
Leiden大学Aske Plaat教授《深度强化学习》2022新书,值得关注!

深度强化学习近年来备受关注。在自动驾驶、游戏、分子重组和机器人等各种活动中,他们都取得了令人印象深刻的成果。在所有这些领域,计算机程序已经学会了解决困难的问题。他们学会了飞行模型直升机和表演特技动作,如回旋和翻滚。在某些应用中,他们甚至比最优秀的人类还要优秀,比如Atari、Go、扑克和星际争霸。深度强化学习探索复杂环境的方式提醒我们,孩子们是如何学习的,通过开玩笑地尝试东西,获得反馈,然后再尝试。计算机似乎真的拥有人类学习的各个方面; 这是人工智能梦想的核心。教育工作者并没有忽视研究方面的成功,大学已经开始开设这方面的课程。这本书的目的是提供深度强化学习领域的全面概述。这本书是为人工智能的研究生写的,并为希望更好地理解深度强化学习方法和他们的挑战的研究人员和实践者。我们假设学生具备本科水平的计算机科学和人工智能知识;本书的编程语言是Python。我们描述了深度强化学习的基础、算法和应用。我们将介绍已建立的无模型和基于模型的方法,它们构成了该领域的基础。发展很快,我们还涵盖了一些高级主题: 深度多智能体强化学习、深度层次强化学习和深度元学习。
https://deep-reinforcement-learning.net/
这本书的目的是呈现在一个单一的深度强化学习的最新见解,适合教学一个研究生水平一个学期的课程。除了涵盖最先进的算法,我们涵盖经典强化学习和深度学习的必要背景。我们还涵盖了自我游戏、多主体、层次和元学习方面的先进的、前瞻性的发展。
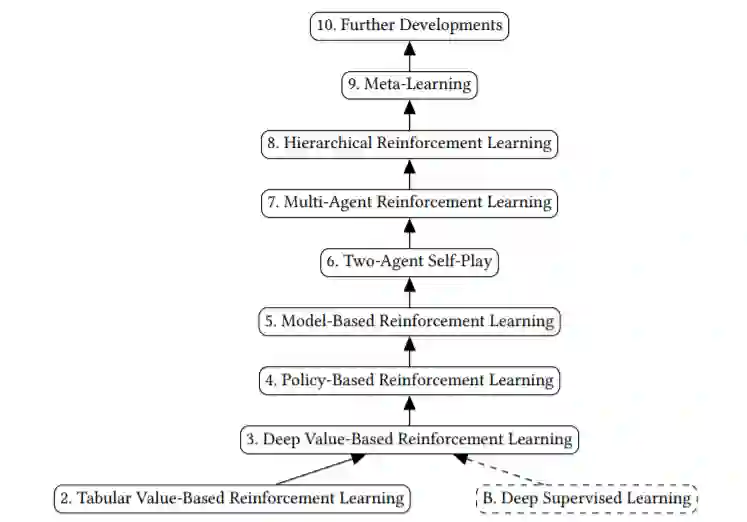
深度强化学习建立在深度监督学习和表格强化学习的基础上
在这些章节中有很多材料,既有基础的,也有先进的,有很多文献。一种选择是讲授一门关于书中所有主题的课程。另一种选择是慢一些、深入一些,在基础知识上花足够的时间,创建关于Chaps. 2-5的课程,以涵盖基本主题(基于值、基于策略和基于模型的学习),并创建关于Chaps. 6-9的单独课程,以涵盖多智能体、分层和元学习等更高级的主题。
在这一介绍性的章节之后,我们将继续学习第二章,在第二章中,我们将详细讨论表格(非深度)强化学习的基本概念。我们从马尔可夫决策过程开始,并详细讨论它们。第三章解释了基于深度价值的强化学习。本章涵盖了为寻找最优策略而设计的第一个深度算法。我们仍将在基于价值、无模型的范式中工作。在本章的最后,我们将分析一个自学如何玩上世纪80年代Atari电子游戏的玩家。下一章,第四章,讨论了一种不同的方法:基于深度策略的强化学习。下一章,第5章,介绍了基于深度模型的强化学习与学习模型,该方法首先建立环境的过渡模型,然后再建立策略。基于模型的强化学习有希望获得更高的样本效率,从而加快学习速度。



