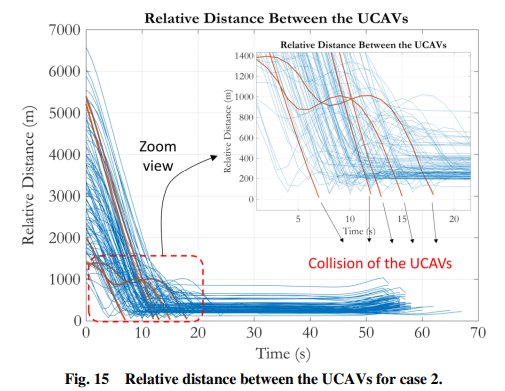
在这项研究中,基于强化学习(RL)的集中式路径规划被用于在人为的敌对环境中的无人作战飞行器(UCAV)编队。所提出的方法提供了一种新的方法,在奖励函数中使用了闭合速度和近似的时间-去向项,以获得合作运动,同时确保禁飞区(NFZs)和到达时间限制。近似策略优化(PPO)算法被用于RL智能体的训练阶段。系统性能在两个不同的情况下进行了评估。在案例1中,战争环境只包含目标区域,希望同时到达以获得饱和的攻击效果。在情况2中,战争环境除了目标区和标准的饱和攻击和避免碰撞的要求外,还包含NFZ。基于粒子群优化(PSO)的合作路径规划算法作为基线方法被实施,并在执行时间和开发的性能指标方面与提出的算法进行了比较。蒙特卡洛模拟研究被用来评估系统性能。根据仿真结果,所提出的系统能够实时生成可行的飞行路径,同时考虑到物理和操作限制,如加速限制、NFZ限制、同时到达和防撞要求。在这方面,该方法为解决UCAV机群的大规模合作路径规划提供了一种新颖的、计算效率高的方法。

引言
在空中攻击和防御场景的应用中,无人驾驶战斗飞行器(UCAVs)被用来执行监视、侦察和消灭放置在人为敌对环境中的敌方资产。在战争环境中可以使用不同类型的敌方防御单位,如高射炮(AAA)、地对空导弹(SAM)、探测/跟踪雷达和通信系统。这些资产的选择和放置是以被防御单位的战略重要性和被防御地区的地理规格为依据的。通过使用通信系统和防御单位,可以开发一个无缝防空系统来保护地面资产。图1给出了一个样本战争环境的总体概况。从攻击者舰队的角度来看,它的目标是以舰队特工的最小杀伤概率摧毁敌人的资产。如果行动中需要隐蔽性,也希望以最小的探测和跟踪概率完成任务。这可以通过两种方式获得。1)如果飞行路线必须通过敌人的雷达区域,则使用隐身飞机;2)通过生成不通过敌人雷达区域的飞行路线。如果任务要求和战争环境条件合适,可以考虑采用第二种方案,以达到最低风险。因此,飞行路径规划对于生成可行的、安全的飞行路线具有至关重要的意义,它可以提高在战争环境中的任务成功率和生存概率。本研究通过开发基于强化学习(RL)的合作集中式路径规划应用,重点关注第二种方式,在考虑任务和系统要求的同时,以最小的占用量生成飞行路线。
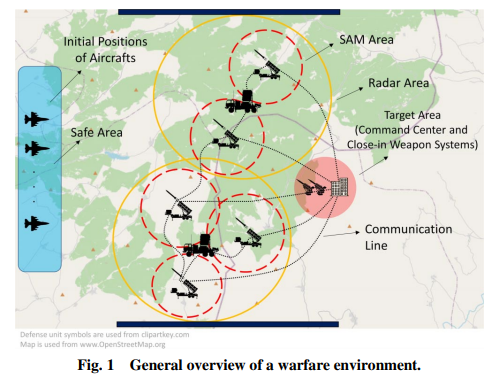
空中飞行器的合作是空对地攻击情况下的另一个重要问题。[1]中指出,自主无人机系统的合作意味着资源共享、信息共享、任务分配和冲突解决。它需要先进的传感器和远程数据链来提高UCAV机群的任务成功率和生存能力。从生存能力的角度来看,合作对于避免UCAVs之间可能发生的碰撞相当重要。因此,在进行飞行路径规划时,应考虑智能体与智能体之间的安全距离。定义UCAV飞行器之间距离和角度的相对几何数据可用于评估这种情况并生成无碰撞的飞行路线。此外,从任务成功的角度来看,合作可用于生成可同时到达目标区域的飞行路线。同时到达是空对地攻击的一个关键作战概念,以便在战争环境中饱和敌人的防空系统。例如,如果机群中的UCAV潜入目标区域并同时向敌方资产发起攻击,防空系统就会饱和,它就无法对UCAV机群作出有效反应。这增加了任务成功的概率,尽管它可能会降低机群中几个UCAV智能体的生存能力。
战争环境中UCAV机群的合作路径规划是一个复杂的问题。正如我们之前提到的,在生成所需路径时,应考虑许多敌方资产。一个成功的合作是通过结合操作者定义的机群的生存能力和任务成功要求而获得的。
在文献中,对UCAV机群的合作路径规划进行了许多研究。在[2]中,UCAV机群的路径规划是通过使用势场方法来压制地表的敌方资产,如雷达、防空导弹和大炮。此外,Voronoi图也被用于同一问题,并与所提出的算法的性能进行了比较。虽然生成的路径是连续和平滑的,但它需要很高的计算成本来解决这个问题。在文献[3]中,通过整合近似的允许攻击区域模型、约束条件和多准则目标函数,提出了UCAV机队执行合作空对地攻击任务的轨迹规划问题。然后,通过结合微分平坦性理论、高斯伪谱法(GPM)和非线性编程,开发了虚拟运动伪装(VMC),以解决合作轨迹最优控制问题。所提出的VMC算法的性能与基于GPM的直接拼合方法进行了比较,后者是为生成最优轨迹而开发的。仿真结果表明,尽管在优化性能上有小的损失,导致次优解,但所提方法能够比GPM算法更快地生成可行的飞行轨迹。
最近航空器的计算和通信能力的进步加速了对合作的研究。将RL应用于自主飞行器的路径规划是文献中的一个新兴话题,因为它能够在适当的情况下解决复杂问题。在文献[4]中,作者通过使用深度强化学习(DRL)为自主地面车辆开发了一个省时的导航策略。他们引入了具有社会意识的DRL防撞方法,并将其推广到多Agent场景中。提出的算法在一个行人众多的环境中进行了测试。在[5]中,开发了一种混合算法,其中包含DRL和基于力的运动规划方法。它被用来解决动态和密集环境中的分布式运动规划问题。根据仿真结果,所提出的算法比DRL方法产生的成功场景多50%,比基于力的运动规划到达目标所需的额外时间少75%。在[6]中,为蜂窝连接的无人机群网络开发了干扰感知路径规划算法。在这一应用中,能源效率与无线延迟和干扰之间存在着权衡。提出了基于回声状态网络的DRL算法来解决路径规划问题。仿真结果显示,与启发式基线方法相比,每个无人机的无线延时和每个地面用户的速率都得到了改善。同时,仿真结果指出了无人机的最佳高度、数据速率要求和地面网络密度之间的关系。在[7]中,DRL被用于使用自主飞机的分布式野火监视。在这个问题上,由于高维状态空间、随机的火灾传播、不完善的传感器信息以及飞机之间需要协调,要最大限度地扩大森林火灾的覆盖范围是相当复杂的。我们开发了两种DRL方法。在第一种方法中,飞机是通过使用单个飞机的即时观测来控制的。在第二种方法中,野火状态和飞机所到之处的时间历史被用作控制器的输入,以提供飞机之间的协作。根据仿真结果,所提出的方法提供了对野火扩张的精确跟踪,并超过了退避水平线控制器。报告还指出,这些方法对于不同数量的飞机和不同的野火形状是可扩展的。在[8]中,DRL算法被用来解决无人驾驶地面车辆(USV)车队的合作路径规划问题。采用了领导者-追随者策略,并制定了一个集中协调方案。为了在车队中提供合作,使用了与避免碰撞和编队形状有关的奖励函数元素。然而,在路径规划问题中没有考虑同时到达。
多智能体强化学习(MARL)也是一种新兴的方法,用于解决包含合作要求的多智能体问题,如同时到达和避免碰撞[9-15]。在[16]中,针对部分可观察情况和网络带宽等有限通信能力下的合作,开发了深度递归多智能体行为者批评框架(R-MADDPG)。实验表明,所提出的R-MADDPG算法能够处理资源限制的问题,并且它能够在同时到达的智能体之间进行协调。然而,空中飞行器的运动学没有被考虑,环境中也没有包括障碍物。在[17]中,通过结合改进的陶氏重力(I-tau-G)制导策略和多智能体Q-Learning(MAQL)算法,为多个无人驾驶飞行器(UAV)开发了分布式4-D轨迹生成方法。考虑了避免碰撞和同时到达的要求来提供合作。
这项研究是[18]的延续,其中对UCAVs进行了基于RL的集中式路径规划。在战争环境中集成了一个五种状态的生存能力模型,包括搜索、探测、跟踪、交战和击中状态。RL智能体的训练阶段是通过使用近似策略优化(PPO)算法进行的。为了定量评估所提系统的有效性,制定了跟踪和命中概率的性能指标,并用于蒙特卡洛分析。仿真结果表明,拟议的算法能够产生可行的飞行路线,同时使UCAV机群的生存概率最大化。然而,将生存能力模型(每个UCAV的五个状态)纳入学习过程增加了观察向量的大小,使系统的扩展变得复杂。另外,[18]中没有研究UCAV机群的合作性能,这也是本研究的主要议题。
本文采用RL方法解决了UCAV机群的路径规划问题。采用集中式结构,将总的观测向量输入单一的RL智能体,并生成总的行动向量,其中包含相关UCAV的单独控制信号。与[18]不同的是,生存能力模型没有被整合到观察向量中以减少向量大小。相反,禁飞区(NFZs)被定义为模拟防空系统,如防空导弹和火炮。除了在[18]中进行的研究外,这里特别关注舰队的合作,这从两个方面得到。首先,研究了UCAV机群同时到达目标区域的情况,这是一种广泛使用的使敌人的防空系统饱和的方法。其次,还研究了避免碰撞的问题,以提供舰队的安全。考虑到这些要求,我们开发了奖励函数。RL智能体的训练阶段是通过使用PPO算法进行的。为避免NFZ、避免碰撞和同时到达的要求制定了几个性能指标,以获得对所提方法的定量评价。通过使用蒙特卡洛分析,在NFZ位置不确定和外部干扰(即风的影响)存在的情况下,根据船队的避免碰撞和同时到达能力,对系统的合作性能进行了评估。
这项研究从两个方面对文献做出了贡献。首先,据作者所知,这是第一次为UCAV机队开发出一种可行的和可操作的基于RL的集中式路径规划方法。例如,与典型的基于PSO的方法相比,基于RL的方法提供了舰队在面对动态和反击/防御威胁时重新规划的实时能力。第二,与目前的方法相比,所提出的方法提供了同时考虑关键操作限制的能力,如同时到达和避免碰撞的要求,同时考虑NFZ限制和系统限制,如UCAVs的横向加速指令限制。例如,典型的方法,如基于PSO的方法,只考虑了这些限制的有限子集,因此它们只适用于现实生活场景的某些方面。考虑到这两个方面的贡献,所提出的方法不仅为现实生活中适用的合作操作能力提供了手段,如关闭速度和近似的时间信息,而且还为高度非线性和大规模的UCAV舰队优化问题提供了一个实时的近似。
本文的其余部分组织如下。在第二部分,解释了路径规划问题中使用的数学模型和相对几何学。在第三部分,给出了RL智能体的一般结构,并描述了训练算法。第四节,给出了仿真结果,并对1)无NFZ和2)有NFZ约束的情况进行了评估。在第五部分,说明了结论和未来的工作。
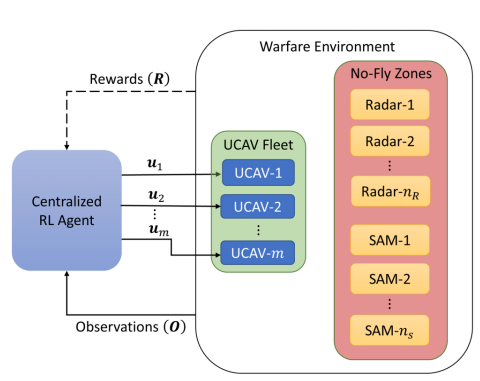
图 3 RL 智能体及其与战争环境交互的总体概述。
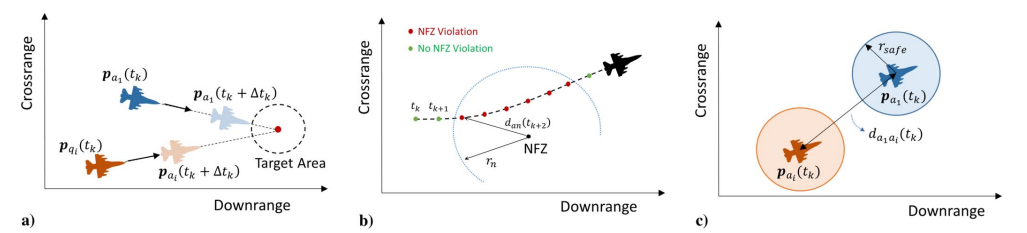
图 4 a) 同时到达、b) NFZ 限制和 c) 避免碰撞的定义。