

联邦学习是一种去中心化的机器学习方法,其中客户端在本地训练模型,并共享模型更新以开发全局模型。这使得低资源设备能够协作构建高质量的模型,而无需直接访问原始训练数据。然而,尽管仅共享模型更新,联邦学习仍然面临若干隐私漏洞。其中一个主要威胁是成员推断攻击,这种攻击通过确定某个特定示例是否属于训练集来针对客户端的隐私。这些攻击可能会泄露现实应用中的敏感信息,例如医疗系统中的医疗诊断。尽管关于成员推断攻击已有大量研究,但针对联邦学习中的此类攻击的全面和最新综述仍然缺失。为了填补这一空白,我们根据这些攻击在联邦学习中的特点,对成员推断攻击及其相应的防御策略进行了分类和总结。我们介绍了现有攻击研究的独特分类法,并系统地概述了各种反制措施。在这些研究中,我们详细分析了不同方法的优缺点。最后,我们识别并讨论了未来研究的关键方向,以便为有意推动该领域发展的读者提供参考。
1 引言
随着大量数据集的广泛可用,机器学习(ML)已成为一项关键技术,推动了多个领域的显著进展,包括计算机视觉[1-5]、自然语言处理[6-9]等。特别是像《通用数据保护条例》(GDPR)[10]和《加利福尼亚消费者隐私法》(CCPA)[11]等法律法规,建立了组织之间共享数据的关键指南,并规定了在使用这些数据时必须保护用户隐私。联邦学习(FL),如[12]所提,是一种分布式机器学习范式,使多个客户端能够在不直接共享私有数据的情况下协作训练机器学习模型(全局模型)。这种方法提供了一种实际的解决方案,可以克服隐私限制。与依赖数据聚合的集中式机器学习不同,FL 允许训练样本在不同的组织或移动设备上保持本地。该方法不仅增强了可用训练数据的量,还支持大规模训练过程。同时,通过将模型训练与直接访问原始数据解耦,FL 使每个客户端能够将其训练数据保留在本地,从而确保遵守现行的法律法规,并有助于保护数据隐私。 尽管FL通过防止直接访问原始训练数据来设计为隐私意识型,但它仍然面临显著的隐私风险。研究人员已证明,攻击者可以利用FL中的模型更新重建原始训练数据和标签[13-15]、推断其他客户端的训练数据属性[16, 17],甚至生成代表性样本[18-20]。在这些隐私风险中,成员推断攻击(MIA)代表了一种根本性的隐私侵犯,试图确定某个特定记录是否属于训练数据集[21-24]。MIA的关键应用包括:1)隐私泄露:MIA可以揭示潜在攻击者关于机器学习模型训练数据的敏感细节。例如,如果攻击者确定某个医疗记录被用于训练癌症预测模型,他们可能会推断出该个体患有癌症。2)数据审查:MIA作为一种有效的工具,用于审计数据隐私和合规性。例如,在“被遗忘权”的法律要求下,MIA可用于验证平台在删除请求后是否成功删除特定数据点。3)高级攻击的基础:MIA可以作为加强更复杂隐私攻击的基础步骤。攻击者可以通过确定哪些样本被用作训练数据,进一步完善他们的策略来探索目标模型,例如模型提取攻击[25]。大量研究致力于专门针对FL环境设计的MIA。举例来说,研究[26]首次提出了一种推断算法,通过利用梯度、隐藏层输出和样本损失,在学习过程中推断成员信息。此后,研究界尝试将其扩展到不同领域,如分类模型[27-30]、回归模型[31]和推荐系统[32],通过利用交换的模型更新[26, 33, 34]或模型输出的趋势[29, 30, 35, 36]。
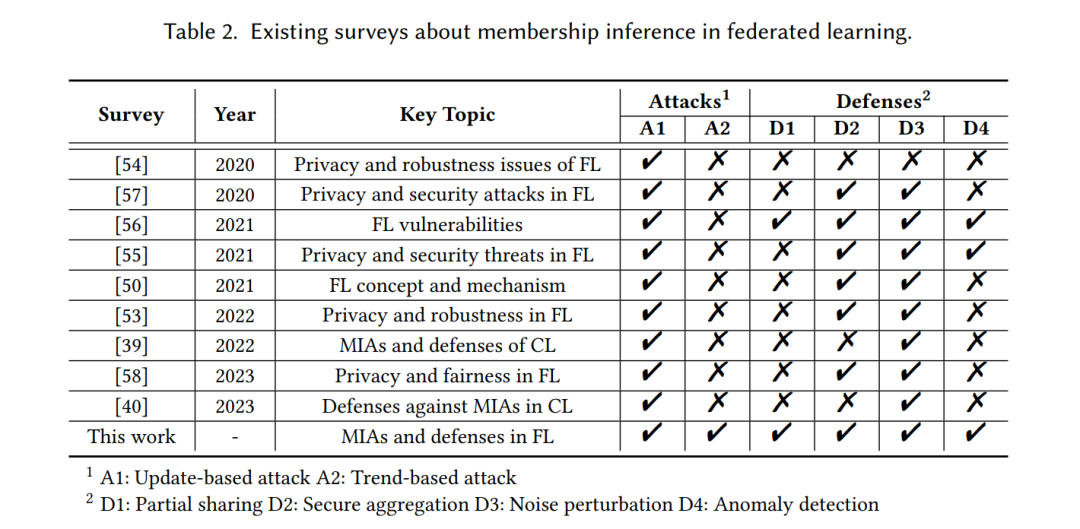
尽管相关研究探讨了集中式和联邦式设置中的MIA及防御,但这些方法之间存在显著差异,如表1所示。这些差异促使我们专门聚焦于联邦学习框架下的研究。考虑到集中式学习(CL)设置,其中训练数据集中在单一服务器上[37, 38],机器学习模型使用聚合数据集进行训练,然后发布到公众。在CL和FL设置中,MIA及防御机制的差异如下:
- 攻击者/防御者角色:两种设置中,攻击者和防御者的角色有所不同。在CL中,大多数MIA通常由模型消费者执行,他们主要访问模型输出[39]。然而,在FL中,潜在的攻击者主要来自内部,包括中央服务器和其他客户端。在CL相关MIA的防御中,隐私保护的责任通常由模型所有者承担[40]。然而,在FL中,中央服务器和客户端都可以实施防御策略,以防止成员信息泄露[41, 42]。
- 攻击/防御阶段:攻击者发起攻击的阶段或防御算法应用的时机有所不同。在CL中,大多数MIA发生在推理阶段,即目标模型发布后。而在FL中,MIA则集中在训练阶段,试图在整个收敛过程中妥协成员隐私。在防御方面,集中式和联邦式设置都旨在保护训练阶段的数据隐私,但关键的区别在于,集中式防御还注重在推理阶段保护模型输出。
- 攻击者知识:FL中的攻击者相比于CL中的攻击者能够获得更详细的对抗性知识。在CL中,MIA可以发生在两种设置中:白盒设置,其中攻击者可以访问目标模型及其中间层计算,或黑盒设置,仅能访问模型输出,如预测分数[22, 43, 44]或标签[45, 46]。相比之下,FL中的攻击者在整个学习过程中可以广泛访问目标模型的梯度、中间计算和最终输出[26]。此外,FL攻击者可以密切观察模型的收敛过程,使他们能够访问目标模型的多个历史版本。
- 主动策略:FL中攻击者用于推断成员隐私的主动方法与CL中有所不同。在FL中,攻击者拥有对训练过程的合法访问权限,可以恶意操控模型,从而通过模型污染执行强大的MIA[26, 47]。相比之下,CL攻击者可能会通过污染数据来放大成员信息泄漏[48, 49]。
- 保护核心:由于面临泄漏的私人信息种类不同,因此两种设置中的防御机制的目标也有所不同。在CL中,防御旨在使模型输出在成员和非成员样本之间不可区分。相比之下,FL的对策侧重于保护模型更新免受中央服务器或窃听者的隐私侵犯,同时还保护模型免受好奇客户端的潜在泄漏。
然而,现有的关于FL相关MIA的综述提供的仅是初步讨论和不完整的介绍[39, 50-58],缺乏全面和系统的回顾。例如,早期的研究[50, 52, 55, 56, 58]简要概述了FL中的隐私和安全问题,而[53, 54]则强调了FL过程中的推断和污染攻击。这些综述仅提及了少数早期研究[17, 26],而遗漏了更近期的研究[33, 59]。此外,最相关的文章[39]提供了集中式学习设置中MIA的综合总结,但对FL相关的工作提供的仅是有限的总结[17, 26, 27, 29, 60, 61]。
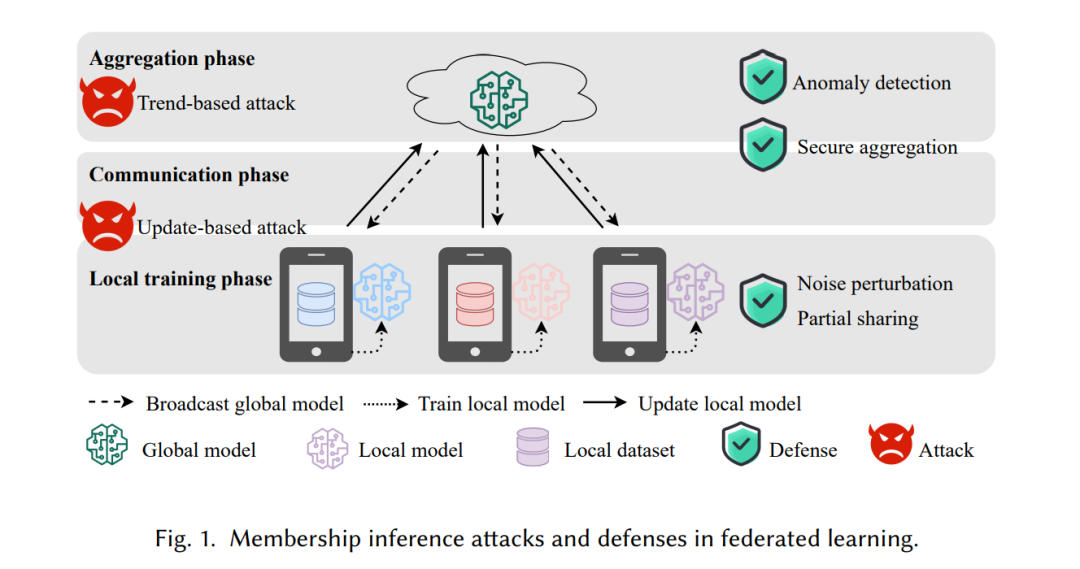
本文提供了对FL过程中MIA及防御策略的全面综述,如图1所示。我们首先提出了一个独特的分类法,广泛回顾了FL中基于模型更新和收敛趋势的现有MIA研究。在FL背景下的MIA防御方面,我们回顾了四种常用的缓解策略,包括部分共享[62, 63]、安全聚合[64]、噪声扰动[65, 66]和异常检测[67]。最后,我们还指出了关于MIA和防御的未来研究方向。本文的贡献可以总结如下:
- 我们通过总结文献中大部分的研究,提出了FL设置下MIA的全面回顾。据我们所知,本文是首个关于FL领域MIA及防御的综述。
- 我们识别了FL背景下的MIA方法,并提供了基于更新和趋势的视角来指导本综述。基于我们的分析,我们提出了一个独特的分类法,总结现有的MIA研究,并讨论了其与集中式学习相关MIA的差异。
- 我们将现有的FL对策分类为四种方法,并分析其优缺点。此外,我们还从关键视角对集中式学习中的防御进行比较。
- 我们展望了MIA和防御领域的前沿研究方向。
本文其余部分的组织结构如下:第二节首先提供了初步背景,并简要回顾了集中式学习相关的MIA及其缓解策略。接着,第三节探讨了FL中的各种威胁模型。第四节介绍并总结了现有的FL中的MIA研究。第五节描述了现有的反制措施。第六节强调了潜在的研究方向,第七节则给出最后的结论。
