

随着高级大型语言模型(LLMs)例如ChatGPT的能力的增强,合成内容生成在多个领域如媒体、网络安全、公共话语和教育中的影响也随之增加。因此,检测LLMs生成的内容的能力已变得至关重要。我们旨在提供对现有检测策略和基准的详细概述,仔细调查它们的差异,并识别该领域的关键挑战和前景,倡导更加适应和鲁棒的模型来增强检测准确性。我们还主张需要多方面的方法来抵御各种攻击,以对抗LLMs的迅速进步能力。据我们所知,这项工作是LLMs时代检测的第一个综合性调研。我们希望它将提供对LLMs生成内容检测的当前景观的广泛理解,为那些努力维护数字信息完整性的研究者和实践者提供一个指导性的参考,特别是在合成内容日益主导的时代。相关论文已被总结,并将持续更新在 https://github.com/Xianjun-Yang/Awesome_papers_on_LLMs_detection.git。

随着强大的AI工具的快速发展,LLMs生成的内容的风险引起了相当大的关注,例如信息传播误导(Bian等人,2023;Hanley和Durumeric,2023;Pan等人,2023)、假新闻(Oshikawa等人,2018;Zellers等人,2019;Dugan等人,2022)、性别偏见(Sun等人,2019)、教育(Perkins等人,2023;Vasilatos等人,2023)和社会伤害(Kumar等人,2023;Yang等人,2023d)。 在图1中,我们展示了一些关于AI写作文本对教育、社交媒体、选举等带来的威胁的主题。我们还在Google搜索趋势中发现,自从最新的强大的大型语言模型(LLMs)如ChatGPT(Schulman等人,2022)和GPT-4(OpenAI,2023b)发布以来,人们对AI写作文本的关注已经显著增加。由于模型大小、数据规模和AI-人类对齐的快速发展,人类已经无法直接区分LLMs和人类写的文本(Brown等人,2020;Ouyang等人,2022)。从那时起,LLMs领域取得了显著的进步,导致在各种NLP任务中内容生成的实质性改进(Qin等人,2023;Yang等人,2023c)。伴随着这些进步,已经出现了大量旨在识别LLMs生成的内容的检测算法。然而,关于LLMs基础检测系统的最新方法、基准和攻击的综合性调查仍然很少。
实际上,AI已经彻底革新了各种模态,包括像DALLE(Ramesh等人,2021)和Imagen(Saharia等人,2022)这样的图像生成模型,像ChatGPT和Bard这样的文本生成模型,像MMS(Pratap等人,2023)这样的音频处理模型,视频生成模型(Singer等人,2022)以及代码生成模型(Chen等人,2021)。过去,已经有努力为图像开发水印技术(Wen等人,2023;Zhao等人,2023c)并成功攻击这些技术(Jiang等人,2023)。此外,还进行了关于在线ChatBots检测的研究(Chew和Baird,2003;Wang等人,2023a)。具体来说,这次调查重点是检测由LLMs生成的文本和代码以及攻击。目前最强大的商业LLMs,例如Anthropic的Claude、OpenAI的ChatGPT和GPT-4,通常采用仅解码器的变压器(Vaswani等人,2017)架构。这些模型有数十亿到数千亿的参数,是在大量文本上训练的,并进一步调整以符合人类的偏好。在推理过程中,文本生成过程涉及使用top-k采样(Fan等人,2018)、核采样(Holtzman等人,2020)结合波束搜索。同时,对检测器,如商业工具GPTZero(Tian,2023)或OpenAI自己的检测器(OpenAI,2023a)的兴趣正在增长,因为人们很容易被解码方法的改进所欺骗(Ippolito等人,2019)。然而,检测器的误用也引起了学生对他们的作业和文章的不公正判断的抗议(Herbold等人,2023;Liu等人,2023b),而且流行的检测器在代码检测上表现不佳(Wang等人,2023b)。
早期的文本检测工作可以追溯到特征工程(Badaskar等人,2008年)。例如,GTLR(Gehrmann等人,2019a)假设生成的词来自于像BERT(Devlin等人,2019年)或GPT2(Radford等人,2019年)这样的小LMs的顶部分布。最近,人们越来越关注检测ChatGPT(Weng等人,2023年;Liu等人,2023b;Desaire等人,2023年),以减轻ChatGPT的误用或滥用(Sison等人,2023年)。特别是,最近已经呼吁对像ChatGPT这样的强大AI的使用进行监管1(Hacker等人,2023年;Wahle等人,2023年)。
因此,我们坚信,现在是进行LLMs生成内容检测的综合调查的理想时机。它将邀请对检测方法的进一步探索,提供关于以前研究的优点和缺点的有价值的见解,并突出研究社区需要解决的潜在挑战和机会。我们的论文的结构如下:我们首先简要描述问题的构成,包括任务定义、度量和数据集在第2部分。在第3部分,我们按照其工作机制和应用范围分类检测。在第4部分,我们总结了三种流行的检测方法:基于训练的、零射击和水印。在第5部分,我们还调查了各种攻击,因为防御攻击越来越重要,并在第6部分指出了一些挑战。最后,在第7部分,我们为这个话题提供了关于潜在的未来方向的额外见解,以及第8部分的结论。

**检测场景 **
之前的研究发现,如(Gehrmann等人,2019b)和(Dugan等人,2022)所示,强调了人类在区分人类和机器生成的文本之间所面临的普遍困难,这促使了自动化解决方案的发展。根据检测器是否能够访问源模型的输出logits,检测过程可以分为黑盒检测或白盒检测。在黑盒检测中,有两个不同的情况:1) 当知道源模型的名称,如GPT-4;2) 当不知道源模型的名称,并且内容可能是由像GPT-4、Bard或其他未公开的模型生成的。另一方面,白盒检测也包括两种情况:1) 检测器只能访问模型的输出logits或部分logits,如text-davinci-003中的前5个token log概率;2) 检测器可以访问整个模型的权重。表2根据应用场景和三种检测方法显示了四个类别。具体来说,我们可以根据其应用将检测LLM生成内容的使用划分为四个不同的场景。这些分类突出了检测器可用的不同信息级别,从有限的知识到完全的访问,并展示了在检测机器生成内容中遇到的各种场景。
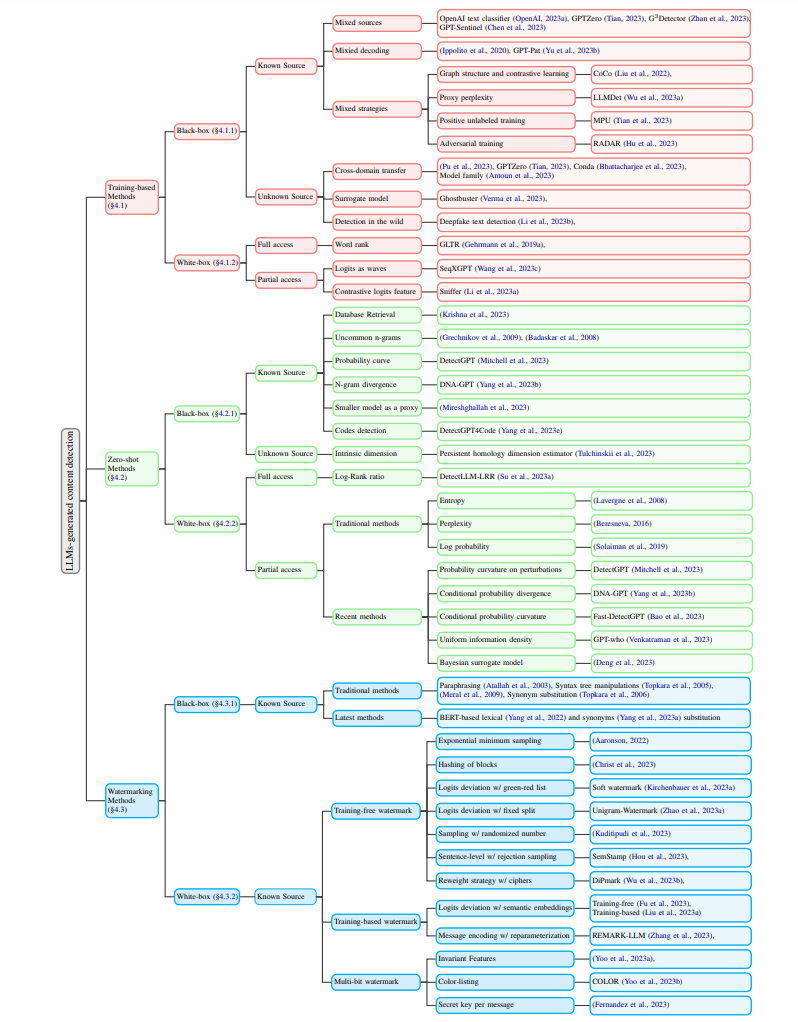
检测方法
在这一部分中,我们将深入探讨检测算法的详细信息。根据它们的鉴别特征,现有的检测方法可以被分类为三类:1) 基于训练的分类器,通常在收集的二元数据上微调一个预训练的语言模型 - 既包括人类生成的文本分布,也包括AI生成的文本分布。**2) 零样本检测器利用典型LLM的固有属性,**如概率曲线或表示空间,来进行自我检测。3) 水印方法涉及在生成的文本中隐藏识别信息,稍后可以用来确定文本是否来自特定的语言模型,而不是一般地检测AI生成的文本。我们在图3中总结了按照第3节列出的场景分类的代表性方法。
结论
我们全面地调查了LLMs生成的内容检测,包括现有的任务制定、基准数据集、评估指标以及在各种场景下的不同检测方法。我们还指出了现有的挑战,例如多样化的攻击方法,并分享了我们对检测未来的看法。我们希望我们的调查能够帮助研究社区迅速了解检测方法论和挑战的进展,并有可能激发出对可靠检测器的迫切需求中更多的想法。