

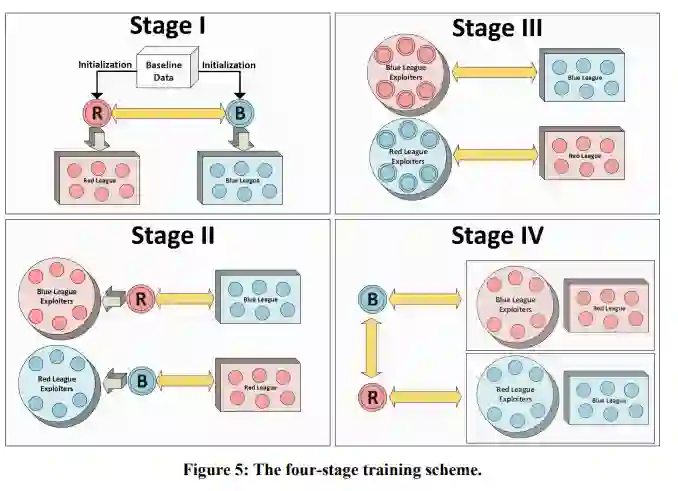
这个项目利用RL的一些最新进展来开发实时战略游戏的规划器,特别是MicroRTS来代替Stratagem计划的兵棋。PI实验室的这些进展之一被称为强化学习作为预演(RLaR)。在此之前,RLaR只在玩具基准任务中进行了评估,以确定其在减少样本复杂性方面的功效。这个项目为行为者-评论者架构开发了RLaR,并首次将其应用于具有不完整信息的复杂领域,如MicroRTS。本项目中应用的另一项技术源于最近在复杂的《星际争霸II》游戏中多智能体学习的成功,特别是多阶段训练的架构,在训练稳健策略的中间阶段发展联盟和联盟开拓者策略。
我们针对MicroPhantom--最近MicroRTS比赛的亚军--对RLaR进行了训练,结果表明它能够对这个对手进行有效的计划,但使用的样本比相关基线少。另外,我们使用4个阶段的训练方案在自我博弈中训练RLaR,并针对MentalSeal(冠军程序)和MicroPhantom评估了训练后的策略。虽然该策略在面对MicroPhantom时再次显示出良好的性能,但它在面对MentalSeal时却没有表现得很好。根据先前的初步发现,针对MentalSeal的训练是非常缓慢的,我们推测需要大量的训练时间,而不是我们在这个项目的延长期内能够投入到这个步骤中的。

成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年8月18日
Arxiv
224+阅读 · 2023年4月7日
相关主题



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年8月18日
Arxiv
224+阅读 · 2023年4月7日