人工智能(AI)智能体是一种软件实体,它根据预定义的目标和数据输入自主执行任务或做出决策。AI智能体能够感知用户输入、推理和计划任务、执行动作,并在算法开发和任务性能方面取得了显著进展。然而,它们所带来的安全挑战仍未得到充分探索和解决。本综述深入探讨了AI智能体面临的新兴安全威胁,将其分为四个关键知识空白:多步用户输入的不可预测性、内部执行的复杂性、操作环境的多变性以及与不可信外部实体的交互。通过系统性地审视这些威胁,本文不仅突出了在保护AI智能体方面所取得的进展,还揭示了现有的局限性。所提供的见解旨在激发进一步的研究,以解决与AI智能体相关的安全威胁,从而促进更加健全和安全的AI智能体应用的发展。
人工智能(AI)智能体是通过自主性、反应性、主动性和社交能力展示智能行为的计算实体。它们通过感知输入、推理任务、规划行动和使用内部和外部工具执行任务,与其环境和用户互动以实现特定目标。以GPT-4等大型语言模型(LLMs)为动力的AI智能体,在包括医疗、金融、客户服务和智能体操作系统等各个领域的任务完成方式上实现了革命性变化。这些系统利用LLMs在推理、规划和行动方面的先进能力,使它们能够以卓越的性能执行复杂任务。
https://www.zhuanzhi.ai/paper/2cdbfa599ada6be5d12a7ba7d7606445
尽管AI智能体取得了显著进展,但其日益复杂化也引入了新的安全挑战。由于AI智能体部署在各种关键应用中,确保其安全至关重要。AI智能体安全指的是旨在保护AI智能体免受可能损害其功能、完整性和安全性的漏洞和威胁的措施和实践。这包括确保智能体能够安全处理用户输入、执行任务,并与其他实体交互,而不会受到恶意攻击或意外有害行为的影响。这些安全挑战源于四个知识空白,如果不加以解决,可能导致漏洞和潜在的滥用。
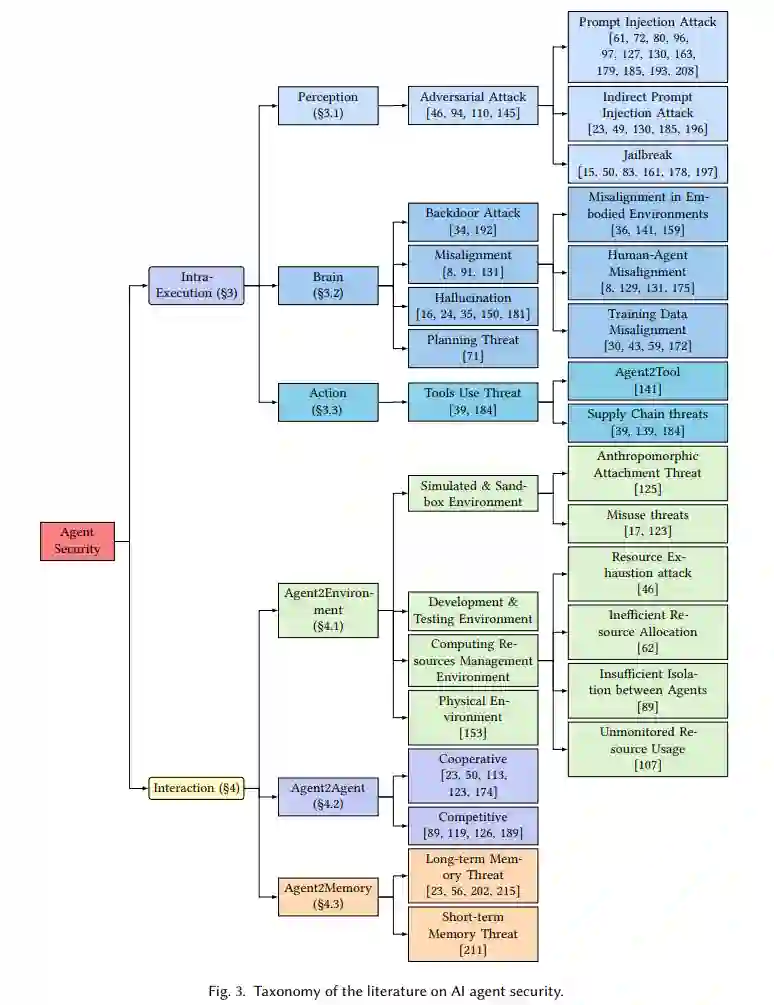
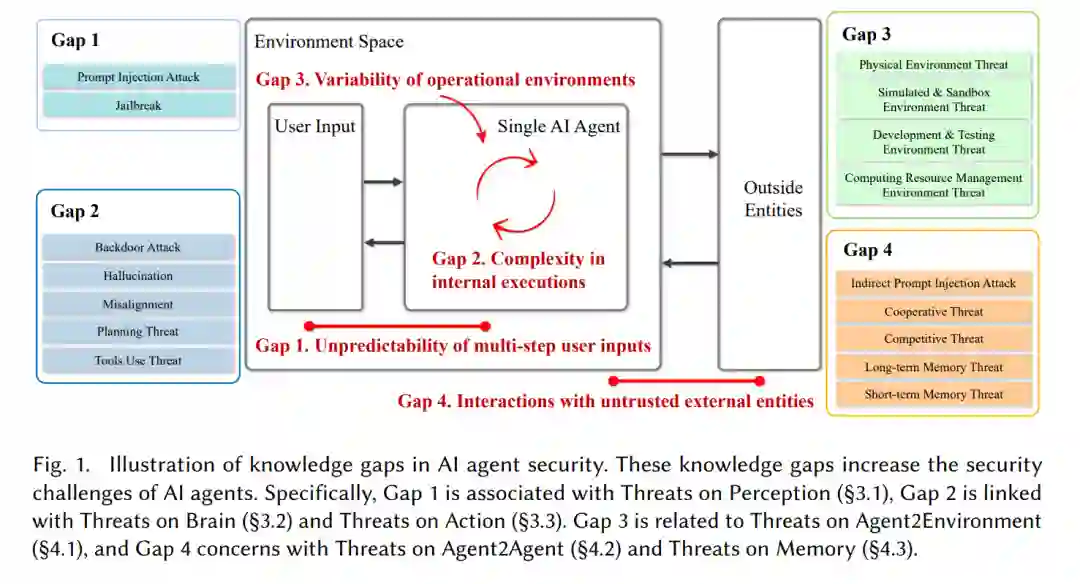
如图1所示,AI智能体的四个主要知识GAP分别是:1)多步用户输入的不可预测性,2)内部执行的复杂性,3)操作环境的多变性,4)与不可信外部实体的交互。以下几点详细说明了这些知识空白。 - 空白1. 多步用户输入的不可预测性。用户在与AI智能体互动中起着关键作用,不仅在任务启动阶段提供指导,还通过多轮反馈在任务执行过程中影响方向和结果。用户输入的多样性反映了不同背景和经验,引导AI智能体完成多种任务。然而,这些多步输入也带来了挑战,尤其是在用户输入描述不足时,可能导致潜在的安全威胁。用户输入的不充分说明不仅会影响任务结果,还可能引发一系列意外反应,导致更严重的后果。此外,存在故意引导AI智能体执行不安全代码或操作的恶意用户,这增加了额外的威胁。因此,确保用户输入的清晰性和安全性对于AI智能体的有效和安全运行至关重要。这需要设计高度灵活的AI智能体生态系统,能够理解和适应用户输入的多样性,同时确保有健全的安全措施以防止恶意活动和误导性用户输入。 - 空白2. 内部执行的复杂性。AI智能体的内部执行状态是一个复杂的链式结构,包括从提示的重格式化到LLM任务规划和工具的使用。许多内部执行状态是隐含的,难以观察详细的内部状态。这导致许多安全问题无法及时发现。AI智能体安全需要审核单个AI智能体的复杂内部执行。
- 空白3. 操作环境的多变性。在实践中,许多智能体的开发、部署和执行阶段跨越各种环境。这些环境的多变性可能导致行为结果的不一致。例如,执行代码的智能体可能在远程服务器上运行给定代码,可能导致危险操作。因此,跨多个环境安全完成工作任务是一个重大挑战。
- 空白4. 与不可信外部实体的交互。AI智能体的一个关键能力是教大模型如何使用工具和其他智能体。然而,当前AI智能体与外部实体的交互过程假设了一个可信的外部实体,导致了广泛的实际攻击面,如间接提示注入攻击。AI智能体与其他不可信实体交互是一个挑战。
虽然已有一些研究工作针对这些空白,但针对AI智能体安全的全面回顾和系统分析仍然缺乏。一旦这些空白得到弥补,AI智能体将因更清晰和更安全的用户输入、增强的安全性和对潜在攻击的鲁棒性、一致的操作环境行为以及用户的信任和可靠性增加而受益。这些改进将促进AI智能体在关键应用中的更广泛采用和整合,确保它们能够安全有效地执行任务。
现有关于AI智能体的综述主要集中在其架构和应用上,未深入探讨安全挑战和解决方案。我们的综述旨在填补这一空白,通过详细回顾和分析AI智能体安全,识别潜在解决方案和缓解这些威胁的策略。所提供的见解旨在激发进一步的研究,以解决与AI智能体相关的安全威胁,从而促进更加健全和安全的AI智能体应用的发展。
在本综述中,我们基于四个知识空白系统性地回顾和分析了AI智能体安全的威胁和解决方案,覆盖了广度和深度方面。我们主要收集了从2022年1月到2024年4月期间在顶级AI会议、顶级网络安全会议和高度引用的arXiv论文。AI会议包括但不限于NeurIPs、ICML、ICLR、ACL、EMNLP、CVPR、ICCV和IJCAI。网络安全会议包括但不限于IEEE S&P、USENIX Security、NDSS和ACM CCS。
本文组织如下。第二节介绍了AI智能体的概述。第三节描述了与空白1和空白2相关的单智能体安全问题。第四节分析了与空白3和空白4相关的多智能体安全问题。第五节提出了该领域发展的未来方向。
### 2.1 统一概念框架下的AI智能体概述
术语
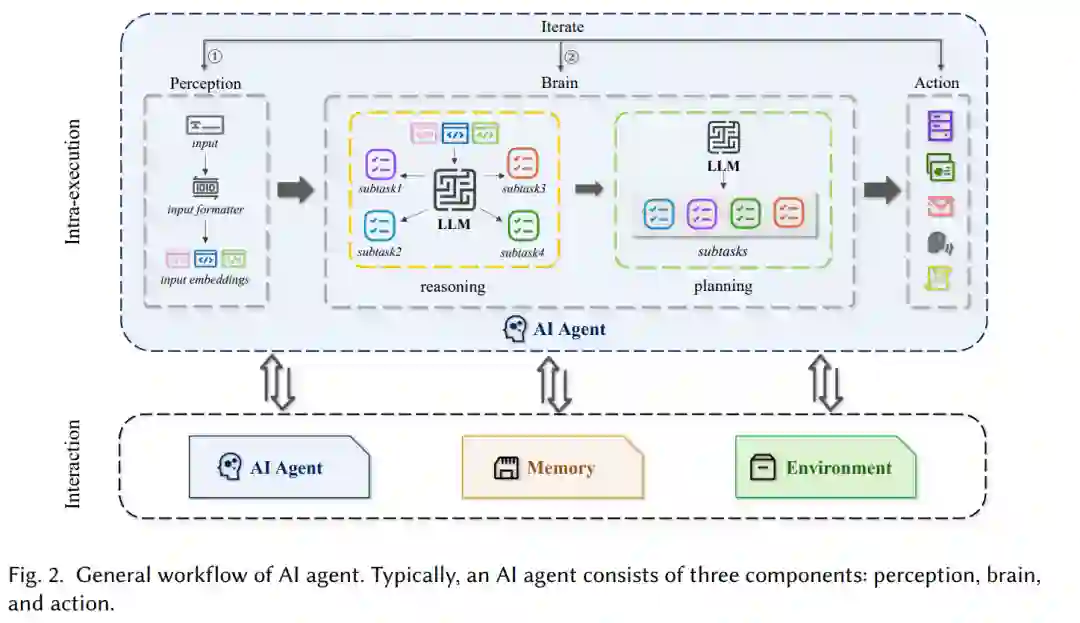
为了便于理解,我们在本文中介绍以下术语。如图2所示,用户输入可以使用输入格式化工具重新格式化,以通过提示工程提升输入质量。这一步也称为感知。推理指的是设计用于分析和推导信息的大型语言模型,帮助从给定提示中得出逻辑结论。另一方面,规划指的是一个大型语言模型,旨在通过评估可能的结果并优化特定目标,帮助制定策略和决策。用于规划和推理的LLMs的组合被称为大脑。外部工具调用则统称为行动。在本综述中,我们将感知、大脑和行动的组合称为内部执行。另一方面,除了内部执行,AI智能体还可以与其他AI智能体、记忆和环境互动;我们称之为交互。这些术语也可以在文献[186]中详细探讨。 1986年,Mukhopadhyay等人的研究提出了多个智能节点文档服务器,通过用户查询有效地从多媒体文档中检索知识。随后的一项工作[10]也发现了计算机助手在用户与计算机系统交互中的潜力,突出了计算机科学领域的重要研究和应用方向。随后,Wooldridge等人[183]将表现出智能行为的计算机助手定义为智能体。在人工智能发展的领域中,智能体被引入为具有自主性、反应性、主动性和社交能力的计算实体[186]。如今,得益于大型语言模型的强大能力,AI智能体已成为帮助用户高效完成任务的主要工具。如图2所示,AI智能体的一般工作流程通常包括两个核心组成部分:内部执行和交互。AI智能体的内部执行通常表示在单一智能体架构内运行的功能,包括感知、大脑和行动。具体来说,感知向大脑提供有效的输入,而行动则通过LLM的推理和规划能力处理这些输入并进行子任务。然后,这些子任务由行动按顺序运行以调用工具。①和②表示内部执行的迭代过程。交互指的是AI智能体与其他外部实体互动的能力,主要通过外部资源。这包括在多智能体架构内的合作或竞争、在任务执行过程中检索记忆,以及从外部工具中部署环境及其数据使用。请注意,在本综述中,我们将记忆定义为外部资源,因为大多数与记忆相关的安全风险源于外部资源的检索。 从核心内部逻辑的角度来看,AI智能体可以分为基于强化学习的智能体和基于大型语言模型的智能体。基于RL的智能体使用强化学习,通过与环境互动学习和优化策略,旨在最大化累积奖励。这些智能体在具有明确目标的环境中效果显著,例如指令执行[75, 124]或构建世界模型[108, 140],它们通过试错进行适应。相反,基于LLM的智能体依赖于大型语言模型[92, 173, 195],它们在自然语言处理任务中表现出色,利用大量文本数据掌握语言复杂性,以实现有效的沟通和信息检索。每种类型的智能体都有不同的能力,以实现特定的计算任务和目标。
### 2.2 AI智能体的威胁概述
目前,有几篇关于AI智能体的综述[87, 105, 160, 186, 211]。例如,Xi等人[186]提供了一个针对基于LLM的智能体应用的全面系统回顾,旨在审查现有研究和未来可能性。在文献[105]中总结了当前AI智能体的架构。然而,它们没有充分评估AI智能体的安全性和可信度。Li等人[87]未能考虑多智能体场景的能力和安全性。一项研究[160]仅总结了科学LLM智能体固有的潜在风险。Zhang等人[211]则仅调查了AI智能体的记忆机制。
我们的主要关注点是与四个知识空白相关的AI智能体的安全挑战。如表1所示,我们总结了讨论AI智能体安全挑战的论文。威胁来源列识别了在AI智能体通用工作流程的各个阶段使用的攻击策略,分为四个空白。威胁模型列识别了潜在的对手攻击者或易受攻击的实体。目标效果总结了与安全相关问题的潜在结果。 我们还提供了AI智能体威胁的新分类法(见图3)。具体来说,我们根据其来源位置识别威胁,包括内部执行和交互。