

因果推断在统计、市场营销、医疗保健和教育等各个领域的解释性分析和决策中起着重要作用。其主要任务是估计处理效果并制定干预政策。传统上,以往的大多数工作通常集中在二元处理设置,即一个单位要么采用要么不采用某种处理。然而,实际上,处理可以更加复杂,涵盖多值、连续或组合选项。在本文中,我们将这些称为复杂处理,并系统全面地回顾了处理它们的因果推断方法。首先,我们正式重新审视了问题定义、基本假设及其在特定条件下可能的变体。其次,我们依次回顾了与多值、连续和组合处理设置相关的方法。在每种情况下,我们试探性地将方法分为两类:符合无混杂假设的方法和违反无混杂假设的方法。随后,我们讨论了可用的数据集和开源代码。最后,我们对这些工作进行了简要总结,并提出了未来研究的潜在方向。
因果推断在许多领域中具有广泛应用,如统计学、市场营销、流行病学、教育、推荐系统等。尽管关联模型在这些领域中引起了兴趣,但它们仅限于独立同分布(i.i.d.)数据的特定设置。相反,因果方法在确定特定干预或处理对结果的实际影响时,已经考虑到了这种数据分布差距。形式上,处理效应是指在采取特定处理的情况下,与不采取处理的情况下所产生的结果差异。这种估计不仅对效果测量有帮助,还对一些下游任务如预测、决策、特征选择和解释性分析有帮助。
估计处理效应的关键挑战是控制混杂偏差。这意味着混杂因素可能同时影响自变量(处理)和因变量(结果),从而导致因果关系和处理效应的错误估计。例如,在研究吸烟对肺癌影响时,年龄是一个混杂因素,因为年龄既可能影响一个人是否吸烟,也可能影响罹患肺癌的概率。
在实践中,估计处理效应的金标准方法是随机对照试验(RCTs),即随机分配处理给个体。然而,进行RCTs通常很昂贵,并且很难揭示复杂处理的效果。此外,特别是在医学场景中,这可能与伦理原则相冲突。例如,在研究某种药物对死亡率的影响时,强迫患者接受或不接受某种处理是不道德和非法的。因此,许多最新研究集中于如何从自然收集的观察数据中精确估计处理效应。本文我们重点回顾观察性研究中的因果推断方法。 为了正式研究这个问题,我们采用了因果推断文献中广泛使用的潜在结果框架。已经出现了各种方法,包括基于倾向评分的方法、基于表示的方法、生成建模方法等。倾向评分估计了在给定协变量的情况下,样本采取特定处理的条件概率。在倾向评分的基础上,提出了匹配、分层和重新加权等方法来控制混杂偏差。进一步考虑选择偏差,利用倾向评分的平衡性质模拟观察数据中的随机化。为了控制来自不同个体的变量分布,发展了平衡方法,包括熵平衡、协变量平衡倾向评分、近似残差平衡和核平衡。随着深度学习的进展,最近的研究应用神经网络学习个体协变量的表示,然后通过假设网络推断潜在结果。这些方法鼓励两个组表示之间的相似性,有助于分布平衡。包括平衡神经网络(BNN)、反事实回归(CFR)、重要性采样权重的反事实回归(CFR-ISW)、Dragonnet等。此外,还有一些利用多任务学习和元学习的方法。生成建模方法是另一种主流方法,利用生成对抗网络(GAN)或变分自编码器(VAE)。GANITE是前者的代表,通过生成器直接生成潜在结果。对于后者,主要思想是通过重构损失和分布差异测量获得目标的潜在变量或嵌入。具体来说,因果效应VAE(CEVAE)中的目标是未测量的混杂因素,它们被恢复为潜在变量并用于随后因果效应的估计。
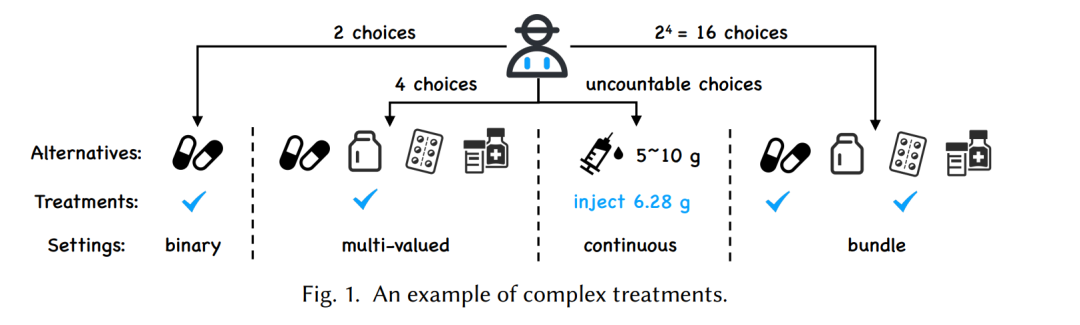
以往的研究主要集中在二元处理的设置,即只有一个处理要么采用要么不采用。然而,在实际应用中,处理可能是多值的、组合的、连续的,甚至更复杂的。我们以药物决策为例进行说明。如图1所示,如果处理是单个变量,患者可以决定是否服用某种药物(二元),从多个替代方案中选择一种(多值),甚至考虑注射剂量(连续)。另一方面,处理也可以包含多个变量,患者需要考虑多种药物的组合(组合)。
因此,复杂处理下的因果推断在近年来引起了越来越多的关注。广义倾向评分(GPS)是倾向评分的扩展,基于GPS的方法被提出用于估计多值处理和连续处理的因果效应。同样,基于表示的方法在复杂处理的设置下也起着重要作用。例如,CFR扩展到多值处理情况下的MEMENTO和组合处理情况下的后悔最小化网络(RMNet)。剂量反应网络(DRNet)和变系数网络(VCNet)也是连续处理下基于表示方法的良好例子。对于使用GAN的生成建模方法,只要将判别器的任务改为多类分类,GANITE自然可以应用于多值处理的效应估计。SCIGAN是在连续设置下的进一步探索。研究人员还利用VAE,开发了任务嵌入因果效应VAE(TECE-VAE)和变分样本重新加权(VSR)用于组合处理,以及用于连续处理的可识别处理条件VAE(Intact-VAE)。除了这三种主流方法,MetaITE为多值处理提供了另一种解决方案。具体来说,它将有足够样本的处理组视为源域,从而训练元学习者。另一方面,样本有限的组被视为目标域进行模型更新。
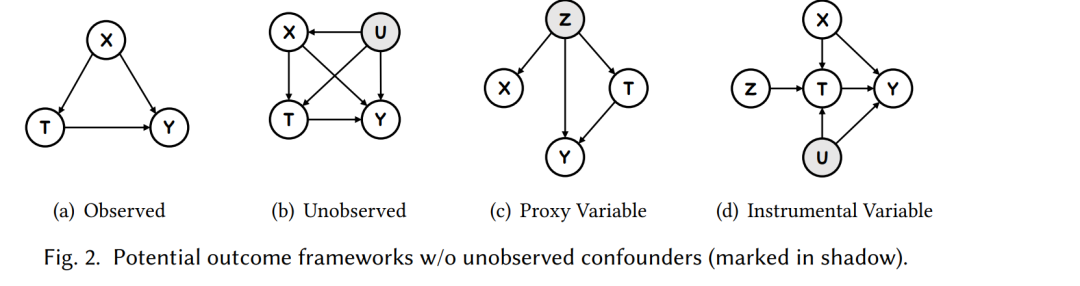
由于信息收集的限制,可能存在未观测到的混杂因素。如图2(b)所示,阴影中的未观测到的混杂因素U意味着它不能被测量或未出现在数据集中。它也被称为混杂因素,因为它同时影响处理T和结果Y。注意,U可能与可观测的混杂因素X存在因果关系。解决这个问题的一种方法是找到代理变量作为未测量混杂因素的替代。如图2(c)所示,Z被恢复为未测量混杂因素的代理,影响X和T。要求是X在给定Z的情况下独立于T。许多研究致力于找到这样的代理变量,如用于多值处理的信息多重因果估计(MCEI),用于组合处理的去混杂器,以及用于连续处理的深度特征代理变量(DFPV)。此外,工具变量(IV)也广泛用于这种情况,如图2(d)所示。给定X,工具变量Z有助于识别T→Y。DeepIV和使用再生核希尔伯特空间(RKHS)的IV是这种工具变量方法的两个实例。
因果推断领域有几篇综述,例如,两个聚焦于二元处理的综述,总结工具变量方法的工作,以及讨论多值处理匹配方法的综述。然而,估计复杂处理因果效应的问题很少被讨论,而这在实际应用中是常见且重要的。本文我们在潜在结果框架下对复杂处理的方法进行了全面回顾。我们澄清了多值、连续和组合处理设置的问题设置,并区分了它们之间的相似性和差异性。我们简要介绍了一些代表性方法,以及常用的实验数据集和细节。我们还将讨论由不同处理设置引起的关键挑战。
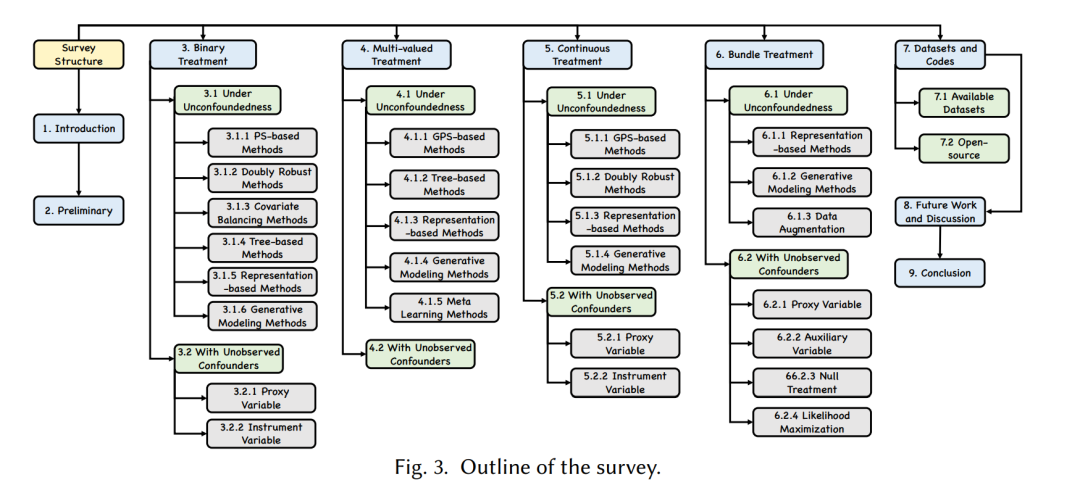
论文组织架构。本文的结构如图3所示。第2节介绍了复杂处理的因果推断的初步知识。第3节列出了二元处理的相关方法,第4节介绍了多值处理,第5节介绍了连续处理,第6节介绍了组合处理。随后,我们在第7节收集了若干可用的数据集和开源代码。第8节我们对未来工作的方向进行了进一步讨论,第9节进行了简要总结。