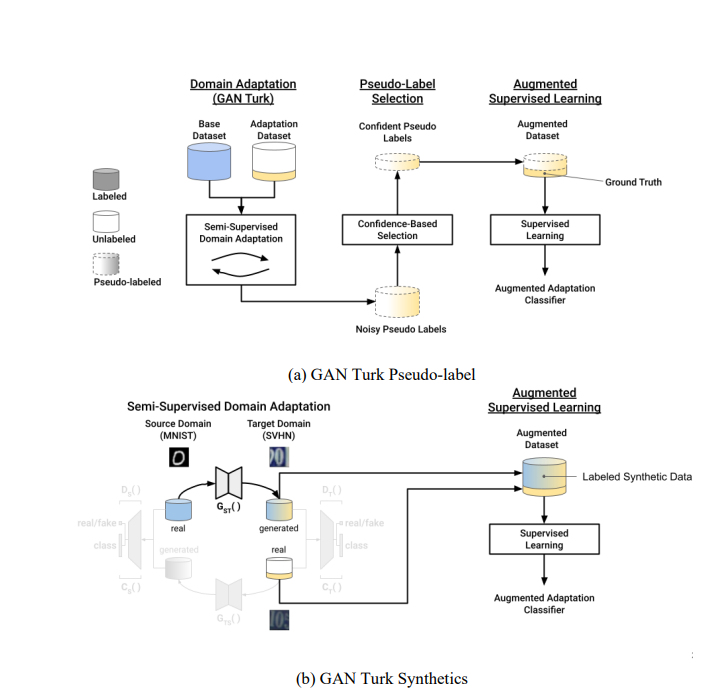
图1:GAN Turk假标签和GAN Turk合成系统图
这份最终报告记录了在DARPA的“少标签学习” (LwLL)项目过程中进行的一系列调查。专注于图像分类的领域适应和目标检测的地理空间应用。探索了生成建模技术,包括新颖的GAN Turk方法,以及主动学习,以减少图像分类的标签要求。还研究了使用GAN Turk、一致性正则化和自我训练来进行地理空间数据集的目标检测。发现:
- 使用生成模型来进行图像翻译的领域适应性对领域配对和生成对抗网络(GAN)模型训练的不稳定性很敏感
- 理想的主动学习方法很难预先选择,而且不同数据集的选择也不同
- 自我训练和一致性正则化是半监督学习的一对有希望的技术。
评估了几种用于图像分类和物体检测的生成式建模技术。评估了CycleGAN、CUT和我们自己的GAN Turk方法的两次迭代,该方法受到CycleGAN的启发。
作为第一年评估的一部分,还考虑了主动学习,并提交了一个coreset主动学习组件作为评估的一部分。coreset方法是在与基于熵的选择方法和其他抽样方法进行比较后选择的,除了其以特征距离为动机的设计外,还基于公开和内部结果。然而,内部结果和评估结果显示它不是一个可靠的方法。
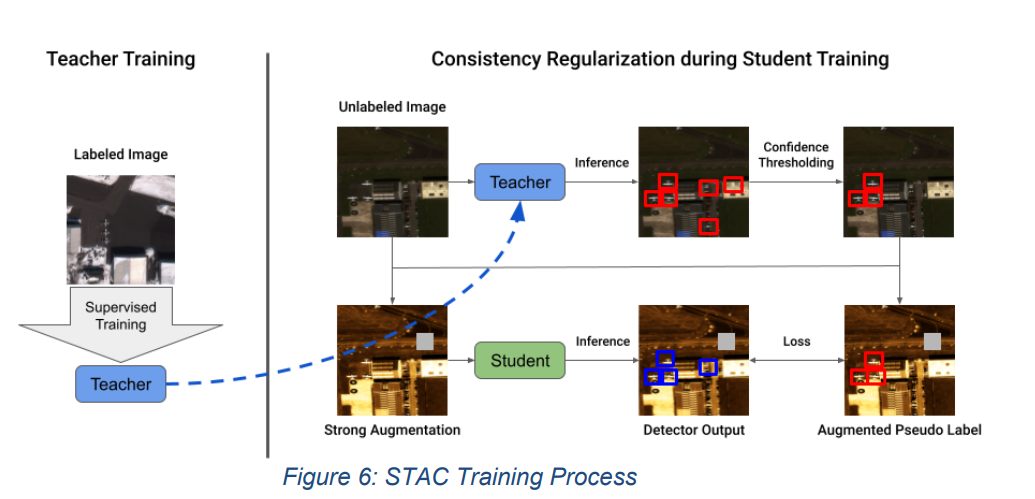
自我训练和一致性正则化的结合是在这个项目中研究的最有希望的方法。研究了STAC方法作为第三年评估的目标检测系统。内部结果显示,这两种技术的结合可以用于合成到真实领域的适应性,也可以更普遍地用于地理空间应用。此外,还表明,在地理空间数据集中,为一致性正则化而对空图像进行伪标签的做法对STAC产生了好处。在第三年的评估中,假标签空图像的显著优势未能得到测试,因为这些数据集不包含任何图像,即所有的图像至少包含一个感兴趣的目标。
作为项目要求的一部分,参加了年度独立的第三方评估,并在第3.6至3.8节中记录了这些结果。在评估过程中,主要挑战之一是计算预算。提交的GAN Turk和STAC系统需要比基线方法多得多的计算。因此,这些方法学在每个评估任务中只提交了几个检查点。
在第4节中,记录了我们的软件可交付成果,并对软件架构进行了简要概述。还提供了Docker镜像的配置,以打包系统进行评估。
总的来说,团队为政府的知识库做出了贡献,即哪些方法对少许标签的学习有希望,哪些没有。这种探索是使用合理的科学方法和精心控制的实验进行的,旨在对各种方法进行无偏见的评估。本报告总结了在整个LwLL计划中的主要发现,并强调了认为有希望的几个领域,以及根据我们在这个基础研究计划中收集到的证据,不建议追求的其他领域。