数据中天然含有噪声,如何针对此进行处理?来自香港浸会大学等学者发布了最新《标签噪声表示学习》,进行了广泛的文献综述,从表示学习时代,并在数据、目标和优化方面将它们分类在一个统一的分类法。分析了不同分类的优缺点。
![]()
经典的机器学习隐含地假设训练数据的标签是从一个干净的分布中采样,这对于真实世界的场景来说可能太有限制性了。然而,基于统计学习的方法可能不能在这些嘈杂的标签下稳健地训练深度学习模型。因此,设计标签-噪声表示学习(Label-Noise Representation Learning, LNRL)方法对具有噪声标签的深度模型进行鲁棒训练迫在眉睫。为了充分了解LNRL,我们进行了一项调研研究。我们首先从机器学习的角度阐明了LNRL的形式化定义。然后,通过学习理论和实证研究的视角,我们找出了为什么嘈杂标签会影响深度模型的性能。在理论指导的基础上,我们将不同的LNRL方法分为三个方向。在这个统一的分类下,我们对不同类别的利弊进行了全面的讨论。更重要的是,我们总结了鲁棒LNRL的基本组成部分,可以激发新的方向。最后,我们提出了LNRL可能的研究方向,如新数据集、依赖实例的LNRL和对抗LNRL。我们还展望了LNRL以外的潜在方向,如特征噪声学习、偏好噪声学习、域噪声学习、相似噪声学习、图噪声学习和演示噪声学习。
https://www.zhuanzhi.ai/paper/3309c9681839f62b5932e97cfa1bc7f4
“学习算法如何处理不正确的训练样例?” 这是Dana Angluin在1988年[1]发表的题为“从嘈杂的例子中学习”的论文中提出的问题。她说,“当教师在对样本数据进行分类时可能会出现独立的随机错误时,为样本选择最一致的规则的策略就足够了,通常需要的样本数量非常少,而且噪声平均影响不到一半的样本”。换句话说,她声称学习算法可以处理不正确的训练例子,只要噪声率小于随机噪声模型的一半。在过去30年里,她的开创性研究为机器学习打开了一扇新的大门,因为标准的机器学习假设标签信息是完全干净和完整的。更重要的是,她的研究呼应了现实环境,因为标签或注释在现实场景中往往是嘈杂和不完美的。
例如,深度学习的热潮始于2012年,因为Geoffrey Hinton的团队利用AlexNet(即深度神经网络)[2],以明显的优势赢得了ImageNet挑战[3]。然而,由于数据量巨大,ImageNet-scale数据集必然是由Amazon Mechanical Turk 1中的分布式工作人员标注的。在有限的知识范围内,分布式工作人员无法以100%的准确性标注特定的任务,这自然会带来噪音标签。另一个生动的例子是在医疗应用中,这里的数据集通常很小。然而,对医疗数据进行标签需要领域专业知识,而这些数据往往存在观察者之间和观察者内部的高度可变性,从而导致标签的噪声。我们应该注意到,嘈杂的标签会导致错误的模型预测,这可能会进一步影响对人类健康产生负面影响的决策。最后,噪声标签在语音领域中是普遍存在的,例如,互联网协议语音(VoIP)呼叫[4]。特别是,由于网络条件不稳定,VoIP呼叫很容易出现各种语音障碍,这需要用户的反馈来确定原因。这种用户反馈可以被看作是原因标签,这是高度嘈杂的,因为大多数用户缺乏领域专业知识来准确地表达所感知的语言中嘈杂。
以上这些噪声标签的案例都源于我们的日常生活,这是不可避免的。因此,迫切需要建立一种具有理论保证的鲁棒学习算法来处理带噪声的标签。在这篇综述论文中,我们将这种鲁棒学习范式称为标签噪声学习(label-noise learning),
噪声训练数据(x, y¯)是从一个损坏的分布p(x, y¯)中采样的,在那里我们假设特征是完好的,但标签是损坏的。据我们所知,标签噪声学习在机器学习中跨越了两个重要的阶段:统计学习(即浅层学习)和表示学习(即深度学习)。在统计学习时代,标签噪声学习专注于设计噪声耐受损失或无偏风险估计器[5]。然而,在表示学习的时代,标签噪声学习有更多的选择来对抗噪声标签,如设计有偏的风险估计器或利用深度网络[6],[7]的记忆效应。
标签噪声表示学习已经成为学术界和工业界非常重要的学习方法。
背后有两个原因。首先,从学习范式的本质来看,深度监督学习需要大量标签良好的数据,这可能需要太多的成本,特别是对于许多初创企业。然而,深度无监督学习(甚至是自我监督学习)太不成熟,不能很好地在复杂的现实世界场景中工作。因此,作为深度弱监督学习,标签-噪声表示学习自然引起了人们的关注,成为研究的热点。其次,从数据方面来看,许多现实世界的场景都缺乏纯粹的注释,比如金融数据、web数据和生物医学数据。这些都直接激发了研究人员去探索标签-噪声表示学习。
据我们所知,我们确实存在三个关于标签噪音的先前综述。Frenay和Verleysen[8]重点讨论了标签噪声统计学习,而不是标签噪声表示学习。虽然Algan et al.[9]和Karimi et al.[10]专注于带噪声标签的深度学习,但他们都只考虑图像(或医学图像)分类任务。此外,他们的调研是从应用的角度写的,而不是讨论方法及其背后的理论。为了弥补它们并超越它们,我们希望对标签-噪声表示学习领域做出如下贡献。
从机器学习的角度,我们给出了标签噪声表示学习(LNRL)的形式化定义。这个定义不仅具有足够的普遍性,可以涵盖现有的LNRL,而且具有足够的特殊性,可以明确LNRL的目标是什么以及我们如何解决它。
通过学习理论的视角,我们提供了一个更深入的理解为什么噪声标签影响深度模型的性能。同时,我们报告了噪声标签下深层模型的概括,这与我们的理论理解一致。
我们进行了广泛的文献综述,从表示学习时代,并在数据、目标和优化方面将它们分类在一个统一的分类法。分析了不同分类的优缺点。我们还对每个类别的见解进行了总结。
基于上述观察,我们可以在标签-噪声表示学习中提出新的方向。除了标签噪声表示学习,我们提出了几个有前途的未来方向,如学习噪声特征、偏好、领域、相似性、图形和演示。我们希望他们能提供一些见解。
![]()
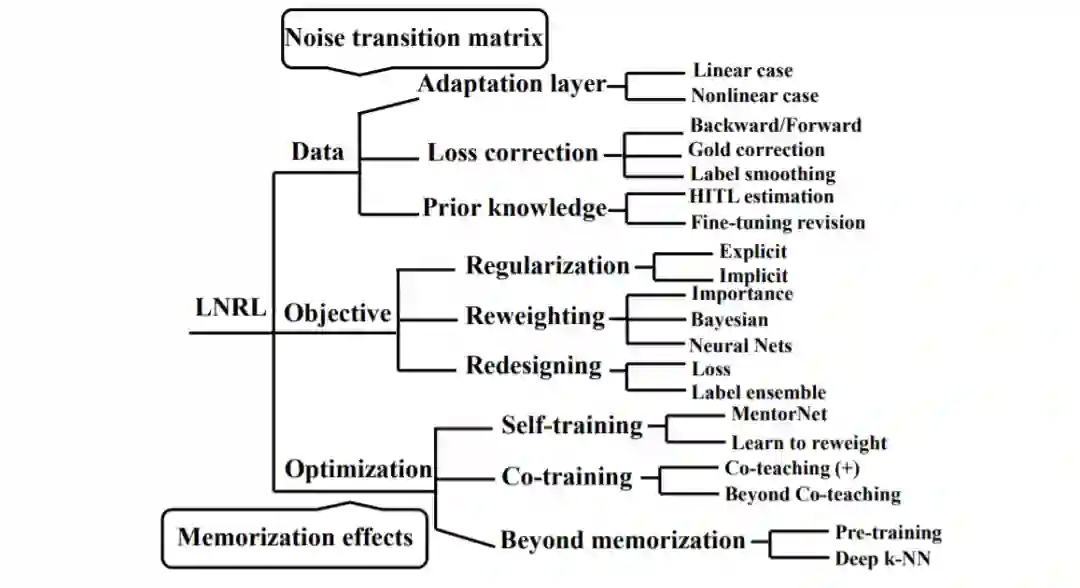
根据每种方法的重点对LNRL进行分类。对于每个技术分支,我们在这里列出了一些有代表性的工作。
基于上述理论理解,我们将这些工作分为三个大致的方面:
数据:从数据的角度来看,关键是建立噪声转移矩阵T,探索干净标签和有噪标签之间的数据关系。本节的方法通过估计噪声转移矩阵来解决LNRL问题,它建立了潜在的干净标签和观察到的噪声标签之间的关系。首先,我们解释什么是噪声转移矩阵和为什么这个矩阵是重要的。然后,我们介绍了利用噪声转移矩阵对抗标签噪声的三种常用方法。第一种方法是在端到端深度学习系统中利用一个适应层来模拟噪声转移矩阵,它桥接了潜在的干净标签和观察到的噪声标签。第二种方法是根据经验估计噪声转移矩阵,并利用估计矩阵进一步修正交叉熵损失。最后,第三种方法是利用先验知识来减轻估计负担。
目标函数:本节中的方法通过修改目标函数()来解决LNRL问题,修改可以通过三种不同的方式来实现。第一种方法是通过显式正则化或隐式正则化直接增广目标函数。注意,隐式正则化倾向于在算法层面上进行操作,相当于修改目标函数。第二种方法是对不同的目标子函数赋动态权值,权值越大,对应的子函数的重要性越高。最后一种方法是直接重新设计新的损失函数。
优化策略:本节将通过改变优化策略(如提前停止)来解决LNRL问题。深度神经网络的记忆效应在一定程度上避免了噪声标签的过拟合。使用记忆效果的噪音标签,还有另外一种可能更好的方法,那就是小损失技巧。本节的结构安排如下: 首先,我们解释什么是记忆效应以及为什么这种现象很重要。然后,我们介绍几种常用的方法来利用记忆效果来对抗标签噪音。第一个常见的方法是通过小损失的技巧自我训练单一的网络,这给我们带来了MentorNet[6]和Learning to Reweight[24]。此外,第二种常用的方法是通过小损失技巧稳健地对两个网络进行共训练,得到Co-teaching[7]和Co-teaching+[87]。最后,有几种方法可以进一步提高协同教学的性能,如交叉验证[88]、自动学习[82]和高斯混合模型[37]。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取70000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取70000+AI主题知识资源