

简化数据科学基础设施,为数据科学家提供从原型到生产的有效路径。 《高效数据科学基础》是为数据科学和机器学习应用程序组装基础设施的实践指南。它揭示了Netflix和其他数据驱动公司管理尖端数据基础设施的过程。
当您使用这个易于遵循的指南时,您将从头开始设置端到端基础设施,使用一个完全可定制的流程,您可以很容易地适应您的公司。您将了解如何使用现有的云基础设施、一堆开源软件和惯用的Python提高数据科学家的工作效率。在整个过程中,您将遵循以人为中心的方法,重点关注用户体验和满足数据科学家的独特需求。
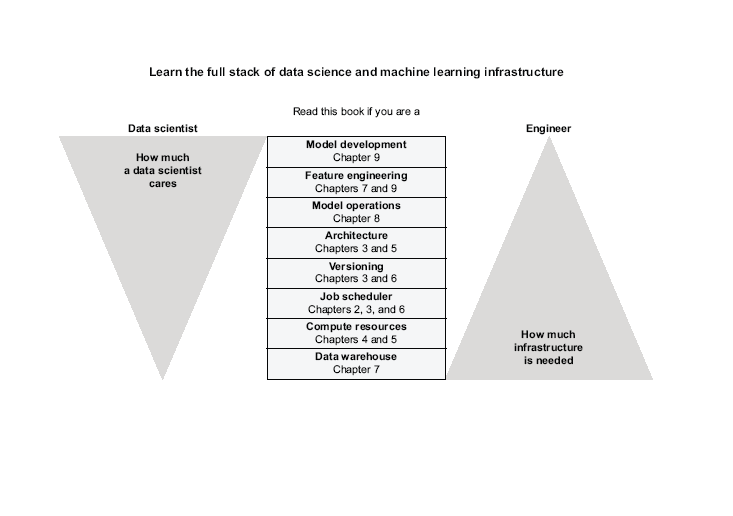
第一章: 介绍 第二章: 数据科学的工具链 第三章: 介绍Metaflow 第四章: 计算层的扩展 第五章: 实践可扩展和性能 第六章: 进入生产阶段 第七章: 处理数据 第八章: 使用和运作模式 第九章: 使用完整堆栈的机器学习
机器学习和数据科学应用是人类构建的最复杂的工程产品,如果你考虑到驱动它们的全部软件和硬件堆栈的话。因此,在今天,在21世纪20年代初,构建这样的应用并不容易,这就不足为奇了。机器学习和数据科学将继续存在。由高级数据驱动技术驱动的应用程序在各个行业中越来越普遍。因此,显然需要使构建和操作这样的应用程序成为一个更轻松、更有纪律的过程。引用阿尔弗雷德·怀特黑德的话:“文明的进步是通过扩展我们无需思考就能执行的重要操作的数量。”这本书教你如何构建一个有效的数据科学基础设施,它允许用户试验创新的应用,将它们部署到生产中,并不断改进它们,而不需要过多考虑技术细节。没有一种千篇一律的方法可以适用于所有的用例。因此,本书关注的是通用的、基本的原则和组件,这些原则和组件可以在您的环境中以一种有意义的方式实现。

成为VIP会员查看完整内容
相关内容

Arxiv
28+阅读 · 2021年6月16日
Arxiv
36+阅读 · 2021年5月27日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
28+阅读 · 2021年6月16日
Arxiv
36+阅读 · 2021年5月27日