所示。有些结果报告具有10倍的平均准确度和标准推导,而有些仅报告平均准确度。可以得出以下几个结论: 使用外部资源的模型通常比不使用外部资源的模型取得更好的性能,特别是使用BERT和RoBERTa的模型[63,134]。 在相同的设置下,例如使用GloVe作为外部资源,语料库级GNN模型(如TGTransformer[137], TensorGCN[68])通常优于文档级GNN模型(如text [143], TextSSL[95])。这是因为语料库级的GNN模型可以以直推式的方式工作,并利用测试输入,而文档级的GNN模型只能使用训练数据。 语料库级GNN模型相对于文档级GNN模型的优势仅适用于主题分类数据集,而不适用于情感分析数据集,如MR.这是因为情感分析涉及分析文本中单词的顺序,这是大多数语料库级GNN模型无法做到的。
结论
这篇综述文章介绍了图神经网络如何以两种不同的方式应用于文本分类:语料库级GNN和文档级GNN,并给出了详细的结构图。介绍并讨论了这些模型的细节,以及这些方法常用的数据集。与传统的机器学习和序列深度学习模型相比,图神经网络可以探索全局结构(语料库级GNN)或局部文档(文档级GNN)中单词和文档之间的关系,表现良好。通过比较外部资源、模型学习方法和不同数据集类型对模型性能的影响。提出了GNN文本分类模型面临的挑战和潜在的未来工作。

