
多智能体强化学习是AI中的热点技术之一,来自爱丁堡大学Stefano V. Albrecht, Filippos Christianos, Lukas Schäfer编著的《多智能体强化学习:基础与现代方法》详述MARL中的模型、解决方案概念、算法思想和技术挑战提供基础介绍。

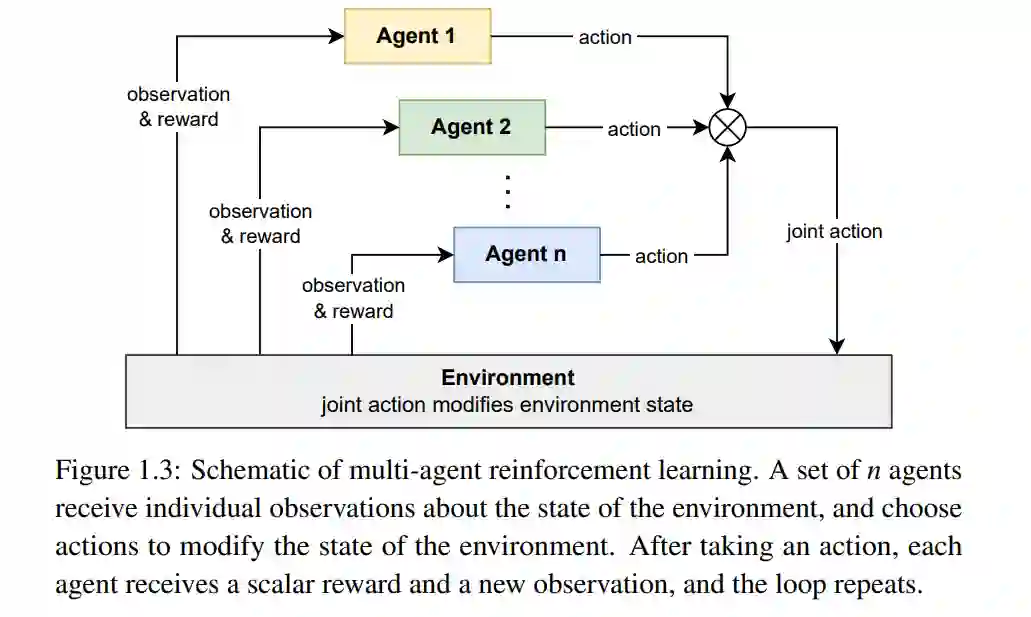
多智能体强化学习(Multi-agent Reinforcement Learning,MARL)是一个多样且极为活跃的研究领域。自2010年代中期将深度学习引入MARL以来,该领域的活动迅猛增长,所有主要的人工智能和机器学习会议上都会定期发布开发新的MARL算法或以某种方式应用MARL的论文。这种快速增长也可以从已发表的综述论文数量的增加得到证明,附录A中列出了其中许多论文。在这种增长的背景下,人们意识到该领域需要一本教材,以提供对MARL的系统介绍。本书在某种程度上基于并主要遵循Stefano V. Albrecht和Peter Stone于2017年在澳大利亚墨尔本举行的国际人工智能联合会议上所提供的教程《多智能体学习:基础与最新趋势》的结构。本书的撰写目的是为MARL中的模型、解决方案概念、算法思想和技术挑战提供基础介绍,并描述整合深度学习技术以产生强大新算法的现代MARL方法。我们认为,本书涵盖的内容应该为每个MARL研究者所知。此外,本书旨在为研究人员和实践者在使用MARL算法时提供实用指导。为此,本书附带了用Python编程语言编写的代码库,其中包含了本书讨论的多个MARL算法的实现。代码库的主要目的是提供自包含且易于阅读的算法代码,以帮助读者理解。想象一个场景,在这个场景中,一个由自主智能体组成的集体,每个智能体都有能力做出自己的决定,他们必须在一个共享环境中互动,以达成某些目标。这些智能体可能有一个共享的目标,比如一个移动机器人的车队,其任务是在一个大型仓库内收集和运送货物,或者一个负责监控海上石油钻井平台的无人机队伍。智能体也可能有冲突的目标,比如在一个虚拟市场上交易商品的智能体,每个智能体都试图最大化自己的收益。由于我们可能不知道这些智能体应该如何互动以达成他们的目标,所以我们让他们自己去解决。因此,这些智能体开始在他们的环境中尝试行动,并收集关于环境如何随着他们的行动而变化,以及其他智能体如何行为的经验。随着时间的推移,这些智能体开始学习各种概念,如解决任务所需的技能,以及重要的,如何与其他智能体协调他们的行动。他们甚至可能学会发展一种共享的语言,以便智能体之间的通信。最后,这些智能体达到了一定的熟练程度,成为了互动优化以达成他们目标的专家。这个令人兴奋的愿景,简而言之,就是多智能体强化学习(MARL)希望达成的目标。MARL基于强化学习(RL),在这种学习中,智能体通过尝试行动和接收奖励来学习最优决策策略,目标是选择能在时间内最大化累积奖励的行动。而在单一智能体的RL中,重点是为单一智能体学习最优策略,在MARL中,重点是为多个智能体学习最优策略以及在这个学习过程中出现的独特挑战。在这第一章中,我们将开始概述MARL中的一些基础概念和挑战。我们首先介绍多智能体系统的概念,这是由环境、环境中的智能体及其目标定义的。然后我们讨论了MARL如何在这样的系统中运作以学习智能体的最优策略,并通过一些潜在应用的例子来说明。接下来我们讨论了MARL中的一些关键挑战,如非稳定性和均衡选择问题,以及几种描述MARL可以如何使用的不同“议程”。在本章的结尾,我们对这本书的两部分中涵盖的主题进行了概述。多智能体强化学习(MARL)算法为多智能体系统中的一组智能体学习最优策略。与单一智能体的情况一样,这些策略是通过试错过程来学习的,目标是最大化智能体的累积奖励,或者说回报。图1.3显示了MARL训练循环的基本示意图。一组n个智能体选择个体行动,这些行动一起被称为联合行动。联合行动按照环境动态改变了环境的状态,并且智能体由于这种变化收到个体奖励,同时也对新环境状态有个体观察。这个循环持续进行,直到满足终止条件(比如一位智能体赢得了一场象棋比赛)或无限期地进行。这个循环从初始状态到终止状态的完整运行被称为一个情节。通过多个独立情节产生的数据,即每个情节中经历的观察、行动和奖励,被用来持续改进智能体的策略。
这本书为大学生、研究者和从业者提供了关于多智能体强化学习理论和实践的介绍。在这个引言章节之后,本书的剩余部分分为两部分。本书的第一部分提供了关于MARL中使用的基本模型和概念的基础知识。具体来说,第二章对单一智能体RL的理论和表格算法进行了介绍。第三章介绍了基本的游戏模型,以定义多智能体环境中的状态、行动、观察和奖励等概念。然后,第四章介绍了一系列解决概念,这些概念定义了解决这些游戏模型意味着什么;也就是说,智能体如何最优地行动意味着什么。最后,第五章介绍了在游戏中应用MARL来计算解决方案时的一些基础算法思想和挑战。本书的第二部分侧重于当代利用深度学习技术创建新的强大MARL算法的MARL研究。我们首先在第六章和第七章分别对深度学习和深度强化学习进行了介绍。基于前两章,第八章介绍了近年来开发的一些最重要的MARL算法,包括集中化训练与分散化执行、价值分解和参数共享等思想。第九章在实施和使用MARL算法以及如何评估学习到的策略时提供了实用指导。最后,第十章描述了在MARL研究中开发的一些多智能体环境的例子。
这本书的一个目标是为想在实践中使用本书中讨论的MARL算法,以及开发他们自己的算法的读者提供一个起点。因此,这本书配有自己的MARL代码库(可从书籍网站下载),该代码库使用Python编程语言开发,提供了许多现有的MARL算法的实现,这些实现是自包含的,易于阅读。第九章使用代码库中的代码片段来解释早些章节中提出的算法背后的重要概念的实现细节。我们希望所提供的代码能够帮助读者理解MARL算法,并开始在实践中使用它们。







