通过自编码的视觉分词器赋能最先进的图像和视频生成模型,通过将像素压缩到潜在空间中。尽管基于Transformer的生成器的扩展是近期进展的核心,但分词器组件本身却很少被扩展,这引发了关于自编码器设计选择如何影响其重建目标和下游生成性能的开放问题。我们的工作旨在通过探索自编码器的扩展,填补这一空白。
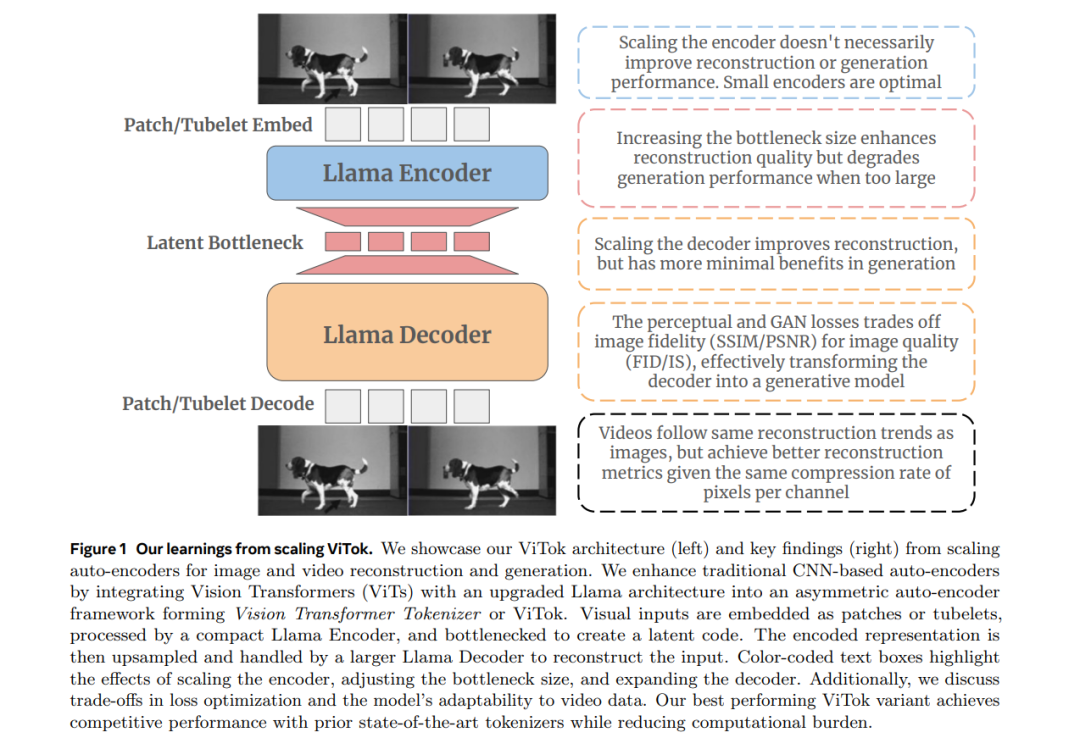
为了促进这一探索,我们用增强版视觉Transformer架构(ViTok)替代了典型的卷积骨干网络进行分词。我们在超越ImageNet-1K的大规模图像和视频数据集上训练ViTok,消除了分词器扩展中的数据限制。我们首先研究了扩展自编码器瓶颈如何同时影响重建和生成——结果发现,尽管扩展与重建高度相关,但其与生成的关系则更为复杂。接着,我们探索了分别扩展自编码器的编码器和解码器对重建和生成性能的影响。关键发现是,扩展编码器对重建和生成的提升几乎微乎其微,而扩展解码器则显著提升重建性能,但对生成的效果则是喜忧参半的。
基于我们的探索,我们设计了ViTok,作为一种轻量级自编码器,在ImageNet-1K和COCO的重建任务(256p和512p)上,表现出与最先进自编码器竞争的性能,同时在UCF-101的16帧128p视频重建任务中超越了现有自编码器,且FLOPs减少了2-5倍。当与扩散Transformer结合时,ViTok在ImageNet-1K的图像生成任务中展现了竞争力,并为UCF-101的类别条件视频生成设立了新的最先进基准。
1 引言
现代的高保真图像和视频生成方法(Brooks 等,2024;Polyak 等,2024;Genmo,2024;Esser 等,2024)依赖于两个组件:一个将像素编码到低维潜在空间并随后解码的视觉分词器,以及一个建模该潜在表示的生成器。尽管许多研究通过扩展基于Transformer的架构(Vaswani 等,2017;Dosovitskiy 等,2021)来改进生成器,但分词器本身,主要基于卷积神经网络(LeCun 等,1998)(CNNs),却很少成为扩展努力的重点。 本文研究了视觉分词器是否应当与生成器一样,进行同等的扩展工作。为实现这一目标,我们首先解决了两个主要瓶颈:架构限制和数据规模问题。首先,我们用基于Transformer的自编码器(Vaswani 等,2017)替换了卷积骨干网络,特别是采用了增强版的视觉Transformer(ViT)(Dosovitskiy 等,2021)架构,并结合了Llama(Touvron 等,2023),该架构在大规模训练中已显示出良好的效果(Gu 和 Dao,2023;Sun 等,2024)。我们得到的自编码器设计,称为视觉Transformer分词器(ViTok),可以与扩散Transformer(DiT)(Peebles 和 Xie,2023)的生成管道无缝结合。其次,我们在大规模、野外图像数据集上训练我们的模型,这些数据集大大超过了ImageNet-1K(Deng 等,2009),并将我们的方法扩展到视频,确保我们的分词器扩展不受数据限制。在这种设置下,我们研究了分词器扩展的三个方面: * 扩展自编码器瓶颈:瓶颈的大小与重建指标相关。然而,当瓶颈变得过大时,由于通道大小增加,生成性能会下降。 * 扩展编码器:尽管人们可能期望更深的编码器能够捕获更丰富的特征,但我们的研究发现,扩展编码器并未改善结果,甚至可能适得其反。特别地,更复杂的潜在表示可能更难解码和建模,导致整体性能下降。 * 扩展解码器:扩展解码器能提高重建质量,但对下游生成任务的影响仍不确定。我们假设解码器在一定程度上充当生成器的角色,根据有限的信息填充局部纹理。为了验证这一点,我们遍历了包括GAN(Goodfellow 等,2014)在内的不同损失函数,并观察到PSNR(测量与原始图像的保真度)与FID(衡量分布对齐但忽略一对一对应关系)之间存在权衡。
综合来看,这些结果表明,仅扩展自编码器分词器并不是在当前自编码器范式中提升生成指标的有效策略(Esser 等,2021)。我们还观察到,类似的瓶颈趋势也适用于视频分词器。然而,ViTok更加有效地利用了视频数据中的固有冗余,在固定的每通道像素压缩率下,能够比图像重建获得更优的指标。我们总结了我们的发现,并在图1中展示了我们的方法ViTok。 基于我们的实验结果,我们将表现最好的分词器与先前的最先进方法进行了比较。ViTok在256p和512p分辨率下的图像重建和生成性能,匹敌或超越了当前最先进的分词器,尤其在ImageNet-1K(Deng 等,2009)和COCO(Lin 等,2014a)数据集上,且FLOPs减少了2-5倍。在视频应用中,ViTok超越了当前最先进的方法,在UCF-101(Soomro,2012)数据集上实现了16帧128p视频重建和类别条件视频生成的最先进结果。