

大型模型,包括大型语言模型和扩散模型,已在接近人类智能方面展现出卓越的潜力,引起了学术界和工业界的极大兴趣。然而,这些大型模型的训练需要大量的高质量数据,而且随着这些模型的持续更新,现有的高质量数据资源可能很快就会耗尽。这一挑战促使人们大量研究数据增强方法。利用大型模型,这些数据增强技术已超越传统方法。本文提供了一篇关于大型模型驱动的数据增强方法的全面综述。我们首先建立了相关研究的分类,分为三个主要类别:**图像增强、文本增强和配对数据增强。**接着,我们深入探讨了与基于大型模型的数据增强相关的各种数据后处理技术。我们的讨论随后扩展到这些数据增强方法在自然语言处理、计算机视觉和音频信号处理等领域的应用范围。我们继续评估基于大型模型的数据增强在不同场景中的成功与局限性。在我们的综述中,我们突出了数据增强领域未来探索的潜在挑战和途径。我们的目标是为研究人员提供关键洞察,最终有助于更复杂大型模型的发展。我们持续维护相关的开源材料在: https://github.com/MLGroup-JLU/LLM-data-aug-survey。
数据增强,作为机器学习中的关键策略,解决了用有限的标记数据训练不同任务模型的挑战。它涉及增强训练样本的充足性和多样性,而无需显式收集新数据,因此在提高模型泛化方面起着至关重要的作用(Feng et al., 2021; Shorten and Khoshgoftaar, 2019)。数据增强的本质在于通过各种变换改变现有数据点来生成新数据。这防止了模型记忆无关的数据模式,增强的数据紧密反映了真实数据的分布(Cubuk et al., 2019; Wei and Zou, 2019)。这些技术直接适用于监督学习(Liu et al., 2021c)并且可以通过一致性规则化(Zhang et al., 2021a)在半监督学习中用于未标记数据。最初为计算机视觉(CV)开发的数据增强方法通过裁剪、旋转和色彩调整等操作创建人工图像(Kanwal et al., 2022; Krell and Kim, 2017; Takahashi et al., 2019)。在自然语言处理(NLP)中,类似的方法包括随机字符插入、单词删除和同义词替换(Liu et al., 2020; Shorten and Khoshgoftaar, 2019)。
数据增强的重要性在学术和工业领域引起了广泛关注。作为一个活跃的研究领域,它解决了机器学习中对大量高质量标记数据的日益增长的需求,这一需求在现实世界中往往无法满足。尽管在过去几十年中,特别是在深度学习技术方面,数据增强取得了显著进展,但这些方法仍然难以捕捉现实世界数据的复杂性(Feng et al., 2021),生成可扩展数据(Yang et al., 2022),并抵御对抗性示例(Qiu et al., 2020)。
为了应对这些限制,当前研究正在探索创新技术来增强数据增强方法的效果和多样性。其中,大型模型,包括大型语言模型(Zhao et al., 2023)和扩散模型(Yang et al., 2023),显示出相当大的潜力。大型语言模型(LLMs),如GPT-4(OpenAI, 2023a)和Llama2(Touvron et al., 2023b),已经革新了NLP。这些模型以Transformer架构(Vaswani et al., 2017)为特点,并在广泛的语料库上进行训练,擅长理解和生成类似人类的文本,标志着机器学习能力的重大进步(Zhao et al., 2023)。这些拥有数十亿参数的模型可以承担包括代码生成(Zhang et al., 2023b)和数据增强(Dai et al., 2023)在内的多样化和复杂任务,为人工通用智能(AGI)的实现铺平了道路。
扩散模型(Ho et al., 2020; Song et al., 2020),一种新的最先进的生成模型家族,在计算机视觉中的图像合成方面超越了长期占据主导地位的生成对抗网络(GANs)(Goodfellow et al., 2014)(Dhariwal and Nichol, 2021; Ho et al., 2020)。与变分自编码器(VAEs)(Kingma and Welling, 2013)和GANs等先前模型不同,扩散模型通过迭代添加和逆转噪声来生成高质量的合成图像,并已实现文本到图像的生成(Saharia et al., 2022),扩展了数据增强的范围。
方法论
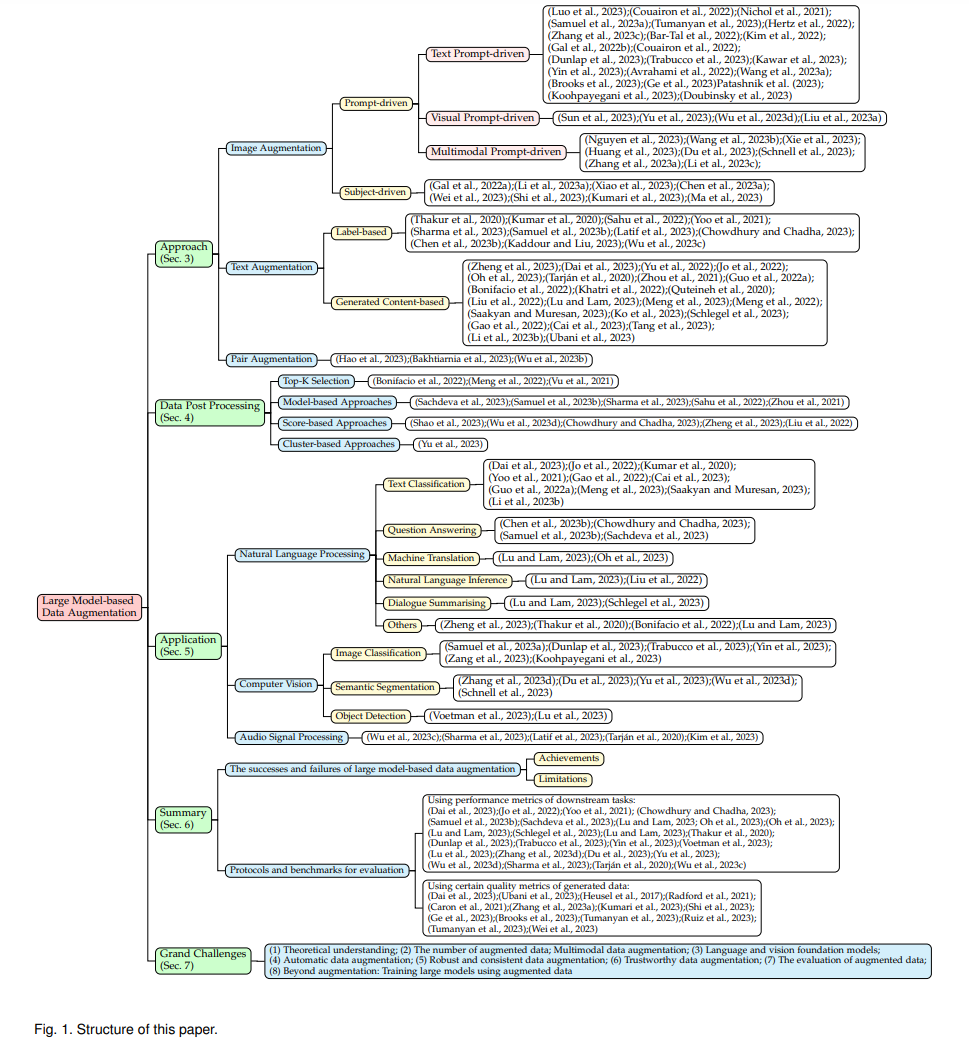
大型模型的出现彻底改变了数据增强的方式,提供了与传统方法相比更具多样性的创新和有效手段来生成训练数据。本节将现有的方法基于目标数据类型分为三个不同的类别:图像增强、文本增强和配对数据增强。图像增强涉及扩展图像数据,文本增强涉及扩展文本数据,而配对数据增强则涉及两者。这些方法反映了数据增强的最新趋势,突出了大型模型的重要作用。
图像增强图像增强通过额外信息的指导来合成逼真的图像。我们将这些技术分为基于提示的和基于主题的方法:在基于提示的类别中包括文本、视觉和多模态方法;在基于主题的类别中包括针对特定主题的策略。文本提示驱动的方法从文本描述中生成图像,视觉提示驱动的方法使用视觉线索,而多模态提示驱动的方法结合了文本描述和视觉指导。基于主题的方法为特定主题量身定制增强。这些方法提升了深度学习任务的性能,有助于更加健壮的训练体验。现有方法在表3中总结。

文本增强
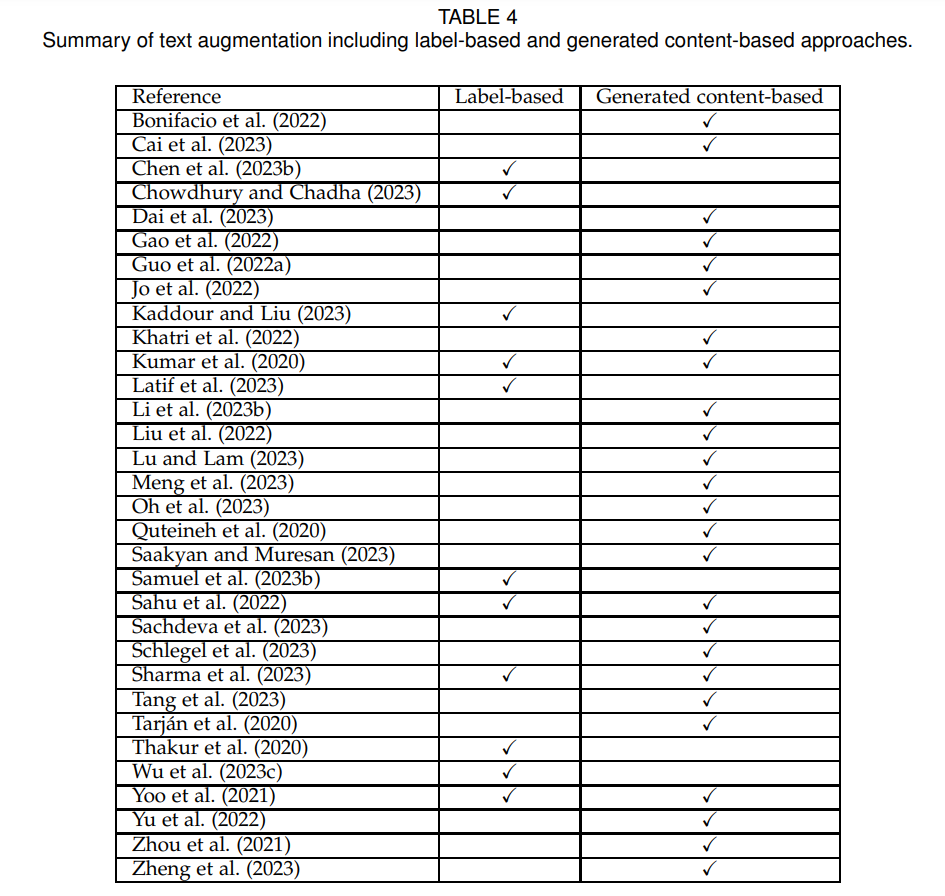
文本增强着重于利用大型模型的先进能力来增强文本数据集,包括两种策略:基于标签的和基于生成内容的。在基于标签的方法中,模型被用于注释文本数据,有效地丰富了文本数据集,增加了更多的标记实例。基于生成内容的策略指导模型合成新的文本数据,从而扩展了数据集,增加了新生成的文本材料。现有方法在表4中展示。
配对数据增强
MixGen(Hao et al., 2023)是一种用于视觉-语言表示学习的数据增强方法,通过图像插值和文本连接生成具有保留语义关系的图像-文本对。Bakhtiarnia等人(2023)提出了一种名为PromptMix的方法,该方法从现有数据集中提取文本描述,使用提取的文本作为输入到潜在扩散模型以生成类似于现有数据集中的图像,使用高性能的重量级网络对生成的图像进行注释,并将这个假数据集与真实数据混合,以改善轻量级深度神经网络的训练。为了解决视觉语言数据集中的报告偏差问题,特别是对象属性关联对训练模型的潜在有害影响,Wu等人(2023b)提出了一种称为BigAug的双模态增强方法。这种方法利用对象属性解耦来合成不同的视觉语言示例,并创建跨模态的硬否定。LLM和基础对象检测器的整合有助于提取目标对象,其中LLM为每个对象提供详细的属性描述。这些描述以及相应的硬否定接着被用来通过修补模型生成图像。这个明确的过程引入了缺失的对象和属性以供学习,其中硬否定指导模型区分对象属性。
总结
在本节中,我们提供了对我们在第3、4和5节中审查的主要发现的综合概述。 基于大型模型的数据增强仍然是一个充满机会和挑战的领域。本调查旨在全面审查基于大型模型的数据增强方法,伴随的数据后处理技术以及在下游任务中的应用。 它还仔细分类了现有的基于大型模型的数据增强方法。通过总结和分析当前的研究工作,我们确定了当前方法的成功和失败,并辨别了基于大型模型的数据增强的新趋势。此外,我们总结了用于评估基于大型模型的数据增强的现有方法。最重要的是,这些总结可以帮助提出未来研究的新挑战和机会。

