与只考虑文本的传统情感分析相比,多模态情感分析需要同时考虑来自多模态来源的情感信号,因此更符合人类在现实场景中处理情感的方式。它涉及处理来自各种来源的情感信息,如自然语言、图像、视频、音频、生理信号等。然而,尽管其他模态也包含多样的情感线索,自然语言通常包含更丰富的上下文信息,因此在多模态情感分析中总是占据关键位置。ChatGPT的出现为将大型语言模型(LLMs)应用于文本中心的多模态任务打开了巨大的潜力。然而,目前尚不清楚现有的LLMs如何能更好地适应文本中心的多模态情感分析任务。本综述旨在:(1)全面回顾文本中心的多模态情感分析任务的最新研究,(2)探讨LLMs在文本中心的多模态情感分析中的潜力,概述其方法、优势和局限性,(3)总结基于LLM的多模态情感分析技术的应用场景,以及(4)探索未来多模态情感分析的挑战和潜在研究方向。
引言
基于文本的情感分析是自然语言处理领域中的一项关键研究任务,旨在自动揭示我们对文本内容持有的潜在态度。然而,人类往往在多模态环境中处理情感,这与基于文本的情感分析在以下几个方面有所不同:
人类能够获取并整合多模态细粒度信号。人类经常处于多模态情境中,通过语言、图像、声音和生理信号的综合效果,能够无缝理解他人的意图和情感。当处理情感时,人类能够敏锐地捕捉并整合来自多种模态的细粒度情感信号,并将其关联起来进行情感推理。
多模态表达能力。人类表达情感的方式包括语言、面部表情、身体动作、语音等。例如,在日常对话中,我们的自然语言表达可能是模糊的(如某人说“好吧”),但当结合其他模态信息(如视觉模态中的快乐面部表情或音频模态中的拉长语调)时,表达的情感是不同的。
显然,在多模态环境中研究情感分析使我们更接近于人类真实的情感处理。对具有类人情感处理能力的多模态情感分析技术的研究将为现实世界中的应用提供技术支持,如高质量智能伴侣、客户服务、电子商务和抑郁症检测。
近年来,大型语言模型(LLMs)展示了令人惊叹的人机对话能力,并在广泛的自然语言处理任务中表现出色,表明它们具有丰富的知识和强大的推理能力。同时,增强理解图像等模态能力的大型多模态模型(LMMs)也为多模态相关任务提供了新的思路。它们可以直接进行零样本或少样本上下文学习,无需监督训练。虽然已经有一些尝试将LLMs应用于基于文本的情感分析,但对于LLMs和LMMs在多模态情感分析中的应用缺乏系统和全面的分析。因此,目前尚不清楚现有的LLMs和LMMs在多模态情感分析中的适用程度。 鉴于自然语言在多模态情感分析中的关键作用及其作为当前LLMs和LMMs的重要输入,我们集中于可以利用LLMs提升性能的文本中心的多模态情感分析任务,如图文情感分类、图文情绪分类、音频-图像-文本(视频)情感分类等。在这项工作中,我们旨在全面回顾基于LLMs和LMMs的文本中心的多模态情感分析方法的当前状态。具体而言,我们关注以下问题:
LLMs和LMMs在各种多模态情感分析任务中的表现如何?
在各种多模态情感分析任务中,利用LLMs和LMMs的方法有什么不同,它们各自的优势和局限性是什么?
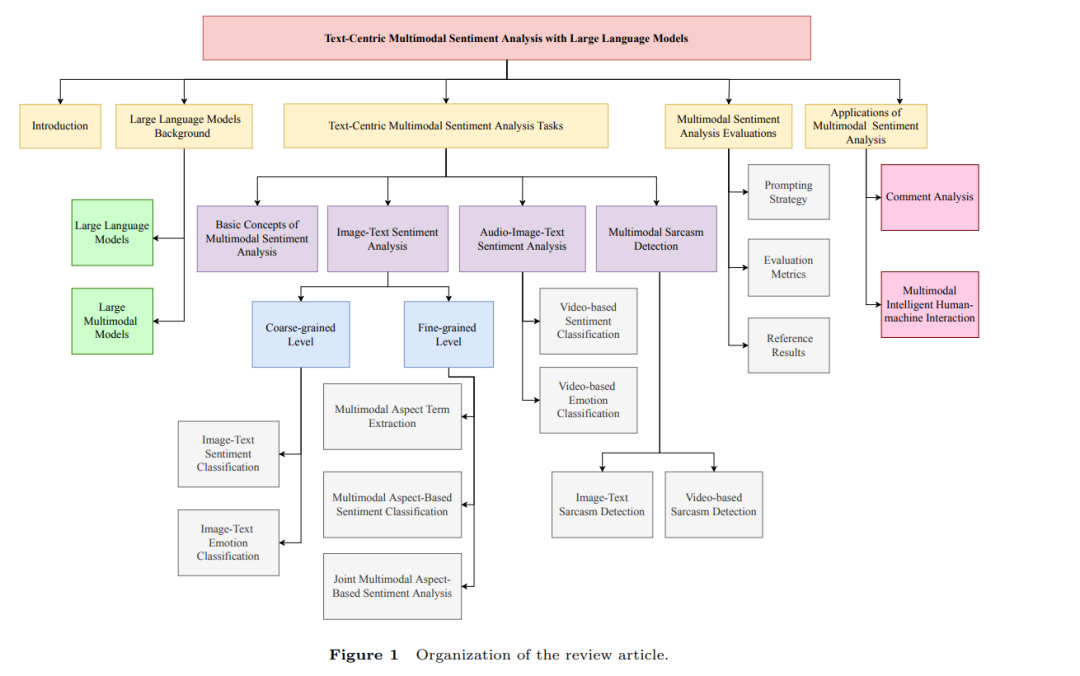
多模态情感分析的未来应用场景是什么? 为此,我们首先介绍文本中心的多模态情感分析任务及其最新进展。我们还概述了当前技术面临的主要挑战,并提出潜在解决方案。我们分析了总共14个多模态情感分析任务,这些任务传统上是独立研究的。我们分析了每个任务的独特特征和共性。综述研究的结构如图1所示。由于LMMs也是基于LLMs的,为了方便表述,下面基于LLMs的方法包括基于LMMs的方法。
本文的其余部分组织如下。第2节介绍LLMs和LMMs的背景知识。第3节对广泛的文本中心多模态情感分析任务进行了广泛的综述,详细描述了任务定义、相关数据集和最新方法。我们还总结了LLM在多模态情感分析任务中相比于以前技术的优势和进展,以及仍然面临的挑战。第4节介绍了基于LLMs的文本中心多模态情感分析方法的提示设置、评估指标和参考结果。第5节展望了多模态情感分析的未来应用场景,并在第6节做出总结性评论。
大型语言模型
一般来说,大型语言模型(LLMs)指的是具有数百亿甚至更多参数的Transformer模型,这些模型通过在大量文本数据上进行高成本训练,如GPT-3 [2]、PaLM [22]、Galactica [23] 和 LLaMA2 [24]。LLMs通常具备广泛的知识,并展示出在理解和生成自然语言以及解决实际复杂任务方面的强大能力。LLMs展示了一些小模型所不具备的能力,这是LLMs与以往预训练语言模型(PLMs)的最显著区别,例如上下文学习(ICL)能力。
假设语言模型已获得自然语言指令和几个任务演示,它可以通过完成输入文本的词序列来生成测试实例的预期输出,而无需额外的训练或梯度更新;指令跟随。通过对通过自然语言描述格式化的多任务数据集进行微调(称为指令适配),LLMs在未见过的任务上表现出色。这种通过微调指令,使得LLMs能够在不使用明确示例的情况下遵循新任务的任务指令,从而提高泛化能力。逐步推理。对于小型语言模型(SLMs),通常难以解决涉及多步推理的复杂任务,例如数学词题。相反,通过使用连锁思维(CoT)提示策略[25–27],LLMs可以利用涉及中间推理步骤的提示机制来解决此类任务并得出最终答案。
已经有一些初步尝试评估LLMs在文本情感分析任务中的表现。在[7]中,作者观察到LLMs的零样本性能可以与微调的BERT模型[105]相媲美。此外,在[8]中,作者对ChatGPT在一些情感分析任务中的能力进行了初步研究,特别研究了其处理极性变化、开放域场景和情感推理问题的能力。在[9]中,作者全面测试了LLMs在文本情感分析数据集中的有效性。在[28]中,作者测试了商用LLMs在基于视频的多模态情感分析数据集上的有效性。尽管已有的努力,范围通常仅限于部分任务,并涉及不同的数据集和实验设计。我们的目标是全面总结LLMs在多模态情感分析领域的表现。
大型多模态模型
大型多模态模型(LMMs)旨在处理和整合各种数据类型,如文本、图像、音频和视频。LMMs通过引入额外的模态扩展了LLMs的能力,从而更全面地理解和生成多样化的内容。LMMs的发展是为了更准确地反映人类交流和感知的多模态性质。虽然传统的LLMs如GPT-4主要是基于文本的,LMMs能够处理和生成跨各种数据类型的输出。例如,它们可以解释视觉输入、生成图像的文本描述,甚至处理音频数据,从而弥合不同信息形式之间的差距。
LMMs的关键进展之一是创建统一的多模态嵌入空间。这涉及为每种模态使用单独的编码器生成特定数据的表示,然后将这些表示对齐到一个一致的多模态空间。这种统一的方法允许模型无缝整合和关联来自不同来源的信息。著名的例子包括Gemini [111]、GPT-4V和ImageBind [110]。这些模型展示了处理文本、图像、音频和视频的能力,增强了翻译、图像识别等功能。
除了这些知名模型,其他新兴模型也取得了显著进展:BLIP-2 [112]引入了一种新的方法,通过Q-former模块将冻结的预训练视觉编码器与冻结的大型语言模型集成。这个模块使用可学习的输入查询与图像特征和LLM交互,允许有效的跨模态学习。这种设置在保持LLM的多功能性的同时,能够有效地结合视觉信息。LLava [113]是一种集成预训练的CLIP [116]视觉编码器(ViT-L/14)、Vicuna [115]语言模型和一个简单的线性投影层的大型多模态模型。其训练分为两个阶段:特征对齐预训练,仅使用595K图文对照对来自Conceptual Captions数据集[118]训练投影层;以及端到端微调,使用158K指令跟随数据和ScienceQA数据集[117]微调投影层和LLM。这种设置确保了视觉和文本信息的有效整合,使LLava在图像字幕生成、视觉问答和视觉推理任务中表现出色。Qwen-VL [114]在多模态领域表现出色。Qwen-VL在零样本图像字幕生成和视觉问答任务中表现突出,支持中英文文本识别。Qwen-VL-Chat增强了多图像输入和多轮问答的交互能力,在理解和生成多模态内容方面展示了显著改进。
参数冻结范式和参数调优范式
在[208]中,作者总结了利用大型语言模型(LLMs)的两种范式:参数冻结范式和参数调优范式。
参数冻结应用:这种范式直接在LLMs上应用提示方法,而不需要对模型参数进行调整。根据是否需要少样本演示,参数冻结应用包括零样本学习和少样本学习。
参数调优应用:这种范式需要对LLMs的参数进行调整。根据是否需要对所有模型参数进行微调,参数调优应用包括全参数调优和参数高效调优。
以文本为中心的多模态情感分析任务
以文本为中心的多模态情感分析主要包括图文情感分析和音频-图像-文本(视频)情感分析。其中,根据不同的情感注释,最常见的任务是情感分类任务(如最常见的三分类任务:积极、中立和消极)和情绪分类任务(包括快乐、悲伤、愤怒等情绪标签)。与基于文本的情感分类类似,以文本为中心的多模态情感分析也可以根据观点目标的粒度分为粗粒度多模态情感分析(如句子级别)和细粒度多模态情感分析(如方面级别)。 现有的细粒度多模态情感分析通常集中在图文配对数据上,包括多模态方面术语抽取(MATE)、多模态基于方面的情感分类(MASC)以及联合多模态方面-情感分析(JMASA)。此外,多模态讽刺检测近年来也成为一个广泛讨论的任务。由于需要分析不同模态情感之间的冲突,它突显了非文本模态在现实场景中情感判断中的重要性。我们将在以下小节中介绍这些任务,并在表1中对它们进行总结。