

摘要
多智能体强化学习 (RL) 解决了每个智能体应该如何在多个智能体同时学习的随机环境中表现最佳的问题。它是一个历史悠久的跨学科领域,位于心理学、控制理论、博弈论、强化学习和深度学习的联合领域。继 AlphaGO 系列在单智能体 RL 中取得显著成功之后,2019 年是蓬勃发展的一年,见证了多智能体 RL 技术的重大进步;在开发许多具有挑战性的任务(尤其是多人视频游戏)上,胜过人类的人工智能已经取得了令人瞩目的突破。尽管如此,多智能体 RL 技术的主要挑战之一仍是可扩展性。设计高效的学习算法来解决包括远多于两个智能体 (N2) 的任务仍然不是一件容易的事,我将其命名为大量智能体强化学习 (many-agent reinforcement learning,MARL) 问题。
在本论文中,我从四个方面对解决MARL问题做出了贡献。首先,我从博弈论的角度提供了多智能体 RL 技术的独立概述。该概述填补了大多数现有工作要么未能涵盖自 2010 年以来的最新进展,要么没有充分关注博弈论的研究空白,我认为博弈论是解决多智能体学习问题的基石。其次,我在多智能体系统中开发了一种易于处理的策略评估算法——
除了算法开发之外,我还贡献了 MARL 技术的两个实际应用。具体来说,我展示了MARL的巨大应用潜力, 研究了自然界中涌现的人口动态,并为自动驾驶中的多样化和现实交互建模。这两个应用程序都体现了 MARL 技术可以在纯视频游戏之外的真实物理世界中产生巨大影响的前景。
MARL的重大挑战
与单智能体 RL 相比,多智能体 RL 是一个通用框架,可以更好地匹配现实世界 AI 应用的广泛范围。然而,由于存在同时学习的多个智能体,除了单智能体 RL 中已经存在的那些之外,MARL 方法还提出了更多的理论挑战。与通常有两个智能体的经典 MARL 环境相比,解决大量智能体 RL 问题更具挑战性。事实上,1 组合复杂性、2 多维学习目标、3 非平稳性问题,都导致大多数 MARL 算法能够解决只有两个玩家的博弈,特别是两个玩家的零和博弈。
本文的结构及贡献
本论文主要围绕大量智能体强化学习的研究课题。我为这个主题贡献的方法位于图 1.8 中列出的三个研究领域:它们是博弈论,它提供了现实且易于处理的解决方案概念来描述大量智能体系统的学习结果; RL 算法,提供可证明的收敛学习算法,可以在顺序决策过程中达到稳定和合理的均衡;最后是深度学习技术,它提供了学习算法表达函数逼近器。
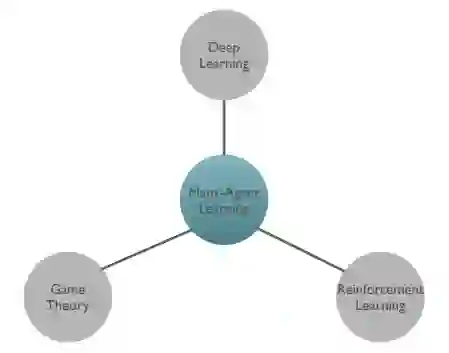
图 1.8:本论文的研究范围包括三个支柱。深度学习是学习过程中强大的函数逼近工具。博弈论提供了一种描述学习成果的有效方法。 RL 提供了一种有效的方法来描述多智能体系统中智能体的激励。

图 1.9:本文后续章节的结构,与列出的三个挑战(1 组合复杂性、2 多维学习目标、3 非平稳性)相关,每章都试图解决这些挑战。
以下各章的结构和贡献如下(另请参见图 1.9):
-
第 2 章:由于 MARL 的可扩展性问题深深植根于其博弈论基础,在本章中,我将首先概述现代 MARL 方法的博弈论方面,以及最近的进展。我相信这个概述是对社区的重要贡献,因为大多数现有调查要么不关注博弈论,要么就遗漏了自 2010 年以来的大多数近期文献而过时。第 1 章和第 2 章构成了 MARL 的独立专著。该专著的目标是从博弈论的角度对当前最先进的 MARL 技术进行专门评估。我希望这项工作能够为即将进入这个快速发展领域的新研究人员和想要获得全景,并根据最新进展确定新方向的现有领域专家提供基础。
-
第 3 章:本章提供了 MARL 技术在理解 AI 智能体的新兴种群动态方面的应用。本章的目标是在我介绍方法学发展之前作为开篇,展示 MARL 方法的巨大潜力。具体来说,在这项工作中,我将 RL 智能体放入模拟的捕食者-猎物世界中,并验证自然界中开发的原理是否可用于理解人工创造的智能种群,反之亦然。这项工作的主要贡献在于,它启发了许多人口生物学家和计算生物学家,在对宏观生物学研究中的自利智能体进行建模时,为他们提供了一种基于 MARL 的新方法。
-
第 4 章:本章介绍了一种新的大量智能体系统策略评估方法:
。
是 α-rank 的随机变体,是一种新颖的解概念,在多人广义和博弈中具有多项式时间解。
的一个主要好处是,人们现在可以轻松地评估大型多智能体系统(即多人广义和博弈),例如,具有
联合策略配置文件的多智能体系统只需一台机器;这与计算纳什均衡相反,即使在两人的情况下,这也是众所周知的 PPAD-hard。
-
第 5 章:在本章中,我将重点解决大量智能体系统中策略学习的核心问题。具体来说,我提出了平均场 MARL (MFMARL) 方法,该方法利用了物理学中平均场近似的经典思想。 MF-MARL 通过仅考虑总体的平均效应,有效地将大量智能体学习问题转化为双智能体问题。使用 MF-MARL 方法,可以有效地训练数百万智能体来解决大型合作博弈。我测试了 MF-MARL 算法来解决 Ising 模型,这是一个众所周知的物理学难题,因为它的组合性质,并得出了第一个基于 MARL 的 Ising 模型解。总的来说,本章的主要贡献是提供了第一个可证明收敛的可扩展 MARL 算法,并证明了它在远不止两个智能体的场景中的有效性。
-
第 6 章:本章研究开放式元博弈(即策略级别的博弈,也称为联盟训练或自动课程)中的大量智能体学习问题,其中行为多样性是一个关键但尚未充分探索的主题。本章为策略空间中的行为多样性提供了第一个数学上严格的定义,并提出了被证明可以在策略训练期间扩大多样性的学习算法。零和博弈的经验结果表明,所提出的方法在很大程度上优于现有的最新技术。这项研究可能会产生重大的经济影响,因为所提出的算法可以直接插入到开发游戏 AI 的联盟训练中(例如,训练能够在扑克游戏中击败人类玩家的 AI 群体)。
-
第 7 章:除第3章外,本章介绍MARL的第二种应用,即自动驾驶(AD)。我展示了使用 MARL 技术来模拟 AD 中现实和多样化的多智能体交互的巨大潜力。具体来说,我介绍了 SMARTS 平台:第一个专门支持 RL 和 MARL 训练的 AD 模拟器。基于 SMART,我分享了一个蓝天理念,即在 MARL 中创建多样化的自动课程是在 AD 中建模现实交互的关键。我详细阐述了多样化自动课程的必要性,并列出了应用这种技术的四个开放挑战。本章的贡献有两方面:首先,我展示了 MARL 技术可以在真实的物理世界中产生有影响力的应用,而不是纯粹的视频游戏;其次,我向 AD 中的研究人员介绍了一种新方法,以便他们能够生成当前缺失的高质量交互。
-
第8章:在最后一章中,我总结了这篇论文,并提出了四个未来的研究方向;它们是深度 MARL 理论、安全鲁棒的 MARL、基于模型的 MARL 和多智能体元 RL。
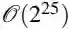 联合策略配置文件的多智能体系统只需一台机器;这与计算纳什均衡相反,即使在两人的情况下,这也是众所周知的 PPAD-hard。
联合策略配置文件的多智能体系统只需一台机器;这与计算纳什均衡相反,即使在两人的情况下,这也是众所周知的 PPAD-hard。








