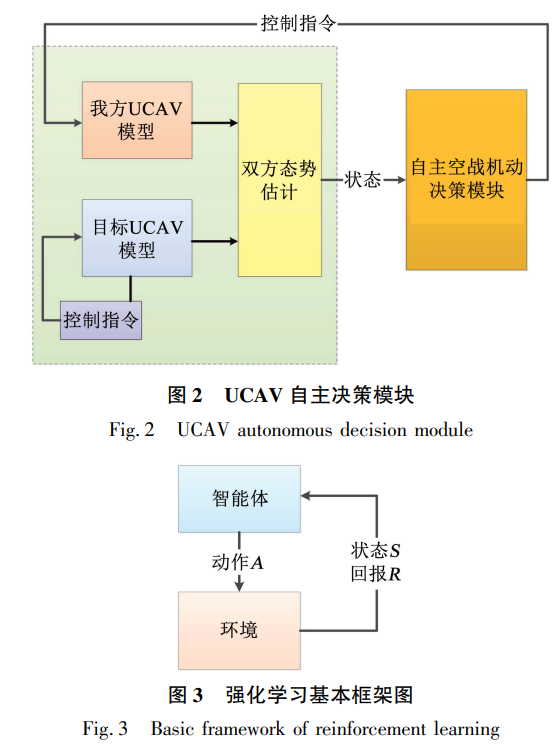
无人作战飞机(unmanned combat aerial vehicle,UCAV)在进行空战自主机动决策时,面临大规模计算,易受敌方不确定性操纵的影响。针对这一问题,提出了一种基于深度强化学习算法的无人作战飞机空战自主机动决策模型。利用该算法,无人作战飞机可以在空战中自主地进行机动决策以获得优势地位。首先,基于飞机控制系统,利用MATLAB/Simulink仿真平台搭建了六自由度无人作战飞机模型,选取适当的空战动作作为机动输出。在此基础上,设计了无人作战飞机空战自主机动的决策模型,通过敌我双方的相对运动构建作战评估模型,分析了导弹攻击区的范围,将相应的优势函数作为深度强化学习的评判依据。之后,对无人作战飞机进行了由易到难的分阶段训练,并通过对深度Q网络的研究分析了最优机动控制指令。从而无人作战飞机可以在不同的态势情况下选择相应的机动动作,独立评估战场态势,做出战术决策,以达到提高作战效能的目的。仿真结果表明,该方法能使无人作战飞机在空战中自主的选择战术动作,快速达到优势地位,极大地提高了无人作战飞机的作战效率。 目前无人作战飞机(unmanned combat aerial vehicle, UCAV)被广泛应用于军事领域[1],UCAV在过去主要从事战场监视、吸引火力和通信中继等任务,随着武器装备的传感器、计算机及通信等技术的发展,性能不断提升,未来的UCAV将逐步升级成为可以执行空中对抗、对地火力压制和参与制空权的夺取等作战任务的主要作战装备之一。尽管UCAV的性能提升很大,但大多数的任务都离不开人工干预,控制人员通过基站在地面对UCAV进行控制,这种控制方法有延迟且易受到电磁干扰。因此研究UCAV的自主作战能力已经成为空军发展的必然趋势,装备了无人作战决策系统的UCAV将逐步取代飞行员的位置,以达到减少成本,提高战斗力的作用。在近距离格斗的阶段,UCAV应根据当前的空战态势及时选取合适的飞行控制指令,抢占有利的位置,寻找击落敌机的机会并保护自己[2]。
在空战条件下,飞机模型本身为非线性同时目标的飞行轨迹是不确定的,这些都将给UCAV的机动决策带来许多不便,因此良好的机动决策是UCAV自主空战的一个重要环节,自动机动决策要求UCAV能在不同的空战环境下自动生成飞行控制指令。常规的机动决策控制方法包括最优化方法、博弈论法、矩阵对策法、影响图法、遗传算法、专家系统、神经网络方法以及强化学习方法等。文献[3]将空战视为一个马尔可夫过程,通过贝叶斯推理理论计算空战情况,并自适应调整机动决策因素的权重,使目标函数更加合理,保证了无人战斗机的优越性。文献[4]设计了一个基于遗传学习系统的飞机机动决策模型,通过对机动的过程加以优化来解决空战环境未知情况下的空战决策问题,可以在不同的空战环境中产生相应的战术动作,但该方法的参数设计存在主观性,不能灵活应用。文献[5]利用统计学原理研究UCAV的空战机动决策问题,具有一定的鲁棒性,但该算法实时性能较差无法应用于在线决策。文献[6]将可微态势函数应用于UCAV微分对策中,可以快速反应空战环境,但由于实时计算的局限性很难解决复杂的模型。文献[7]采用博弈论对UCAV空战决策进行建模,对不同的空战环境具有通用性。虽然这些决策算法可以在一定程度上提高决策的效率、鲁棒性和寻优率,但由于这些决策模型存在推理过程较为频繁,会浪费大量时间寻优等问题,导致UCAV的响应变慢,并不适用于当今的战场环境。
基于人工智能的方法包括神经网络法、专家系统法以及强化学习算法。文献[8]采用了专家系统法,通过预测双方的态势和运动状态生成相应的机动指令控制UCAV飞行,但不足之处在于规则库的构建较为复杂,通用性差。文献[9]采用了自适应神经网络技术设计PID控制器,对高机动目标具有较强的跟踪精度,但神经网络方法需要大量的空战样本,存在学习样本不足的问题。与以上两种方法相比,强化学习算法是一种智能体与环境之间不断试错交互从而进行学习的行为,智能体根据环境得到的反馈优化自己的策略,再根据策略行动,最终达到最优策略。由于强化学习的过程通常不考虑训练样本,仅通过环境反馈得到的奖励对动作进行优化,可以提高了学习的效率,是一种可行的方法[10]。文献[11]将空战时的状态空间模糊化、归一化作为强化学习算法的输入,并将基本的空战动作作为强化学习的输出,使得UCAV不断与环境交互从而实现空战的优势地位。在此基础上,文献[12-13]将神经网络与强化学习相结合,提高了算法的运算效率,但这些文章都没有考虑飞机的姿态变化。
本文提出了一种深度强化学习(deep reinforcement learning, DRL)算法来解决UCAV自主机动决策作战的问题,并在MATLAB/Simulink环境中搭建了某种六自由度UCAV模型,充分考虑了其非线性。同时选取适当的空战动作作为UCAV的机动输出,建立空战优势函数并设计UCAV空战机动决策模型。通过强化学习方法可以减少人为操纵的复杂性,保证计算结果的优越性,提高UCAV的作战能力,而神经网络可以提升实时决策能力。最后通过仿真将该方法应用于UCAV机动作战决策中,证明了其有效性和可行性。