
这项研究的目的是讨论目前最先进的在点云数据上执行的机器学习算法的方法。所进行的研究将应用于三维激光雷达可视化和开发(3DLIVE)团队的内部工作,其主要目标是为目标坐标测量(TCM)创建一个可视化和与点云数据互动的新系统。所提出的机器学习方法与三维点云和计算机视觉的机器学习的三个主要课题有关,每个课题都有自己研究的论文部分。这些主题是分割、分类和目标检测,所选的论文是最近的研究,取得了最先进的性能。这项研究的结果是选定的几种方法,它们向3DLIVE团队展示了最有希望的结果和有效性。有效性在很大程度上取决于算法对3DLIVE使用案例的可扩展性和适用性,以及其准确性和精确性。


引言
在传统的计算机视觉问题中,二维数据一直是用于推理的主要信息形式。随着近来价格低廉且广泛使用的3D传感器(如苹果深度相机、Kinect和飞行时间相机)的发展,3D数据已经变得非常丰富,并为解决计算机视觉问题提供了许多优势。也就是说,它包含了更多的拓扑信息(深度维度、形状和比例信息),这些信息对场景的理解至关重要,并提供了一个更自然的世界表现。由于这一技术层面的原因,将三维数据应用于自动驾驶、机器人、遥感和医疗等领域已经成为近期研究的重点,并将继续扩展到其他领域[1]。
三维数据可以有很多格式,包括网格、深度图像、体积网格和点云。场景理解应用中最常见的格式是点云-结构化数据,因为这种数据形式保留了三维空间中的原始几何信息,没有任何离散化损失。在进行分析之前,需要对点云进行定义:点云是一组数据点(x,y,z),通常代表一个(多个)三维物体的外表面,由合成或三维扫描器产生。三维数据面临的一个挑战是存储要求--三维场景比二维的同一场景需要多出几个数量级的存储。点云解决了这个问题,因为它不需要存储多边形网格,因此提高了性能并降低了开销--这是对时间敏感的应用的关键考虑[2]。
三维LiDAR可视化和开发(3DLIVE)项目旨在为目标坐标测量(TCM)和三维分析创建一个新系统。目前的TCM方法使用立体图像,利用英伟达3D视觉眼镜以及专门的GPU和显示器来查看重叠的二维图像,给人一种三维的感觉。然而,这种方法很难训练,而且会造成眼睛疲劳;此外,它所使用的英伟达软件和硬件已经达到了使用寿命的终点,不再得到支持或生产。因此,需要开发一种新的3D数据开发解决方案。
用于TCM的3DLIVE方法旨在利用主要由LiDAR传感器收集的3D点云。然后使用游戏引擎Unity将这些数据可视化。此外,由于上述数据可以通过Octree格式有效地加载到Unity中,因此可以使用大规模的数据集。点的元数据信息可以在查看器中查看和分析,用户可以在整个大的地理区域内导航并选择点进行分析。有多种方法可以与数据互动,从在某一地点投放一个感兴趣的点到测量距离、长度和面积。
有多种模式可以与3D点云数据互动。它们包括标准的鼠标和键盘、虚拟现实和增强现实(使用Hololens 2)。增强现实的互动是3DLIVE团队的主要开发重点,因为它使用户沉浸在数据中,同时仍然类似于立体眼镜的方法。我们目前还在寻求使用机器学习(ML),使我们能够自动获得这些点云数据集中的物体信息,例如它们是什么物体,在空间内有什么界限,并进行自动目标识别(ATR)。
在过去的10-20年里,大多数深度学习计算机视觉研究都集中在2D图像上,但随着更多可用的3D数据的兴起,最近的研究着眼于将传统的深度学习技术应用于计算机视觉的3D数据。这项新的研究使得场景理解的场景有了重大的进展,但是在将模型从二维过渡到三维的过程中,仍然存在着一些障碍。具体到点云,数据是非结构化和无序的,这意味着以点云为输入的深度学习网络不能直接应用标准的深度学习方法,如卷积神经网络(CNN)[1]。相反,必须开发定制的解决方案,使其具有包络不变性,通常用对称函数实现。另一个挑战是从点云中捕捉局部和全局结构信息。通过单个点来评估点云会失去点与点之间的局部和整体结构信息,因此网络在设计时必须通过查看邻近的数据来考虑这一点。由于直接处理点云的困难,许多方法将点云数据转化为一种中间格式,如将点云投影到二维图像中,这样就可以应用传统的深度学习方法[1]。最后,从三维传感器收集的点云数据并不完美--由于传感器的局限性,采集设备的固有噪声,以及被采集表面的反射性质,往往存在噪声污染和异常值,会破坏数据采集[1]。从上面可以看出,在点云数据上应用深度学习方法并不简单,需要对现有的技术进行重新设计,以便在网络中使用,但是三维点云比二维数据的描述能力的提升超过了负面因素。
计算机视觉任务通常被分成3个不同的类别:分类、目标检测和分割。对于点云,这些类别通常被定义为: 三维形状分类,三维目标检测和跟踪,以及三维点云分割[1]。
三维形状分类方法试图通过首先学习每个点的嵌入,然后使用聚合方法从整个点云中提取一个全局形状嵌入,来对点云中的物体进行分类(标记)。这个全局嵌入被输入到几个完全连接的层中以实现分类[1]。
三维目标检测和跟踪方法可以分为3类: 1)目标检测,2)物体跟踪,以及3)场景流估计。对于目标检测方法,它们在每个检测到的物体周围为输入的点云产生定向的三维边界盒。接下来,三维物体跟踪的目的是预测物体的状态,因为它以前的状态。与物体跟踪相关的是三维场景流估计,即给定同一场景在两个不同时刻的两个点云,描述每个点从第一个点云到第二个点云的运动[1]。
与目标检测和跟踪一样,三维点云的分割也可以根据所需的粒度分为三类。这些类别从最普遍到最不普遍:语义分割(场景级别)、实例分割(物体级别)和部分分割(部分级别)。给定一个点云,三维点云语义分割的目标是根据点的语义将点云分成几个子集(例如,将场景中的所有椅子涂成相同的颜色)。更低一级的是三维点云实例分割,它比语义分割更具挑战性,因为它需要对点进行更准确和精细的推理。实例分割不仅需要区分具有不同语义的点,还需要区分具有相同语义的独立实例(例如,给每把椅子涂上不同的颜色,而不是所有椅子都是同一颜色)。最后,在最细微的层面上,部分分割试图将具有相同语义的物体的各个部分分开(例如,给椅子的各个部分涂上不同的颜色),由于具有相同语义标签的形状部分具有较大的几何变化和模糊性,因此这项任务特别困难[1]。
3DLIVE努力的目标之一是创建一个系统(利用机器学习),该系统接收一个地理区域的点云,将具有类似属性的点分组为对象,并为每个组成对象和结构贴上标签,使数据更容易使用和分析。在我们着手实现这些目标之前,我们确定研究当前点云数据集的分割和分类技术状况将是有价值的。Guo等人在2019年完成了一项关于点云的深度学习方法的调查[1]。我们的目的是确认研究中提出的信息仍然是准确和相关的(针对点云数据集的ML是一个快速发展的领域),进行我们自己的研究并创建一个类似的调查,并决定在研究的分类、分割和目标检测的方法中,哪些是最适合我们的使用案例的。AFRL RIEA/RIED内部研究小组(IHURT)被召集起来,与3DLIVE团队一起做这项研究,并回答以下研究问题:
目前3D点云分割和分类的技术水平如何,哪些方法对3DLIVE的工作最有效?我们能否开始为我们打算使用的大规模三维城市点云的分割、分类和目标检测奠定框架并制定行动方案?
这项研究的结果将使3DLIVE团队能够推进ML点云的分析工作。我们希望最终能复制出性能最高、最相关的分割、分类和目标检测方法,并将其用于NGA地理空间存储和数据管理(GRID)服务器的地理3D点云数据。此外,3DLIVE团队已经开发了一种生成大规模合成城市点云数据集的方法,我们可以利用这种合成数据作为我们创建和使用的模型的额外训练数据。这项研究将为3DLIVE团队使用ML创建额外的工具来帮助作战人员分析和衡量三维数据奠定基础。这将最终实现上述目标,即创建一个新的TCM系统,供目标人员(如第363 ISR联队和其他目标部门的人员)使用,用一种利用越来越多的本地3D数据的替代技术取代目前已被淘汰的技术。
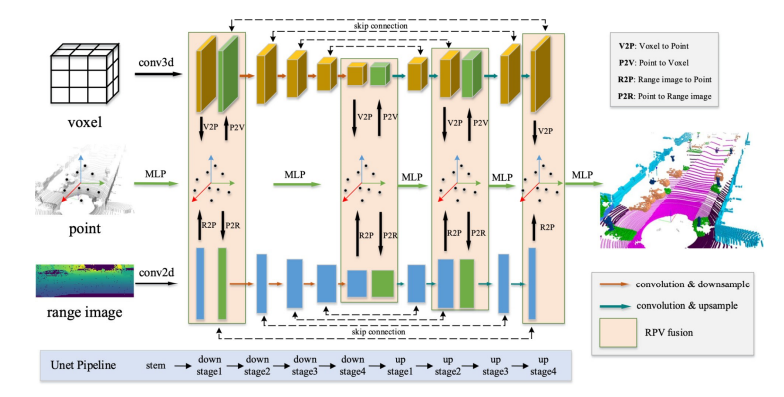
图2. RPVNet的概述。它是一个具有多种交互作用的三分支网络,其中体素分支和范围分支共享类似的Unet架构,而点分支只利用每点的MLPs。


