
军队一直认为有必要将他们的决策建立在成熟的作战研究方法之上,这些方法试图在决策过程中为指挥部提供备选方案,对战役到战略进行评估。
战斗伤亡是军事运筹学的一个研究课题,它应用数学模型来量化胜利与损失的概率。特别是,已经提出了不同的方法来模拟战斗的过程。然而,它们都没有为高层指挥提供足够的决策支持。为了克服这种情况,本论文提出了一个创新的框架,它克服了传统模型的大部分局限性,并支持最高指挥层的决策:战略和战役层,借助于确定战斗力水平的衰减,通常被称为损耗(损失),作为评估决策的机制。该框架应用了适应性和预测性控制工程方法来动态调整以适应战斗的变化,同时考虑到对手的能力和机动性以及产生的效果。此外,它还包括一个学习机制,以改善在高不确定性条件下的决策。
论文报告了对克里特岛战役、硫磺岛战役和库尔斯克战役这三场有影响力的二战战役框架的实证评估,这些战役的战斗类型主要是陆上的。从那时起,这种作战模式基本上没有改变。因此,收集到的实验结果可以推断到现今的陆地作战。这本身就构成了一个相关的贡献,因为大多数关于军事决策的文献都缺乏足够的实验验证。
最后,本论文为从业者和研究人员提供了现有文献的指导,确定了现有决策模型的优势和劣势,并为在决策中应用战斗预测模型提供了参考背景。

本文范围
这项研究将分析战场决策模型的现状,重点是了解应用了哪些类型的决策,这些决策是如何做出的,以及有哪些经验证据支持这些决策,这将使人们深入了解当前方法的局限性,并能提出新的机制来克服这些局限性。在这个意义上,我们的研究将提出一种方法,以弥补陆地战场上高层决策自动化的差距,即所谓的战略和战役军事决策。拟议方法的有效性将由一套足够广泛的经验证据来证明,所有这些证据必须具有代表性。
论文目的
确定了以下目标:
-
消除兰彻斯特经典著作的局限性和其他兰彻斯特在陆地战场上的影响。
-
为战略和作战军事决策的自动化提供一个框架。
-
提供经验性证据,表明该框架充分适合战斗趋势,并能选择最合适的决策。
-
指导从业人员和研究人员了解现有决策模型的优势和劣势。
研究问题
本研究旨在分析控制理论在兰彻斯特战斗决策模型中的应用表现,以追求陆军领域的战略和作战决策方法。在此基础上,考虑了以下研究问题(RQs)。
-
问题1:现有的决策系统对战役和战略层面的指挥是否有足够的支持?
-
问题2:适应性和预测性控制结构能否有助于克服传统作战模式的局限性?
支持战役-战略决策的框架
有两种主要的战斗分析机制可以替代经典的兰彻斯特模型:(i)随机模型和(ii)确定性模型,其中一些是拉切斯特的传统,例如[KMPS17, JHC17a]。目前,其他方法,如智能代理,正在获得巨大的发展势头,例如,[OT17, ADK17]。这些新模型旨在扩展能力,例如[Kre20, Cou19],并减少以前方法的缺点,例如[Duf17, KLM18]。然而,它们未能成为高层决策的适当基准。
建议的框架克服了兰彻斯特原始工作的局限性,在[Eps85]中进行了深刻的讨论,将战斗视为一个因果过程,根据兰彻斯特方程的动态变化和外部行动进行演变。为此,该方法应用了[SR95]中介绍的适应性和预测性控制理论,并结合了不确定性建模技术。该方法的结构包括一组合作工作的模块,确保决策按照军事理论连贯地进行。特别是,一组连续的阶段触发了适用战略的定义、评估和选择不同的可能COA,以及使模型适应行动的演变。每个区块代表军事思维的机制,见图3.1,其中x(t)和y(t)定义了每个瞬间x部队和y部队的战斗人员数量,x(t+1)e和y(t+1)e是对下一瞬间战斗人员数量的估计。
实施需要有逻辑过程的能力,应该模拟从预测到行动的决策过程。在这种情况下,新的框架在第四章中被制定和测试(如果它在实际对抗中的应用在性能和一致性方面符合预期,它将是强大的)。

图3.1:我们框架的架构设计。每个区块都代表了军事思维的机制,因此(i)评估将确定要遵循的战略的战斗事件,并选择完成任务的COA,(ii)确定执行任务所需的资源,最后(iii)适应结果。
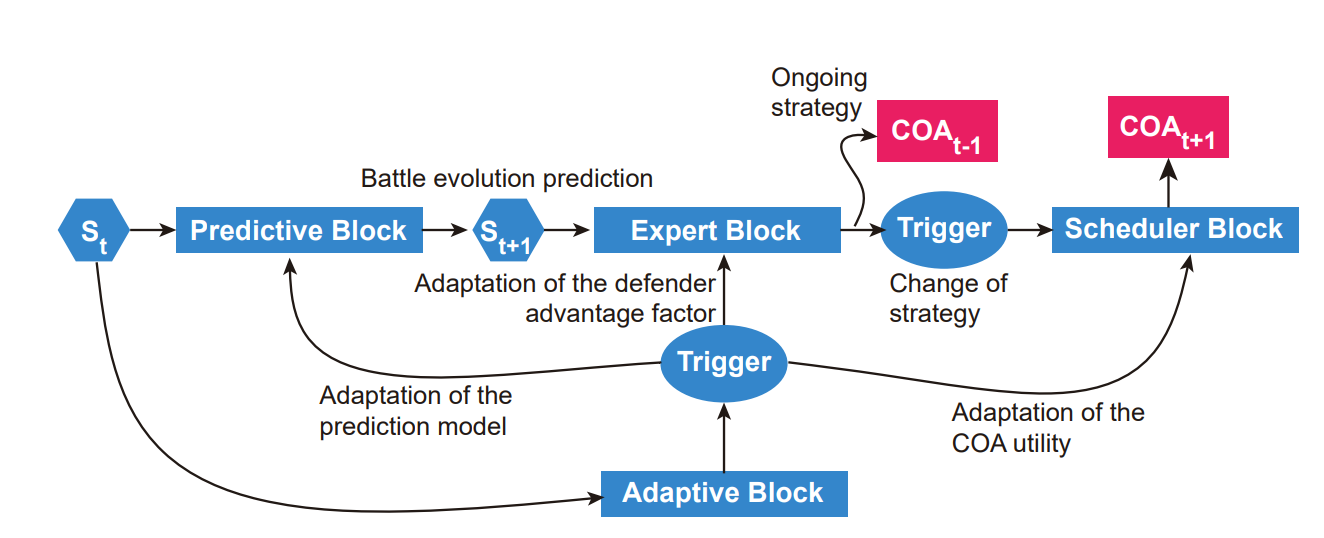
图3.2:在新框架中通过顺序模型触发选择特定COA的主要因素。
图3.2开发了迭代触发特定COA选择的基本要素。预测块产生预测演变。适应性模块根据输出信号(实际情况)与预测信号的差异调整组成模块的参数,并适当地更新最后执行的COA。专家区块试图通过调度区块修改预测区块定义的趋势,从而按照战斗的需要改变行动路线。值得注意的是,设定点与完成任务有关,行动的发展时间是操作时间,在最好的情况下,有冲突信息的可用数据库通常是以天为单位的时间演变。
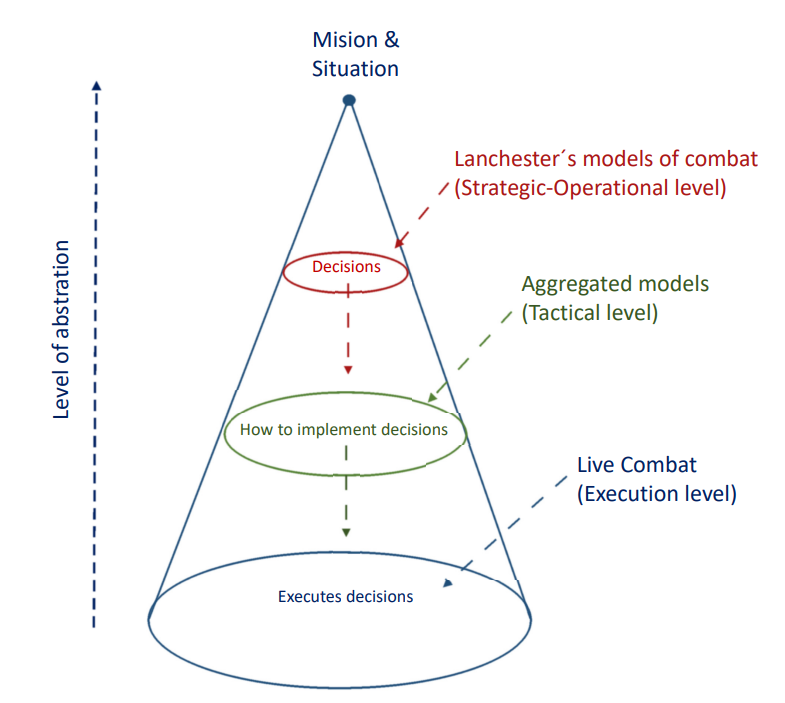
图3.3:纵轴标识了模型所体现的抽象程度,圆锥体的底圆代表现实或完全没有抽象,随着聚合水平的提高,定义指挥水平的变量逐渐抽象出作战执行的细节。因此,在兰彻斯特模型的应用水平与战略-战役聚合水平相一致,聚合模型涵盖了战斗最基本的执行机制,如个体冲突,执行水平受到武器装备、位置、能见度、后勤等因素的影响。
经验实证
特别是在克里特岛和硫磺岛战役中,我们的验证目标是根据当前的理论确定可能的最佳行动方案,并与1941年5月20日和1945年2月19日的实际战役相比,确定它们对对手产生的影响;在库尔斯克战役中,我们的目标是通过适应性和预测性控制的动态调整,正确确定战斗阶段,图4.1。
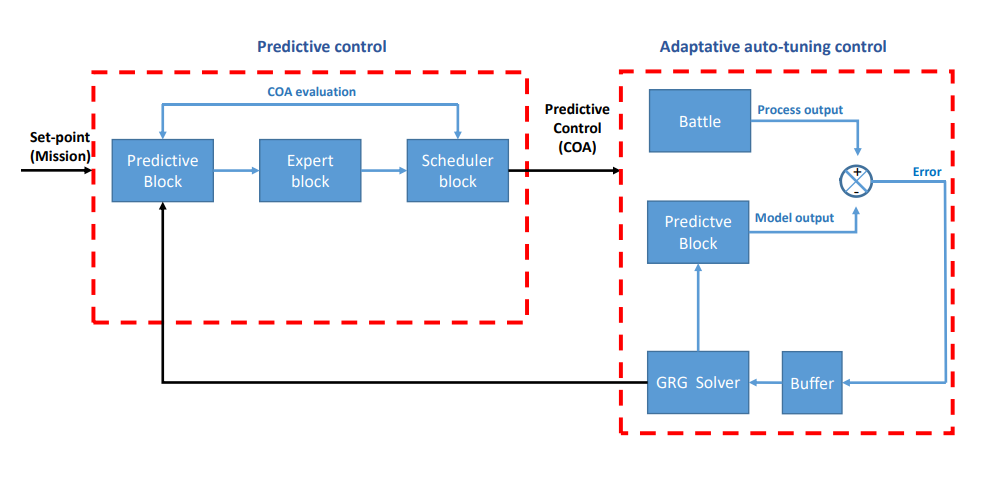
图4.1: 实际应用的基本自适应预测控制方案。自适应控制机制使战斗过程输出和预测模型输出之间的差异趋于零,突出了预测块在每个采样时间窗口在系统中发挥的双重作用。




