

约翰霍普金斯大学(JHU)与罗切斯特大学合作,致力于研究和开发分析技术,以支持一个更大的知识驱动的假设测试框架。该计划的参与者负责合作开发一个数据处理框架,该框架从原始的非结构化内容(文本、图像、带有音频的视频)开始,将这些内容转换为共享本体下的知识声明,将各信息源的结果合并为一个知识图谱,然后对该图谱进行推理,提出可以从直接观察到的内容中获得的额外信息。我们,JHU的团队,专注于这个过程的第一步。我们提出了一个框架,可以处理所有需要的输入模式,但被选择专注于多语言文本和语音(没有计算机视觉)。我们作为一个独立的团队参与了该计划的初始阶段,提供分析结果作为NIST运行的全计划评估的一部分。在第二阶段,我们提供了较少的组件,只专注于文本。在项目评估期间,我们与BBN共享这些组件。在第三阶段,我们的主要重点是在新提出的 "声称框架(claim frame) "任务下的数据注释,这锻炼了我们在众包丰富语言注释方面的背景。
我们提出了对语义分割的关注:对意义的细粒度多值化处理。由于该项目的共同目标和集中在一个单一的项目范围内的本体,我们专注于针对共同任务的新的最先进的语言分析技术,以及针对项目本体之外的方面的新的分解性资源的开发。我们团队的成果中值得注意的例子包括: 构建RAMs,这是第一个公开可用的多句子事件提取数据集;开发最先进的多语言核心推理模型,包括以固定内存量处理长文件的在线变体,以及专注于多人对话的新多语言数据集; 一个新的有监督的跨语言对齐方法,支持通过从英语到资源较少的语言的投射来自动创建训练数据;一个句子级的转述和数据增强的框架;在 "探测 "神经语言模型的新兴科学方面的合作;以及开发新的分解资源和跨越一些新语言维度的分析。
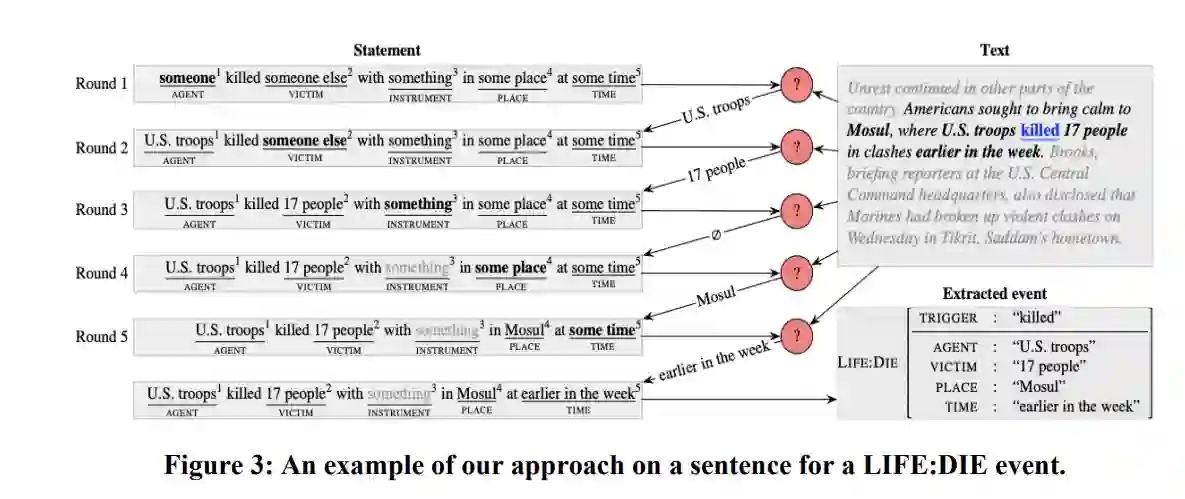
引言
在过去的十年里,语言分析的技术水平已经迅速提高。DARPA AIDA发生时,文本分析的神经模型在准确性方面正在迅速突破。这始于对之前的统计NLP管道的改进,然后分析开始被训练成 "端到端":模型不再需要部分语音标记、同步语法分析等等,以支持整体的语言理解过程。相反,模型直接在目标输出上进行训练,并假定在预训练的语言模型的参数中捕获足够的语言特征。AIDA结束时,社区开始考虑方法上的另一个进步,即通过像GPT3这样的大规模语言模型(LMs)的语境学习(提示-黑客),以及对生成性LMs的普遍关注。
JHU和合作伙伴罗切斯特大学对信息提取的神经模型的技术水平做出了贡献,同时也对探测大型语言模型的新科学做出了贡献。模型的新科学。利用我们在分解语义学的数据集创建方面的专长,开发了专门针对信息提取的新数据集。新的数据集,专门针对AIDA计划的提取问题(特别是在事件提取和核心推理方面)。我们开发了分解语义学的新资源,在项目的最后阶段,我们致力于新的倡议 了解如何对文本中的事实主张(所谓的 "主张框架")进行注释。
在项目评估方面,我们努力满足NIST及其合作伙伴不断变化的要求。我们发现,在我们所关注的部分,特别是在多语种核心参考文献的解决方面,我们经常具有竞争力,甚至优于其他执行者。由于管道要求和知识驱动的工作流程是在项目进行过程中临时制定的,所以大家都认为在不同的执行者之间进行协调是不容易的,特别是在评估前后的时间敏感的情况下。不幸的是,这导致JHU对管道的贡献往往是有限的:强大的分析组件并不总是在更大的原型框架中得到充分锻炼。与正式的评估分开,我们建立了一个独立的分析框架,并将其开源,重新发布给社区。这个 "LOME "包(大型本体多语言提取)在AIDA计划之外的相关应用中被采用,并以该计划所设想的任务需求为目标。我们在AIDA中的努力部分地导致了对其他相关项目的参与,包括DARPA KAIROS和IARPA BETTER,所有这些项目的主要重点都是增强语言技术的发展。
在下文中,我们将重点介绍我们在参与AIDA项目过程中出现的关键方法和结果。在有参考资料的地方,我们审查了提供进一步细节的科学文章。正如我们在总结中所说,我们的成果中值得注意的例子包括: 构建了RAMS,这是第一个公开可用的多句子事件提取数据集;开发了最先进的多语言核心推理模型,包括一个用固定内存处理长文档的在线变体,以及一个专注于多人对话的新的多语言数据集; 一个新的有监督的跨语言对齐方法,支持通过从英语到资源较少的语言的投射来自动创建训练数据;一个句子级的转述和数据增强的框架;在 "探测 "神经语言模型的新兴科学方面的合作;以及开发新的分解资源和跨越一些新的语言层面的分析。





