

根据最近大语言模型(LLMs)的流行,已经有多次尝试将其扩展到视觉领域。从拥有可以引导我们穿越陌生环境的视觉助手到仅使用高级文本描述生成图像的生成模型,视觉-语言模型(VLM)的应用将极大地影响我们与技术的关系。然而,为了提高这些模型的可靠性,还有许多挑战需要解决。虽然语言是离散的,但视觉在更高维的空间中演变,其中的概念并不总是容易离散化。为了更好地理解将视觉映射到语言的机制,我们介绍了这篇关于VLMs的综述,希望能帮助任何希望进入该领域的人。首先,我们介绍了什么是VLMs,它们是如何工作的,以及如何训练它们。然后,我们展示并讨论了评估VLMs的方法。尽管这项工作主要关注将图像映射到语言,但我们也讨论了将VLMs扩展到视频的可能性。


近年来,我们在语言建模方面看到了令人印象深刻的发展。许多大型语言模型(LLMs),如Llama或ChatGPT,现在能够解决各种各样的任务,其使用也越来越普及。这些模型主要局限于文本输入,现在已经扩展到包含视觉输入。将视觉与语言连接将开启几个在当前基于AI的技术革命中关键的应用。尽管已经有多项工作将大型语言模型扩展到视觉领域,但语言与视觉的连接并未完全解决。例如,大多数模型在没有复杂的工程开销和额外数据标注的情况下,难以理解空间关系或进行计数。许多视觉语言模型(VLMs)也缺乏对属性和顺序的理解。它们经常忽略输入提示的一部分,导致需要进行大量的提示工程才能得到所需结果。其中一些还会产生幻觉,生成不必要或不相关的内容。因此,开发可靠的模型仍然是一个非常活跃的研究领域。 在这项工作中,我们介绍了视觉语言模型(VLMs)的入门知识。我们解释了什么是VLMs,它们是如何训练的,以及如何根据不同的研究目标有效评估VLMs。本工作不应被视为关于VLMs的综述或完整指南。因此,我们并不打算引用VLM研究领域的每一项工作;也不涵盖该领域的所有最佳实践。相反,我们旨在提供一个清晰且易于理解的VLM研究介绍,并强调在该领域进行研究的有效实践。该介绍特别适合希望进入该领域的学生或其他领域的研究人员。
我们首先介绍不同的VLM训练范式。我们讨论了对比方法如何改变了该领域。接着,我们介绍利用掩码策略或生成组件的方法。最后,我们介绍使用预训练骨干(如LLMs)的VLMs。将VLMs分类成不同的家族并不是一项容易的任务,因为它们中的大多数都有重叠的组件。然而,我们希望我们的分类能帮助新研究人员导航该领域,并揭示VLMs背后的内在机制。
接下来,我们介绍训练VLMs的典型方法。例如,我们涵盖了:根据不同的研究目标,哪些数据集是合适的?哪种数据策展策略?我们是否需要训练一个文本编码器,还是可以利用一个预训练的LLM?对比损失对于理解视觉是否足够,还是生成组件是关键?我们还介绍了用于提高模型性能以及更好地对齐和锚定的常见技术。 提供训练模型的方法是更好地理解VLM需求的关键步骤,而提供对这些模型的稳健和可靠的评估同样重要。许多用于评估VLMs的基准最近已经被引入。然而,其中一些基准有重要的局限性,研究人员应当注意。通过讨论VLM基准的优缺点,我们希望揭示改善我们对VLMs理解的挑战。我们首先讨论评估VLMs视觉语言能力的基准,然后介绍如何衡量偏见。
下一代VLMs将能够通过将视频映射到语言来理解视频。然而,视频面临的挑战与图像不同。计算成本当然更高,但也有其他关于如何通过文本映射时间维度的考虑。通过揭示当前从视频中学习的方法,我们希望强调需要解决的当前研究挑战。
通过降低进入VLM研究的门槛,我们希望为更负责任的发展VLMs提供基础,同时推动视觉理解的边界。
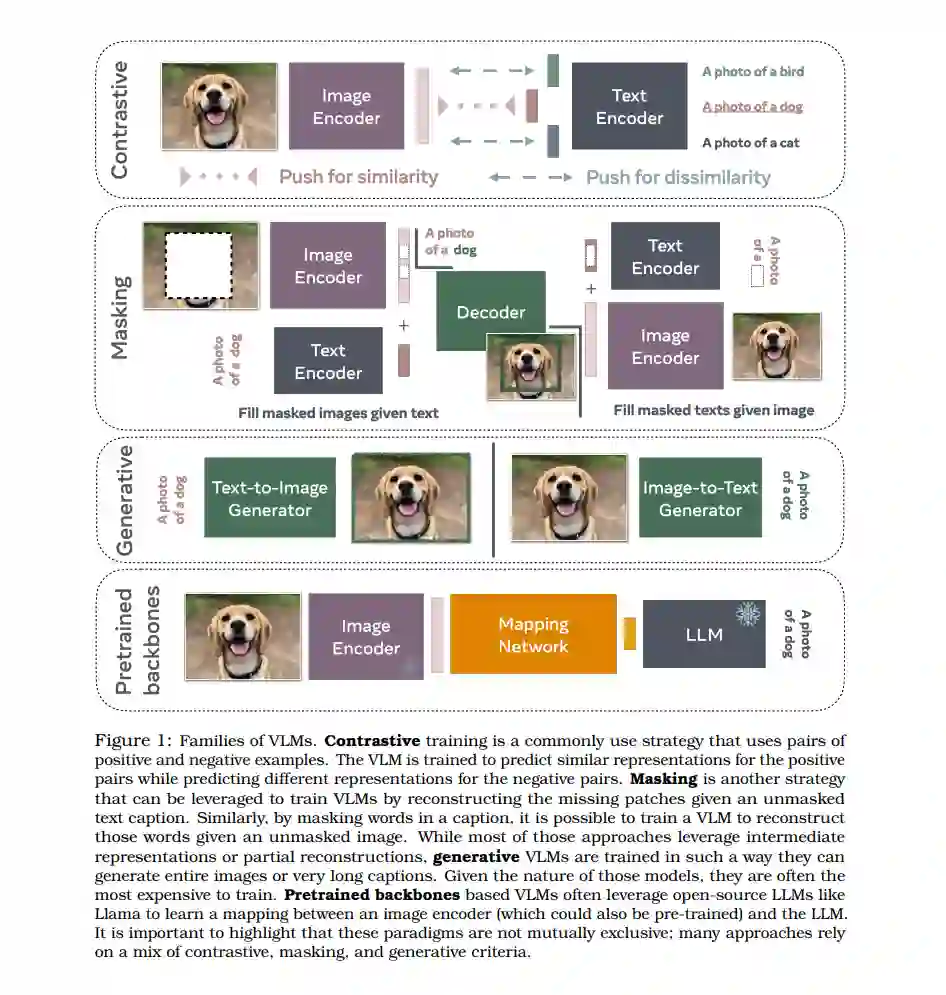
鉴于深度学习在计算机视觉和自然语言处理领域的显著进展,已经有多项将这两个领域桥接起来的倡议。在本文中,我们重点介绍基于Transformers [Vaswani et al., 2017] 的最新技术。我们将这些最新的技术分为四种不同的训练范式(图1)。
第一种是对比训练,这是一个常用的策略,它利用正负样本对。VLM通过训练,使其能够为正样本对预测相似的表示,而为负样本对预测不同的表示。
第二种是掩码策略,通过给定一些未掩码的文本来重建被掩码的图像块。同样,通过掩码标题中的词语,可以训练VLM在给定未掩码图像的情况下重建这些词语。
基于预训练骨干的VLMs通常利用开源的LLMs,如Llama [Touvron et al., 2023],以学习图像编码器(也可以是预训练的)和LLM之间的映射。与从头训练文本和图像编码器相比,学习预训练模型之间的映射通常计算成本较低。
虽然大多数方法利用中间表示或部分重建,生成式VLMs则以能够生成图像或标题的方式进行训练。鉴于这些模型的性质,它们往往是训练成本最高的。 我们强调,这些范式并不是互斥的;许多方法依赖于对比、掩码和生成标准的混合。对于每种范式,我们仅介绍一到两个模型,以便读者对这些模型的设计有一些高层次的见解。

VLM训练指南
多项研究 [Henighan et al., 2020b,a] 强调了扩展深度神经网络规模以提升其性能的重要性。受到这些扩展规律的启发,最近的工作主要集中在增加计算能力和模型规模以学习更好的模型。这导致了诸如CLIP [Radford et al., 2021] 这样的模型的出现,该模型使用了400M张图像进行训练,计算预算非常高。即使是相应的开源实现OpenCLIP [Ilharco et al., 2021] 也使用了256到600个GPU,训练时间长达数天或数周,具体取决于模型规模。然而,最近的研究 [Sorscher et al., 2022] 表明,通过数据策展流水线,可以超越扩展定律。在本节中,我们首先讨论训练模型时数据的重要性,并介绍一些用于创建训练VLMs数据集的方法。接着,我们讨论从业者可能用来更高效地训练VLMs的常用软件、工具和技巧。由于训练VLMs的方法不同,我们还讨论了在特定情况下选择哪种类型的模型。最后,我们介绍了一些提高锚定(正确将文本与视觉线索匹配)的技巧。我们还介绍了使用人类偏好改进对齐的方法。由于VLMs经常用于读取和翻译文本,我们也介绍了一些可以进一步提升VLMs OCR能力的技术。最后,我们讨论了常见的微调方法。

负责的VLM评估方法
由于VLMs的主要能力是将文本与图像进行映射,因此测量视觉-语言能力至关重要,以确保文字确实与视觉线索相匹配。早期用于评估VLMs的任务是图像描述和视觉问答(VQA)[Antol et al., 2015]。在本节中,我们还讨论了评估模型从图像中理解和读取文本能力的文本中心VQA任务。另一个由Radford等人 [2021] 引入的常见评估方法基于零样本预测,例如ImageNet [Deng et al., 2009] 分类任务。这类分类任务对于评估VLM是否具备足够的世界知识非常重要。更近期的基准如Winoground [Thrush et al., 2022] 测量视觉-语言组合推理。由于VLM模型已知会表现出偏见或幻觉,因此评估这两个组成部分也很重要。
扩展VLMs至视频
我们迄今为止的重点是训练和评估基于静态视觉数据(即图像)的VLMs。然而,视频数据为模型带来了新的挑战和潜在的新功能,例如理解物体的运动和动态,或在空间和时间中定位物体和动作。文本到视频的检索、视频问答和生成迅速成为计算机视觉的基本任务 [Xu et al., 2015, Tapaswi et al., 2016, Brooks et al., 2024]。视频的时间维度对存储、GPU内存和训练提出了新的挑战,例如,24帧每秒的视频需要24倍的存储和处理,如果每帧都被视为图像。这需要在视频VLMs中进行权衡,例如使用压缩形式的视频(例如,H.264编码)并在数据加载器中即时解码视频;从图像编码器初始化视频编码器;视频编码器具有空间/时间池化/掩码机制 [Fan et al., 2021, Feichtenhofer et al., 2022];非端到端VLMs(离线提取视频特征并训练模型,这些模型采用视频特征而不是长视频的像素帧)。与图像-文本模型类似,早期的视频-文本模型从头开始训练视觉和文本组件,并采用自监督标准 [Alayrac et al., 2016]。但与图像模型不同的是,对比视频-文本模型并不是首选方法,视频和文本的早期融合和时间对齐更受青睐 [Sun et al., 2019],因为与计算视频的全局表示相比,表示中的时间粒度更为有趣。最近,视频-语言模型中也出现了类似于图像-语言模型的趋势:预训练的LLMs被用于与视频编码器对齐,增强LLMs的视频理解能力。现代技术如视觉指令微调也被广泛使用并适应于视频。
结论
将视觉映射到语言仍然是一个活跃的研究领域。从对比方法到生成方法,有许多训练VLMs的方法。然而,高计算和数据成本常常成为大多数研究人员的障碍。这主要激励了使用预训练的LLMs或图像编码器,仅学习模态之间的映射。无论训练VLMs的方法是什么,都有一些普遍的考虑需要记住。大规模高质量的图像和标题是提升模型性能的重要因素。改进模型的锚定能力和与人类偏好的对齐也是提高模型可靠性的重要步骤。 为了评估性能,已经引入了多个基准来测量视觉语言和推理能力;然而,其中许多基准有严重的局限性,如仅使用语言先验就能解决。将图像与文本绑定并不是VLMs的唯一目标;视频也是一种可以用来学习表示的重要模态。然而,在学习良好的视频表示之前,还有许多挑战需要克服。VLMs的研究仍然非常活跃,因为要使这些模型更可靠,还需要很多缺失的组件。