大型语言模型(LLM)正在变革AI行业,在个人助手[1]、代码辅助[2]、芯片设计[3]和科学发现[4]等广泛任务和应用中展示了卓越的能力。这场革命的成功建立在以GPT[5]、LLaMA[6]、Gemini[7]等为代表的前所未有规模的基于变压器的LLM之上。此外,证据表明LLM的规模化尚未达到瓶颈[8]。这种趋势显著改变了基础训练系统和基础设施的设计,因为LLM通常遵循相对固定的架构,其训练独占了庞大的GPU集群长达数月。例如,LLaMA-3的预训练在Meta的生产集群上使用16K H100-80GB GPU耗时约54天[9]。
LLM训练在可扩展性、效率和可靠性(“SER”)方面对当今的训练系统和基础设施提出了重大挑战。可扩展性要求基础设施和系统能够无缝适应成千上万的GPU或AI加速器的大型集群,同时保持训练正确性和模型精度。这需要在硬件配置、网络和训练框架方面的创新解决方案。效率关注于最大化整个集群的资源利用率,通常以模型浮点运算(MFU)来衡量。实现高MFU涉及优化计算、最小化通信开销以及在前所未有的规模上高效管理内存。可靠性对于LLM训练至关重要,通常训练持续数周到数月。系统必须保持一致的性能,并对各种类型的故障具有弹性,包括硬件故障、网络问题和软件错误。它应能快速检测并从这些故障中恢复,而不会显著丧失进度或训练质量。这些相互关联的挑战需要系统和基础设施设计的整体方法,推动大规模分布式计算的边界,并为高性能机器学习系统的研究和创新开辟新途径。
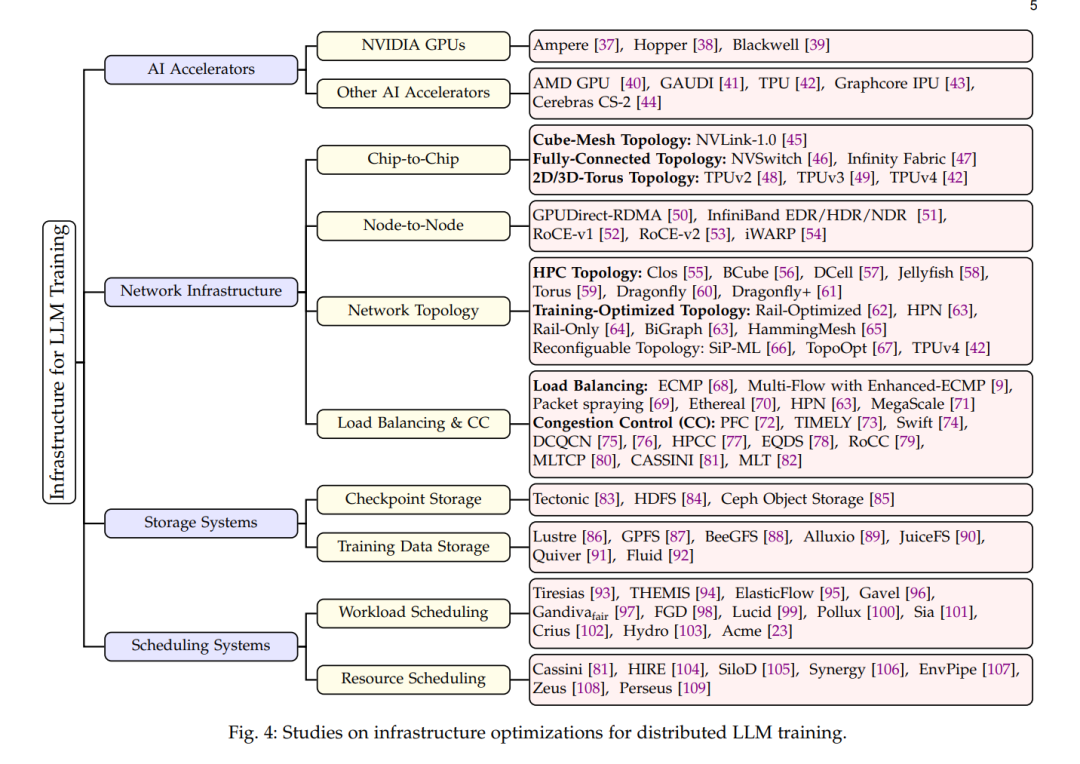
本综述论文旨在全面概述LLM训练系统和基础设施的进展,解决上述挑战。本综述从分布式训练基础设施到训练系统,涵盖了GPU集群、高性能网络和为LLM工作负载量身定制的分布式存储系统的创新方法。我们还探讨了分布式训练系统的关键方面,包括提高可扩展性和效率的并行策略、计算、通信和内存优化。我们深入研究了提高训练可靠性的容错机制。通过综合最近的进展并确定未来的研究方向,本综述旨在为研究人员和实践者提供对改进LLM训练系统最有前景途径的见解。我们的目标是提供一个有价值的资源,不仅解决当前的挑战,还为大规模机器学习基础设施的未来创新铺平道路。
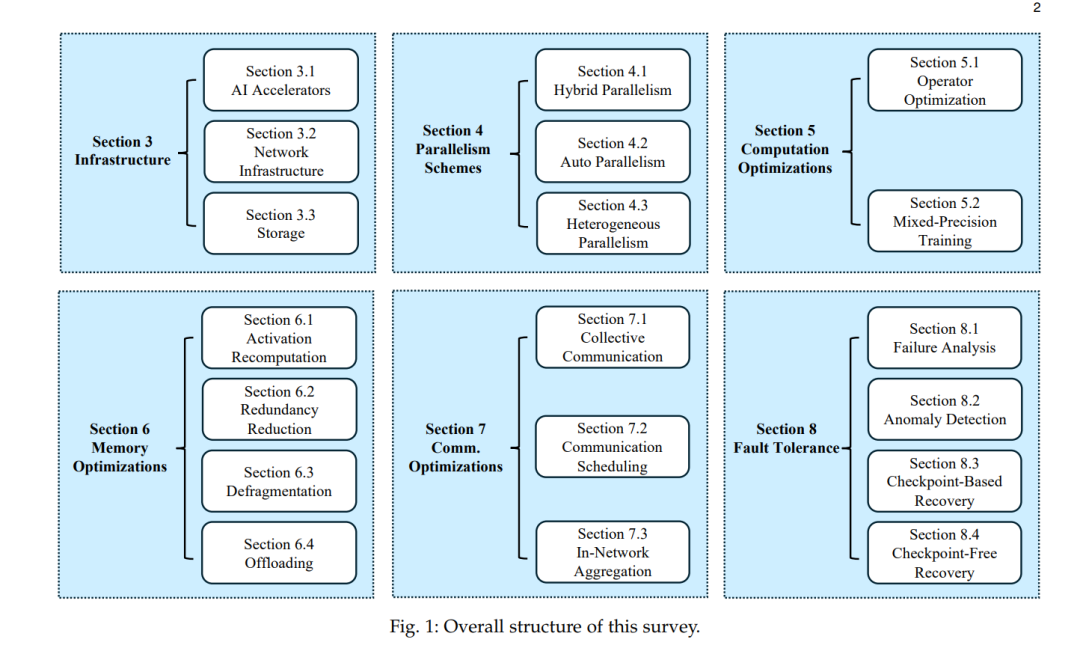
组织结构。图1展示了本综述的组织结构。第2节讨论LLM架构、LLM训练的特点和挑战的背景信息。在第3节中,我们总结了训练基础设施的关键方面,包括AI加速器、网络基础设施和存储系统。在第4节中,我们研究了分布式LLM训练的并行方案。在第5节中,我们讨论了利用前所未有的计算能力的计算优化。在第6节中,我们讨论了LLM训练中优化内存占用的技术。在第7节中,我们介绍了最小化通信开销的通信优化。在第8节中,我们首先进行故障分析,然后介绍快速故障检测和恢复的方法。最后,我们在第9节总结了本综述。