

随着机器学习(ML)驱动的软件应用程序的趋势不断增加,ML操作(MLOps)的范式引起了研究人员和从业者的极大关注。MLOps涵盖了使ML模型操作化的资源和监控需求的实践和技术。软件开发从业者需要详细且易于理解的MLOps工作流程、实践、挑战和解决方案的知识,以有效地支持MLOps的采用。尽管有关MLOps的学术和行业文献迅速增长,但系统性综述和分析大量现有MLOps文献的尝试相对较少,导致获取和理解这些知识的难度较大。我们对150篇相关学术研究和48篇灰色文献进行了多声道文献综述(MLR),以提供关于MLOps的全面知识体系。通过这次MLR,我们识别了新兴的MLOps实践、采用挑战和与各个领域相关的解决方案,包括复杂管道的开发和操作、大规模生产管理、工件管理以及确保质量、安全性、治理和伦理方面。我们还报告了MLOps在整个生命周期中涉及的不同角色和协作实践的社会技术方面。我们认为,这次MLR为希望在快速发展的MLOps领域中导航的研究人员和从业者提供了宝贵的见解。我们还确定了需要解决的开放问题,以推进当前MLOps的最新技术水平。 引言
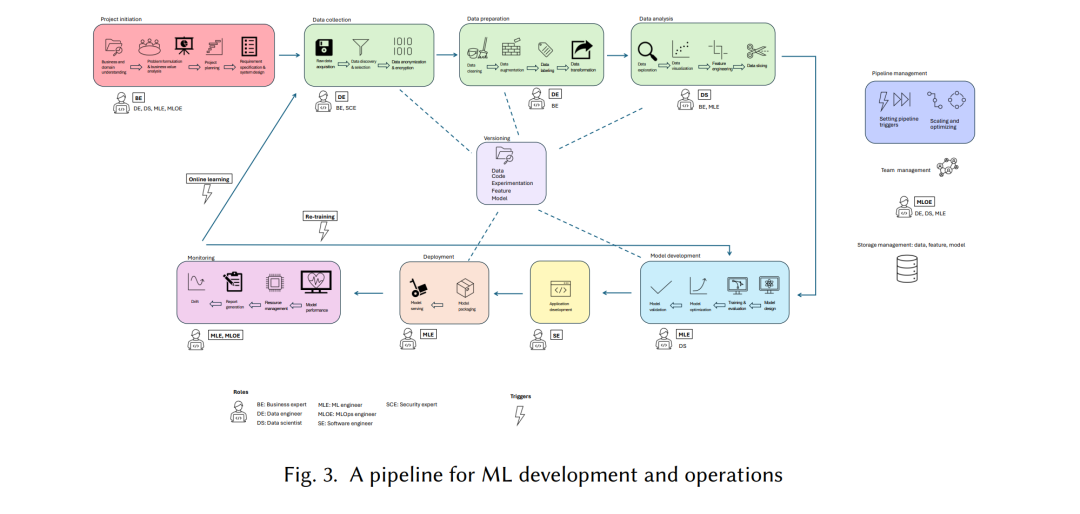
目前,将人工智能(AI)和机器学习(ML)组件整合到软件系统中以利用其成熟的推理和预测能力的趋势非常强劲。这些系统被称为ML驱动系统,通过数据驱动的决策提供了增强的业务价值。对AI/ML驱动解决方案的需求增加以及支持这些系统工程的最新技术/工具的可用性提升了AI/ML的采用率。根据IBM 2022年全球AI采用指数报告,AI/ML的采用正在迅速增加,2022年有44%的组织在其产品或流程中嵌入AI/ML。然而,将AI/ML组件投入生产(即将实验性的ML模型转化为在生产环境中运行的ML驱动软件产品)仍然是主要挑战之一。大多数开发ML试点的组织由于ML驱动软件系统与传统软件相比的新型操作挑战,未能将其模型部署到生产环境或未能维持已部署模型的成功运行。这些挑战包括模型开发过程中引入的ML特有的技术债务、持续监控的需要、由于ML系统的数据依赖性概率特性而需要的模型再训练和交付、数据科学家、软件工程师和软件运营商之间的协作、确保负责任和可信AI的关键需求以及ML驱动系统的集成和扩展的复杂性。为了应对这些挑战,MLOps作为一种范式应运而生,引入了实践、流程、技术和工具,以实现ML系统的快速和可靠生产化。 MLOps最早于2015年由研究社区提出,作为一种加速ML生命周期管理并实现业务应用期望的高可扩展性的解决方案,通过简化ML模型操作化所需的时间和资源。类似于DevOps,MLOps的概念源于生产挑战,由行业推动,并涵盖了广泛的实践、技术和技术。例如,MLOps的一个显著方面是定义和管理自动化管道,例如将ML驱动软件测试和部署到生产环境。这种管道可以被视为负责ML驱动软件生命周期的团队之间重复但隐藏的流程的编纂。自动化这些流程可能会减少人为错误并提高其速度。此外,定义管道的行为可能是促进团队之间沟通的催化剂,并有助于识别瓶颈和陷阱。另一个常被提及与MLOps相关的实践是为数据集、特征和模型建立和利用共享版本控制库,以为自动化管道提供一致的事实来源,并增加跨团队的可见性以减少重复工作。MLOps伞下的另一个相关实践是按需监控服务,这可以启动并增加反馈循环的准确性。当连接到管道时,改进的监控可以提高速度。研究表明,ML驱动系统的适当操作化依赖于利用这种稳健的MLOps实践、流程和技术。根据Databricks进行的调查,尽管进入生产环境的ML模型的百分比仍然很低,但随着MLOps解决方案(例如MLFlow、Huggingface、SageMaker、Google Vertex AI)的快速进步,这一比例有显著增加。截至2023年1月,34%的实验模型被注册为生产候选者,而2022年这一比例为20%。 MLOps在弥合ML驱动软件系统开发和部署之间的差距方面的显著成功引起了研究人员和从业者的极大兴趣,他们越来越多地报告了支持MLOps的不同类型的实践和工具。由于ML系统的构建尚未如传统软件系统那样成熟,且由于其固有的复杂性,不同组织往往根据其独特的用例和组织结构,采用各种方法来开发和操作化ML系统。MLOps涵盖了从数据收集到模型维护的一系列活动,支持和自动化每个活动的大量实践、工具和技术,以及跨学科协作(数据科学家、ML工程师、软件工程师、MLOps工程师)。这种固有的复杂性和多样性使得从业者和研究人员更难以在当前的MLOps领域中导航,从而阻碍了MLOps实践和解决方案的有效采用和进一步改进。尽管关于MLOps的同行评审文献和灰色文献数量不断增加,但由于其复杂性、多样性和广泛的范围,围绕MLOps的混淆仍然显著。 因此,系统地选择、分析和组织涵盖MLOps各个方面的文献(例如MLOps的认知方式、MLOps实践和技术、MLOps采用挑战及相关解决方案)是非常重要的。虽然有一些尝试对MLOps的最新状态进行综述,但这些研究仅审查了学术文献,未涵盖MLOps的几个重要方面。鉴于MLOps是一个应用性很强的范式,并且有大量的灰色文献主要由行业发布。此外,自之前的综述以来,关于MLOps的同行评审文献也显著增长,迫切需要对同行评审和灰色文献进行全面综述,以构建关于MLOps的基于证据的知识体系。 我们进行了系统的多声道文献综述(MLR),涵盖截至2023年9月发布的关于MLOps的同行评审和灰色文献。本研究旨在系统地选择、综合和分析关于MLOps认知、最佳实践、采用挑战和解决方案的最新状态,以构建一个供对MLOps感兴趣的研究人员和从业者使用的知识体系。 我们的研究主要贡献,与研究问题(RQs)相关,具体如下:
- 通过MLR构建了一个基于证据的MLOps知识体系,涵盖了同行评审和灰色文献。
- 帮助我们更好地理解研究人员和从业者如何看待MLOps,包括MLOps的定义(RQ1.1)、活动(RQ1.2)、角色和责任(RQ1.3)。
- 系统地识别和分析支持MLOps的最新最佳实践(即流程、技术和技术)(RQ2)。
- 确定从业者在MLOps采用过程中面临的挑战,并得出改善MLOps采用的未来研究方向(RQ3)。
方法论
我们进行了多声道文献综述(MLR),以全面概述MLOps的定义、活动、涉及人员及其职责、实施MLOps的最新最佳实践、从业者面临的MLOps采用挑战,并将其与文献中提出的解决方案进行映射。 MLR研究允许研究人员在正式/学术文献不足时收集和呈现来自行业的信息【17】。由于MLOps是AI和软件工程领域的新兴话题,仅考虑学术出版物不足以涵盖与该主题相关的所有知识。行业从业者一直在实施和积累MLOps的经验,以将ML驱动系统集成到他们的软件开发管道中,他们的知识是理解MLOps的关键要素。因此,灰色文献(如行业白皮书、博客文章和公司网站)是扩展从学术文献中获得的知识的重要来源。因此,我们认为MLR是MLOps主题最适合的方法。我们按照Garousi等人【17】报告的指南进行MLR。 因此,我们的MLR包括三个主要阶段:1)计划综述,2)进行综述,3)报告综述。计划阶段包括确定综述的需求、指定研究问题(RQs)、制定包含同行评审和灰色文献搜索字符串的综述协议,并定义初级研究选择的纳入/排除标准。在第二阶段,我们进行了同行评审和灰色文献的搜索,并选择了初级研究。随后,按照Braun等人【8】提出的主题分析指南进行了数据提取和综合。在最后阶段,我们组织并报告了综合数据。图1展示了我们的MLR方法论。 结论 由于数据和机器学习的实验性质、生产环境的动态特性、新数据流的持续可用性以及去中心化计算基础设施(即边缘-云集成环境)的存在,使得ML模型的生产化对从业者来说极具挑战。因此,MLOps引入了实践和技术,以创建与持续集成、持续交付、持续训练和持续监控相关的自主工作流,旨在提高ML模型从开发到部署的透明度、模型质量以及支持负责任和安全的AI。这使得MLOps在从业者和学术界中成为热门话题。然而,由于MLOps本身的复杂性以及来自行业和学术界的快速贡献,使得在当前的MLOps领域中导航变得具有挑战性。 我们系统地选择并分析了150篇相关学术研究和48篇灰色文献,以通过回答三个研究问题来全面概述当前的MLOps领域:1)研究人员和从业者如何看待MLOps,2)为MLOps提出的支持解决方案和最佳实践是什么,3)从业者在采用MLOps时面临的挑战是什么。我们基于对MLOps采用挑战和现有解决方案的综合分析,提出了未来的研究方向,以推动未来的MLOps研究。从业者和研究人员可以利用本研究中提供的关于MLOps的严格分析和见解,以增加对MLOps文化、技术和社会技术方面的理解,指导MLOps在其ML驱动应用生产化过程中的采用,并推动未来的进步以改善MLOps的采用。