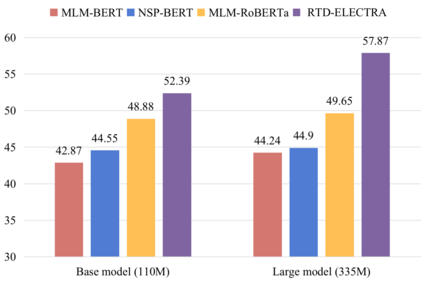
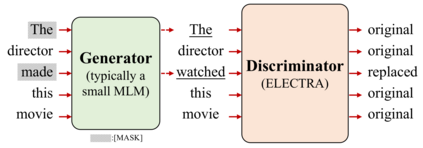
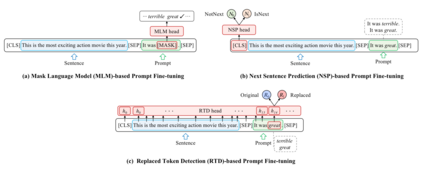
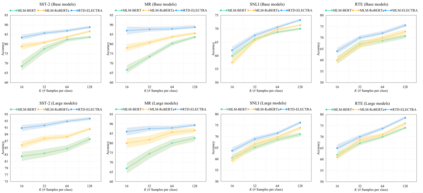
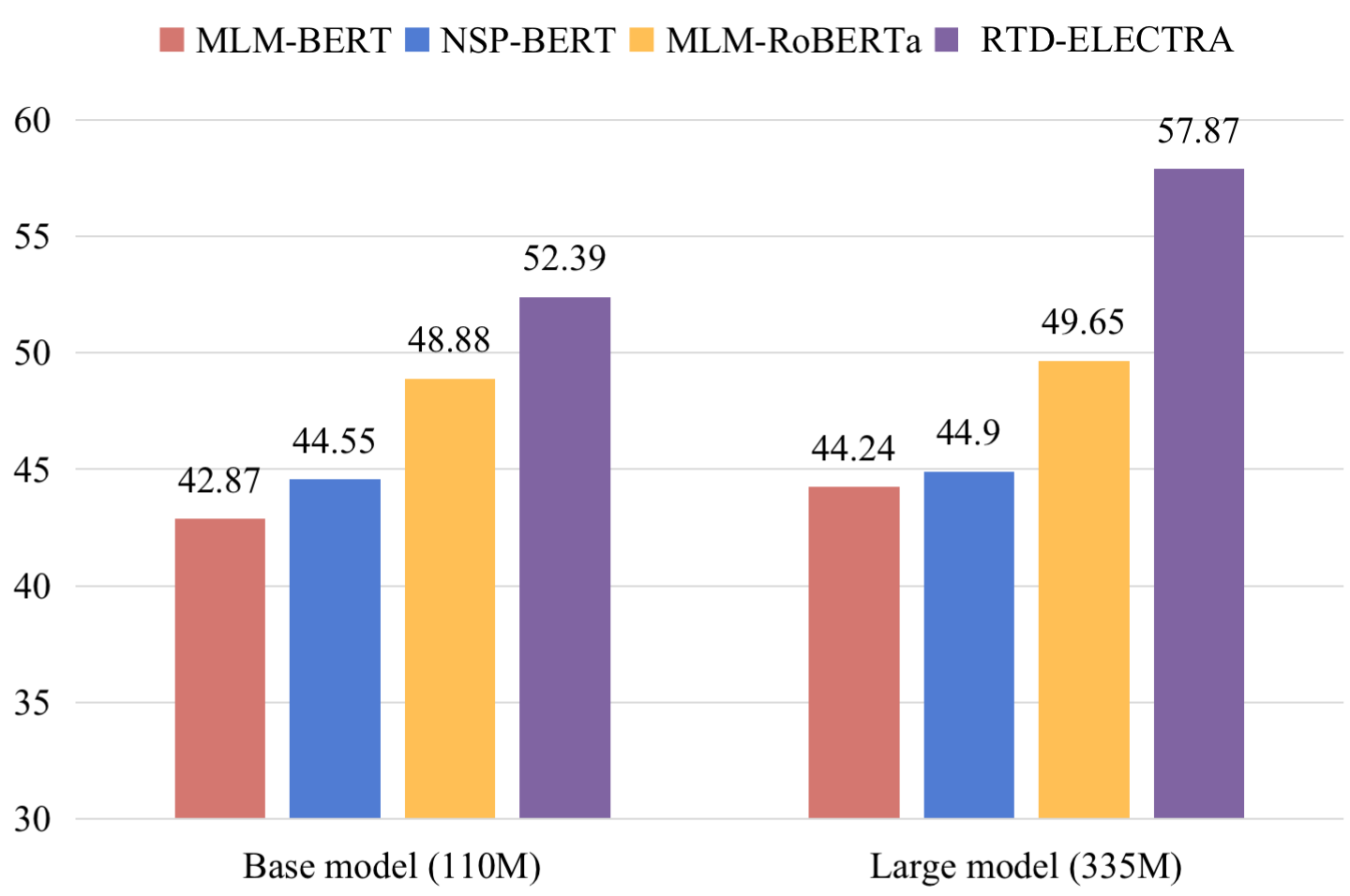
Recently, for few-shot or even zero-shot learning, the new paradigm "pre-train, prompt, and predict" has achieved remarkable achievements compared with the "pre-train, fine-tune" paradigm. After the success of prompt-based GPT-3, a series of masked language model (MLM)-based (e.g., BERT, RoBERTa) prompt learning methods became popular and widely used. However, another efficient pre-trained discriminative model, ELECTRA, has probably been neglected. In this paper, we attempt to accomplish several NLP tasks in the zero-shot scenario using a novel our proposed replaced token detection (RTD)-based prompt learning method. Experimental results show that ELECTRA model based on RTD-prompt learning achieves surprisingly state-of-the-art zero-shot performance. Numerically, compared to MLM-RoBERTa-large and MLM-BERT-large, our RTD-ELECTRA-large has an average of about 8.4% and 13.7% improvement on all 15 tasks. Especially on the SST-2 task, our RTD-ELECTRA-large achieves an astonishing 90.1% accuracy without any training data. Overall, compared to the pre-trained masked language models, the pre-trained replaced token detection model performs better in zero-shot learning. The source code is available at: https://github.com/nishiwen1214/RTD-ELECTRA.
翻译:最近,对于几发甚至零发的学习,新的范式“培训前、迅速和预测”与“培训前、微调、微调”范式相比,取得了显著成就。在以快速为基础的GPT-3成功之后,一系列以隐蔽语言模式(MLM)为基础的隐蔽语言模式(例如BERT、ROBERTA)获得了流行和广泛使用。然而,另一个高效的事先培训前歧视模式(ELECTRA)或许被忽略了。在本文中,我们试图利用我们提议的替代象征性检测(RTD)的零发式快速学习方法,在零发式情景中完成几项NLP任务。实验结果显示,基于RTD-Prompt学习的ELTRA模式取得了惊人的零发效(例如BERT、ROBERTA)模式。与M-ROBERTA大和MM-M-BERT模型相比,我们的RTD-ELTRA-GA模型在所有15个任务中平均有8.4%和13.7 %的改进源。特别是在SST-2号任务中,在STRA-S-TA-S-S-SLSLA 之前的升级的测试中,任何可改进的RTRA-S-I-S-S-S-ID-S-S-S-S-S-I-I-S-S-I-S-S-S-I-S-SD-SD-S-I-SD-S-SD-SD-SD-SD-SD-SD-SD-SD-SD-SD-SD-SD-SB-S-S-S-SD-S-S-S-S-S-S-S-S-S-S-S-S-S-I-S-S-S-S-S-I-S-I-I-SD-SD-SD-C-SD-SD-SD-I-SD-S-S-SB-I-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-I-I-S-S-I-I-S-I-I-S