本文简单介绍上海交通大学ReThinklab实验室被NeurIPS2023录用的六篇工作,内容涵盖了深度学习理论、最优传输算法、大规模图表示学习、电路自动设计、组合优化问题求解、旋转目标检测等领域。以下是每篇论文的简介。这些工作主要获得来自科技部2030新一代人工智能项目、基金委优青项目以及重大研究计划项目的资助。
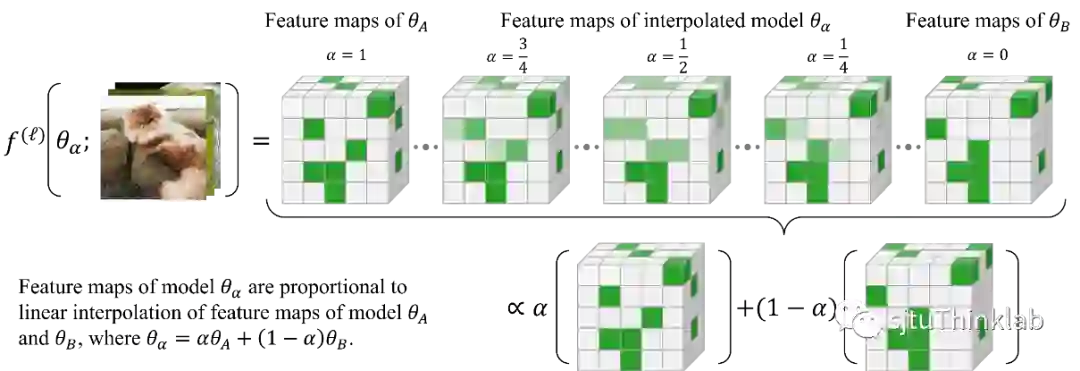
1. Going Beyond Linear Mode Connectivity: The Layerwise Linear Feature Connectivity
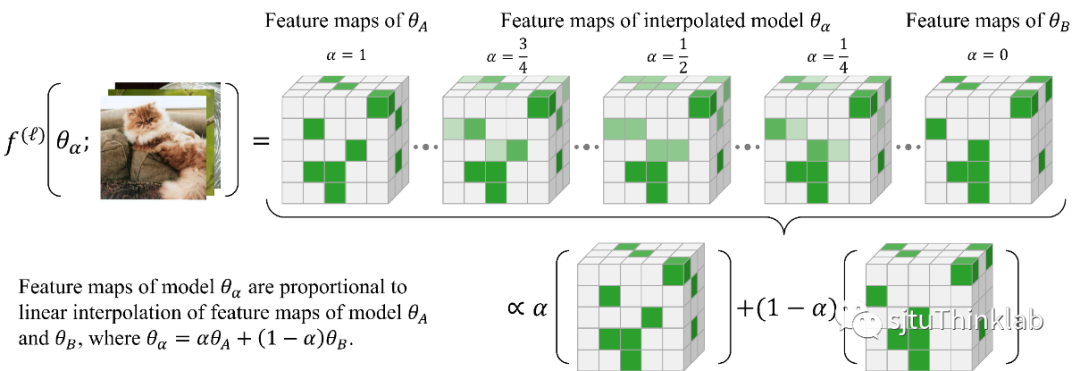
简介:最近的研究揭示了神经网络训练中许多有趣的经验现象,这些现象对我们理解深度网络的内部机制和训练动态(training dynamics)有重要的意义。其中一个现象是Linear Mode Connectivity(LMC):在参数空间中,不同收敛后的模型(Solution)可以通过线性路径相连,同时保持接近恒定的训练损失(train loss)和测试损失(test loss)。在这项工作中,我们引入了一个更强的Linear Connectivity的概念,即Layerwise Linear Feature Connectivity(LLFC),指不同训练网络中每一层的特征图也是线性连接的。我们提供了广泛的经验证据来验证LLFC的普遍存在性:只要两个收敛后的模型满足LMC(通过spawning或者permutation methods),那么这两个模型也几乎在所有层中满足LLFC,即LMC和LLFC的共生现象。此外,我们深入研究了对LLFC的成因,理论发现了两个模型满足LLFC的两个充分条件,即Weak Additivity for ReLU activations和Commutativity。从Commutativity出发,我们为permutation method(通过permutation的方式使得两个独立训练的网络满足LMC)的有效性提供了理论支持。从特征学习(feature learning)的视角,LLFC的研究超越并推进了我们对LMC的理解。 代码链接:https://github.com/zzp1012/LLFC
2. Relative Entropic Optimal Transport: a (Prior-aware) Matching Perspective to (Unbalanced) Classification
简介:由于自然场景中的广泛存在,长尾问题近些年来引起了广泛关注。本文抛开贝叶斯理论框架,从匹配的角度重新思考分类问题,通过采用最优传输(OT)的形式研究样本和标签之间的匹配概率。具体而言,本文首先提出了一种新的最优传输变种,称为相对熵最优传输(RE-OT),它将耦合解引导到一个已知的先验信息矩阵。我们给出了一些关于RE-OT的理论结果及其证明,并惊讶地发现RE-OT可以帮助对重心图像进行去模糊处理(见图(a))。然后,我们采用反向RE-OT来训练长尾数据,并发现RE-OT导出的损失与基于Softmax的交叉熵损失具有类似的形式,这表明最优传输和分类之间存在密切联系,并且在这两个学术领域之间存在概念转移的潜力,例如OT中的重心投影,可以将标签映射回特征空间。我们进一步推导了一个时代变化的RE-OT损失,并在不平衡图像分类、分子分类、实例分割和表示学习等任务上进行了实验,实验结果表明其有效性。 代码链接:https://github.com/LiangliangShi/RE-OT
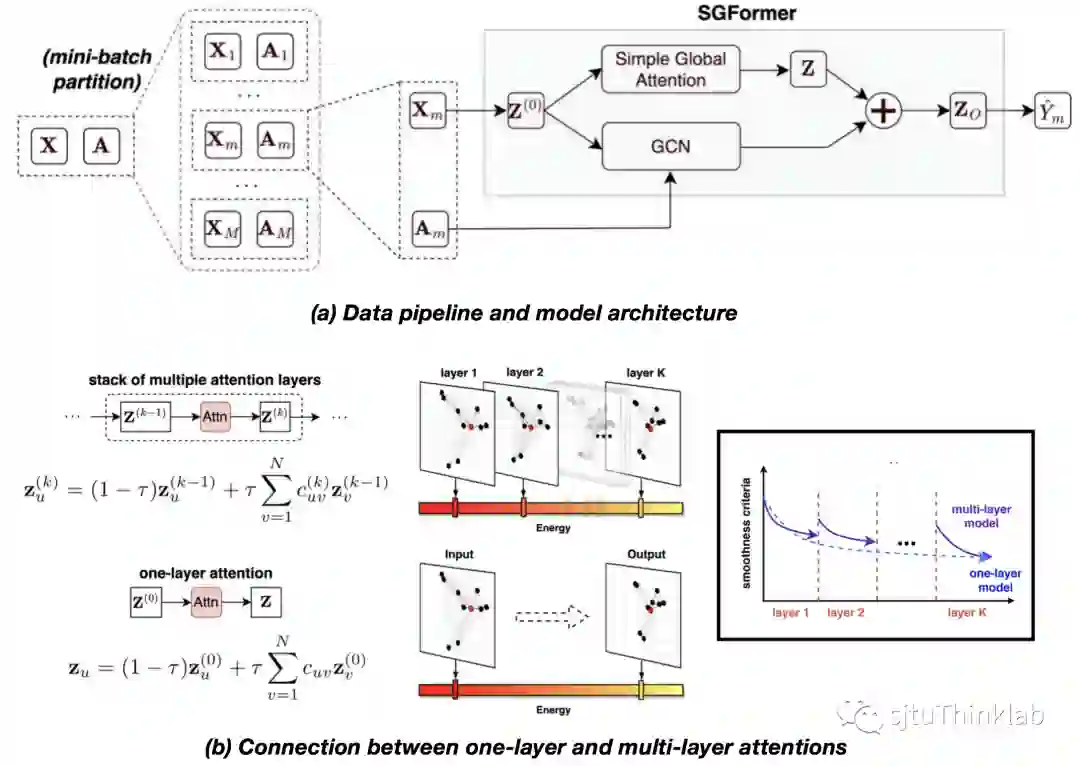
3. Simplifying and Empowering Transformers for Large-Graph Representations
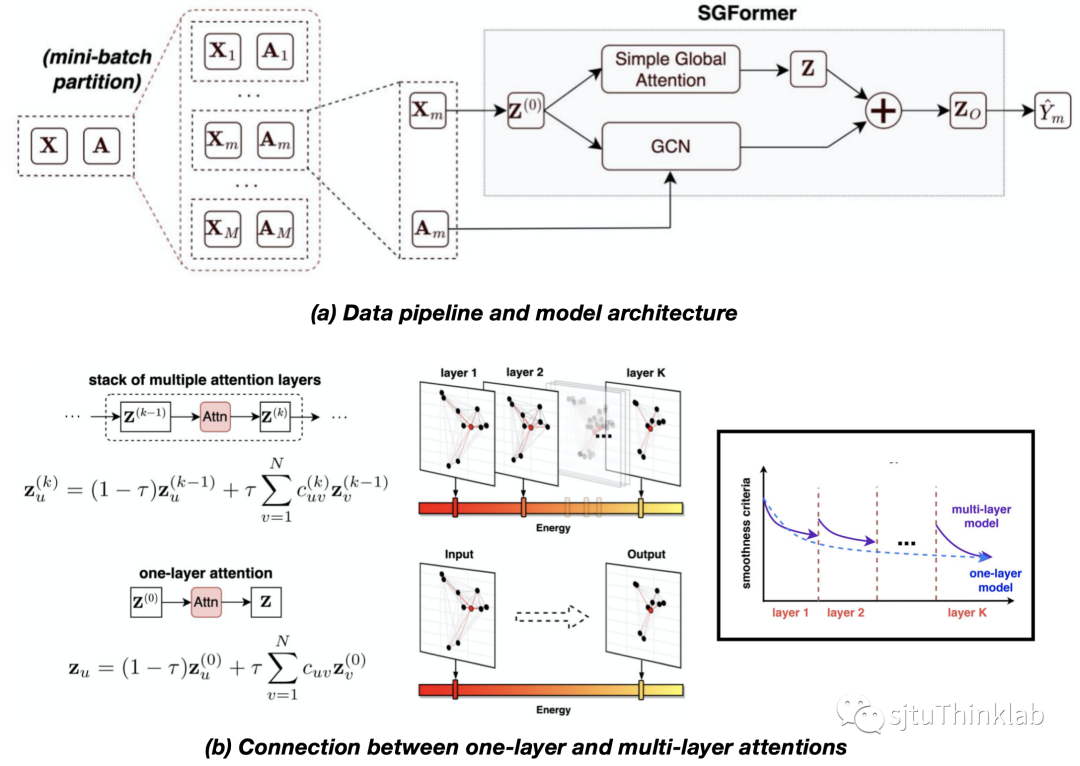
简介:设计针对图结构数据的Transformer模型 (简称graph Transformer) 目前已成为了一个备受关注的研究方向。然而,目前大部分graph Transformer只能处理小规模图(如分子图)。对于普通规模的图数据,例如节点数目达到上千的量级,全局注意力的平方级复杂度会使得传统的模型难以扩展。另一方面,目前的Transformer模型通常采用比较复杂的模型结构,例如堆叠多层的多头注意力机制。对于大规模图数据,一个常见的现象是图中带标签的节点比例较低,这种情况下复杂的模型结构会影响到模型的泛化性能。为此,在这项研究工作中,我们试图探索一条有别于大众方法的技术路径,即对Transformer进行简化,以实现对大规模图的高效建模。具体的,我们提出了Simplified Graph Transformer (简称SGFormer) ,在只使用一层线性复杂度的全局注意力网络的情况下,我们的方法在12个不同性质和规模的节点性质预测benchmark上都表现出极具竞争力的精度,首次实现了将Transformer方法扩展到上亿节点规模的超大图上,并在中等规模图上相比同类graph Transformer方法实现了大幅度的计算效率提升。 代码链接:https://github.com/qitianwu/SGFormer 知乎介绍:https://zhuanlan.zhihu.com/p/674548352
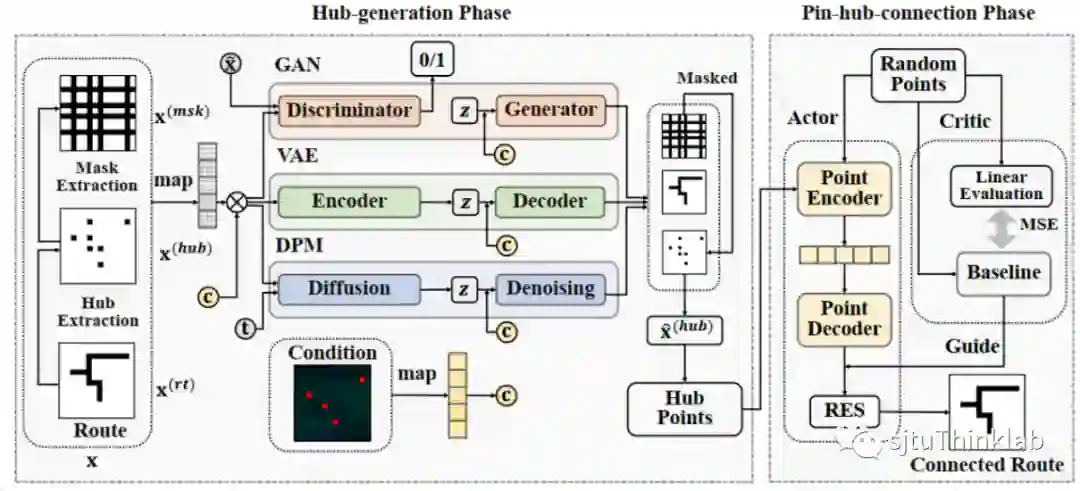
4. HubRouter: Learning Global Routing via Hub Generation and Pin-hub Connection
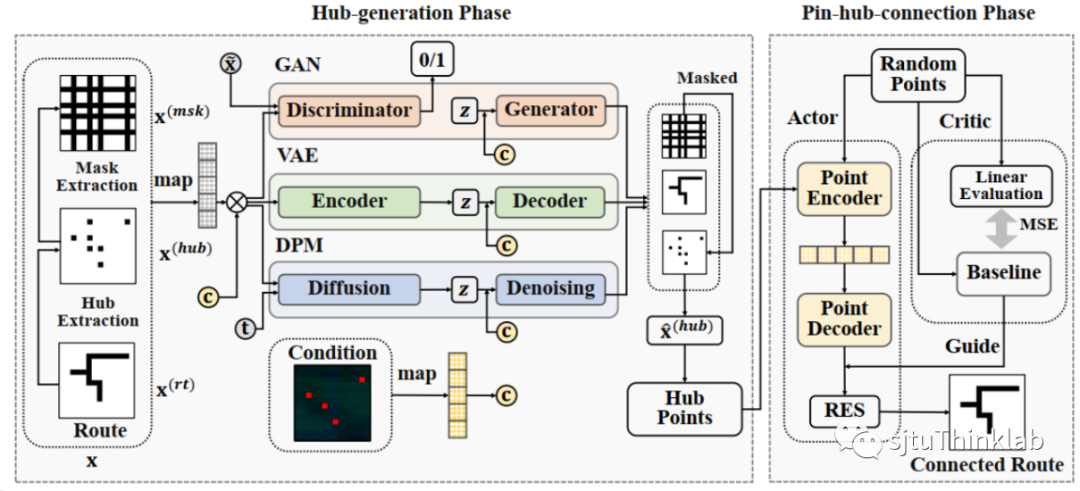
简介:全局布线(Global Routing)是大规模集成电路(Very Large Scale Integration, VLSI)设计中的一个重要且耗时的环节。近年来,机器学习的广泛应用为全局布线任务带来了新的解决思路。特别地,生成模型能够快速为每个网络(Net)生成线路(Route),在全局布线任务中展现出了巨大的潜力。然而,由于生成模型的生成质量难以保证,可能会生成不连通的线路,因此通常需要借助传统布线器进行后处理。这种处理方式会造成较大的时间开销,从而大幅降低生成式布线器的实用性。鉴于此,本文首先定义了线路中的枢纽点(Hub)概念,枢纽点是线路中的关键节点。进一步地,本文提出了一种二阶段的学习模型——HubRouter。第一阶段是枢纽点生成阶段,HubRouter通过条件生成模型生成线路的枢纽点;第二阶段是管脚-枢纽点连接阶段,HubRouter采用强化学习模型学习管脚与枢纽点的连接顺序,从而形成最终的连通线路。这种二阶段学习模型能够在保证连通性的前提下,快速生成每个网络的线路,旨在提高生成式布线器的效率和实用性。 代码链接:https://github.com/Thinklab-SJTU/EDA-AI/tree/main/HubRouter
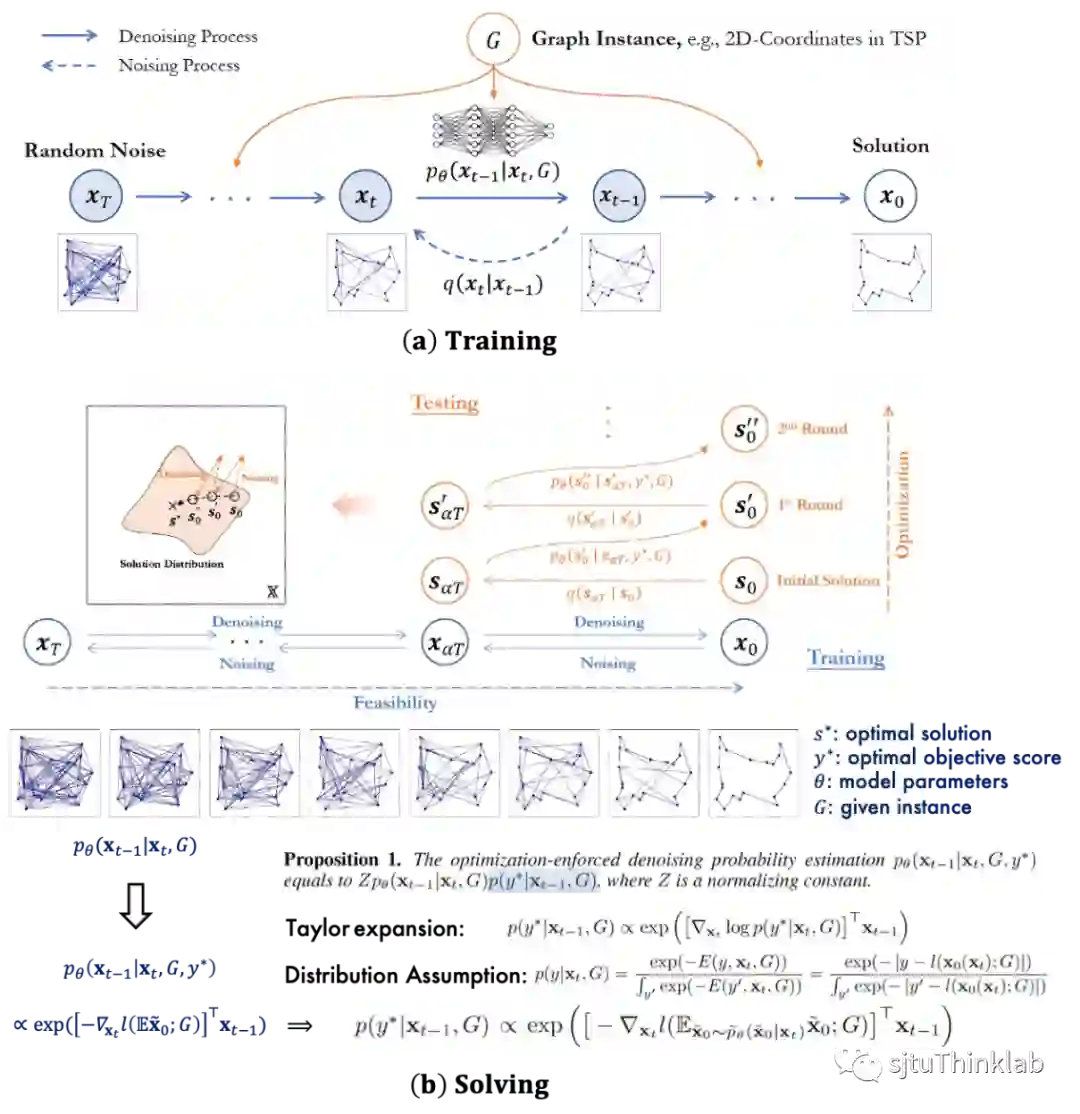
5. From Distribution Learning in Training to Gradient Search in Testing for Combinatorial Optimization
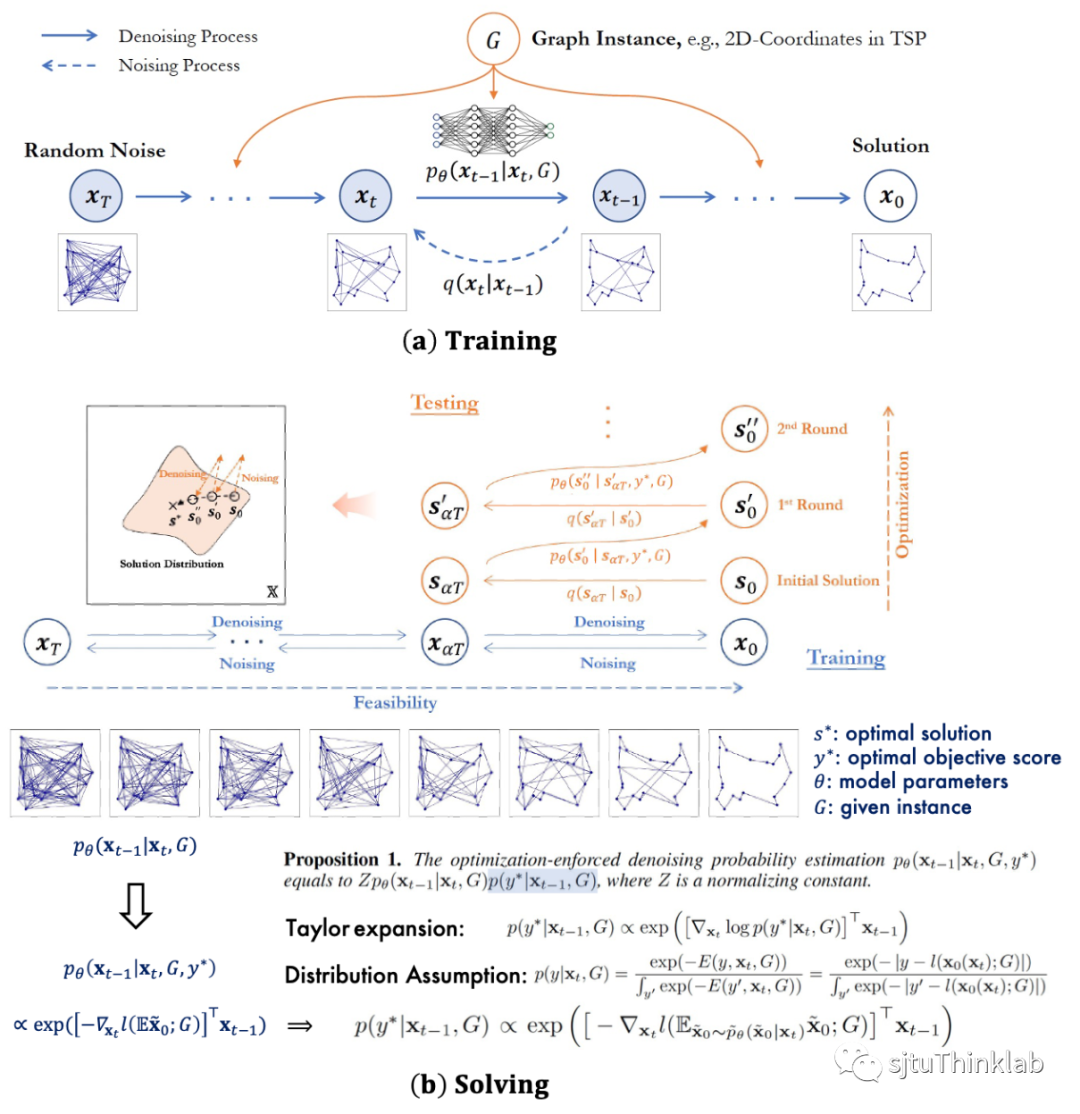
简介:组合优化为在离散变量上进行的优化问题,其中一大类问题为图上图论求解问题,这些问题在计算机和运筹领域等具有重要研究意义。机器学习求解组合优化问题的方案往往将求解任务建模为解预测的任务,然而模型在训练阶段优化历史数据平均性能的目标与在求解阶段对每一个问题样例进行最优化的目标之间存在差异,这要求算法在测试阶段对每个样例能进行定制化的求解搜索。传统预测网络往往给出一个收敛到局部最优的预测结果,难以进行进一步搜索。对此本文提出T2TCO框架,首先在训练中使用扩散生成模型学习高质量解的分布,其次在测试求解时引入目标函数引导的梯度优化来进一步优化解的质量。在实现上,T2TCO在训练阶段通过扩散模型学习如何从随机噪声中逐步去噪以预测高质量解的数据分布。在求解阶段,受到条件分类器引导方法的启发,希望在生成时引入组合优化问题目标函数的引导,使得求解时模型聚焦于给出更优目标代价的解。具体而言,我们通过当前解情况在估计目标函数下的近似梯度将估计的优化方向引入模型原本学习的去噪方向,使得模型具有优化的作用,同时设计局部改进的算法重复多次局部解结构的解构(加噪)和在引入目标函数引导的去噪方程下的重构(去噪)来进一步优化当前的解的质量。论文在经典组合图论问题旅行商问题和最大独立集问题上验证了性能,提出的算法相比于此前基于学习的组合求解算法提升显著。 代码链接:https://github.com/Thinklab-SJTU/T2TCO
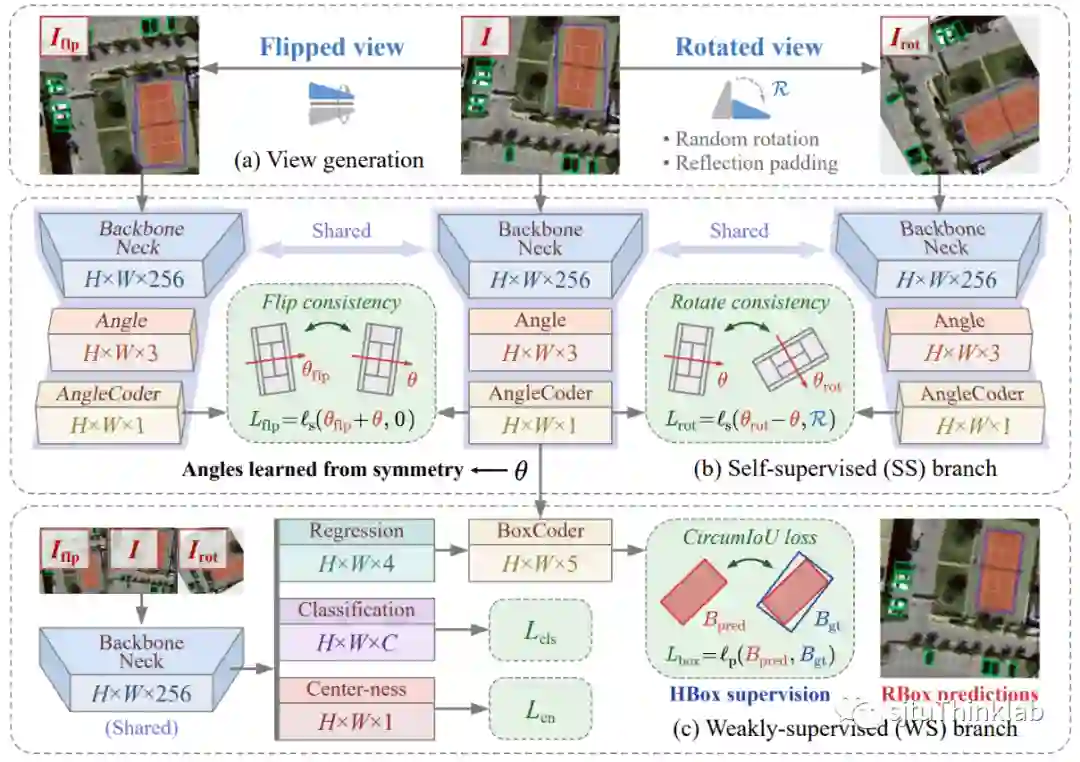
6. H2RBox-v2: Incorporating Symmetry for Boosting Horizontal Box Supervised Oriented Object Detection
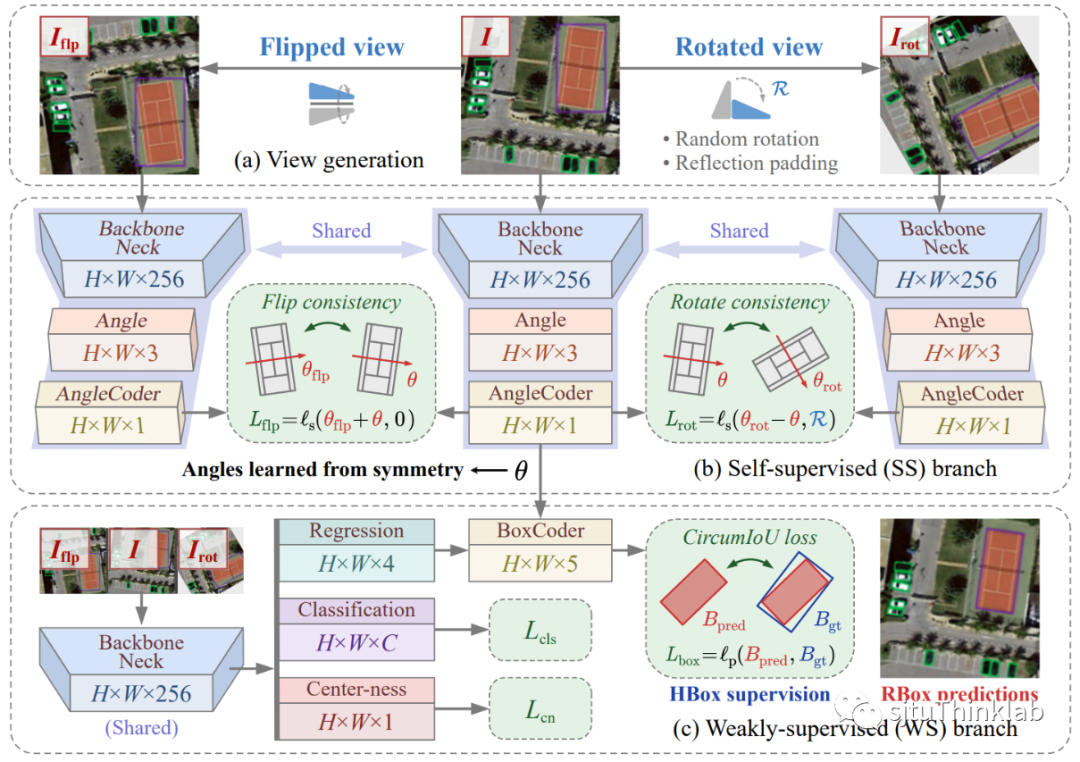
简介:水平框监督的有向目标检测属于弱监督学习目标检测,即在训练数据仅有水平框的情况下,学习目标的旋转角度,并训练有向目标检测器。这项工作中我们提出了一种基于对称感知的自监督方法,即通过目标的对称性学习其角度。我们定义了两种一致性:翻转一致性和旋转一致性,并通过理论分析证明了在输入对称目标时,如果检测器满足这两种一致性,那么它的输出必然是目标的对称轴。同样,在实际训练中若通过一致性损失对网络进行训练,使网络习得这两种一致性,则其输出就是目标的对称轴角度。为了验证这一思路,我们设计了一种多分支的训练架构,将原始训练图片经过随机旋转和上下翻转,分别输入到三个共享权重的分支,并在相邻分支之间计算一致性损失函数。实验结果表明,经过训练网络会获得旋转一致性和翻转一致性,其输出的角度也会逐渐趋近于目标的对称轴角度。辅以弱监督分支对目标的分类和尺寸进行学习,即可得到完整的旋转框。实验证实了该思路的可行性,并在多个数据集上取得了与旋转框强监督相近的检测性能。 代码链接:https://github.com/yuyi1005/mmrotate/tree/dev-1.x 知乎介绍:https://zhuanlan.zhihu.com/p/620884206
神经信息处理系统大会(简称NeurIPS/NIPS)近日在美国新奥尔良会议中心举行。该会议是机器学习领域最受关注的三大旗舰会议之一,也是CCF-A类会议。大会讨论的内容包含机器学习、深度学习、人工智能相关的各个前沿方向,每年吸引了上万名来自不同研究领域、学科背景的学者和从业人员参加。