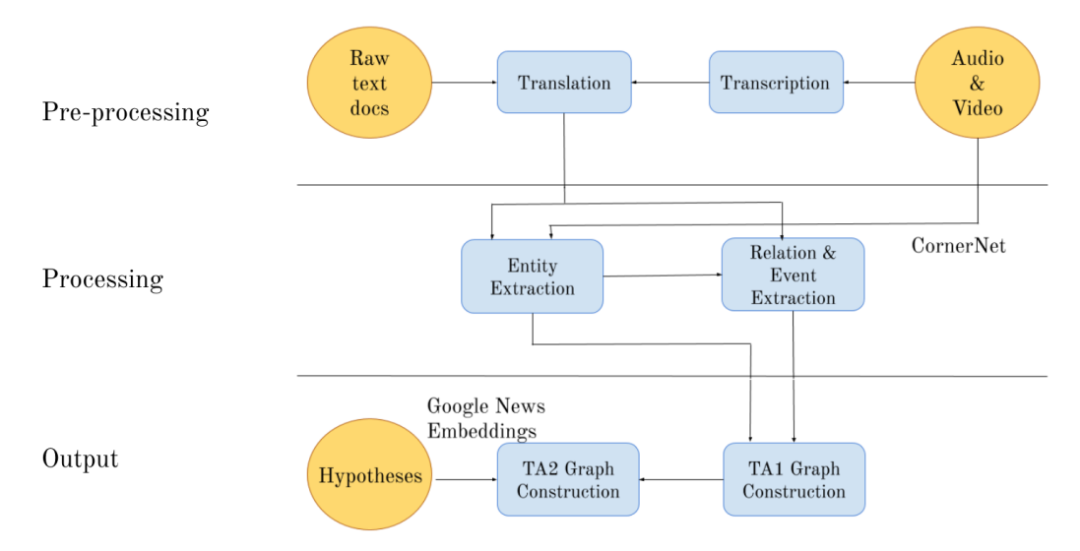
【美国DARPA资助、多模态知识图谱构建】《通过深度图生成和推理实现人类活动的多模态语义映射》美国空军研究实验室技术报告

便捷下载,请关注专知人工智能公众号(点击上方蓝色专知关注)
后台回复“MMSM” 就可以获取《【美国DARPA支持、多模态知识图谱构建】《通过深度图生成和推理实现人类活动的多模态语义映射》美国空军研究实验室技术报告》专知下载链接



登录查看更多
相关内容
Arxiv
28+阅读 · 2022年11月15日

相关VIP内容
相关资讯
相关论文
Arxiv
28+阅读 · 2022年11月15日