

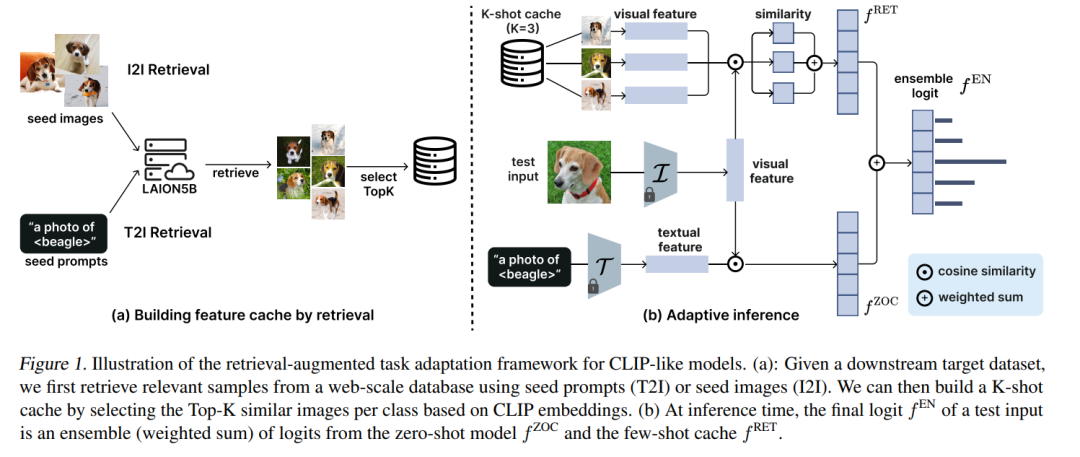
预训练的对比视觉-语言模型在广泛的任务中展示了卓越的性能。然而,它们经常在未在预训练期间充分代表的类别上的微调数据集中遇到困难,这使得适应变得必要。近期的研究通过使用来自网络规模数据库的样本进行检索增强适应,尤其在数据稀缺的情况下,显示了有希望的结果。尽管经验上取得了成功,理解检索如何影响视觉-语言模型的适应仍然是一个开放的研究问题。在这项工作中,我们通过呈现一个系统研究来采用反思性视角,以理解检索增强适应中关键组件的角色。我们揭示了关于单模态和跨模态检索的新见解,并强调了对有效适应至关重要的逻辑整合的关键作用。我们进一步提出了直接支持我们经验观察的理论基础。 https://www.zhuanzhi.ai/paper/115cd78619f4df0ed80226da85a630f3
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日