对抗性攻击通过操纵输入数据来削弱模型的可用性和完整性,构成了机器学习推理过程中的重大安全威胁。随着大型视觉-语言模型(LVLMs)的出现,新的攻击向量如认知偏差、提示注入、和越狱技术也逐渐浮现。理解这些攻击对于开发更强健的系统和揭示神经网络的内部机制至关重要。然而,现有的综述通常侧重于攻击分类,缺乏全面深入的分析。当前研究界亟需:1)对对抗性、可迁移性和泛化性的一致洞见;2)对现有方法的详细评估;3)基于动机驱动的攻击分类;以及4)整合传统和LVLM攻击的整体视角。本文通过提供对传统和LVLM对抗性攻击的全面总结,强调它们的联系和区别,填补了这些空白,并为未来的研究提供了可操作的见解。
视觉对抗攻击、普通视觉模型、大型视觉语言模型
1 引言
对抗性攻击通过精确操控输入数据来恶意破坏模型的可用性和完整性,在机器学习推理过程中构成了重大安全威胁。这些攻击影响了诸如人脸识别 [144, 258, 350]、行人检测 [278]、自动驾驶 [43, 80, 267] 以及自动结账系统 [177] 等关键应用,严重威胁系统的安全性。为了提升鲁棒性并保护这些应用,研究人员进行了大量的深入研究,例如 NIPS 2017 [215] 和 GeekPwn CAAD 2018 [94] 等竞赛所展示的成果。全面理解对抗性攻击的演变对于开发更有效的防御措施至关重要,尤其是在大型语言模型(LLMs)的背景下。然而,传统的综述往往未能捕捉到最新进展 [9, 10, 334],而近期的调查则多集中于特定领域 [17, 136, 178, 294, 306] 或缺乏全面总结 [59]。本文在多个关键方面与现有综述区分开来:
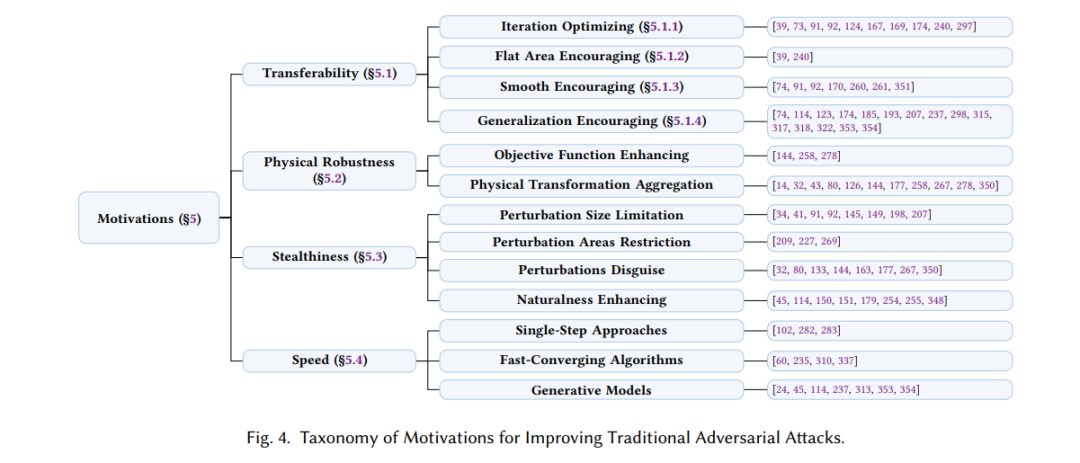
- 关键概念提取 (§2)。对抗性、可迁移性和泛化性是对抗样本(AEs)的重要特性,指导了设计目标和动机。本文填补了先前工作的空白,概述了对抗性和可迁移性的成因 (§2.1.1 和 §2.2.1)、对抗样本的作用 (§2.1.2)、可迁移性的特性 (§2.2.2) 以及不同类型的泛化 (§2.3),这些内容往往在现有文献中被忽视。
- 动机驱动的分类重点 (§4 和 §5)。动机驱动目标的实现,且目标因攻击者的知识水平和上下文而异。如图 3 所示,我们首先基于知识水平在第 2 阶段分类攻击方法,然后在每个知识背景下总结设计动机。与主要按知识水平分类攻击的前人工作不同,我们对其背后的动机进行了更深入的分析。
- 连接传统攻击与 LVLM 攻击 (§7)。正如 [238] 所指出的,对抗性攻击正从传统的分类聚焦方式向更广泛的 LLM 应用发展。基于此,我们重点强调传统和 LVLM 对抗性攻击之间的联系和区别,集中于两个主要点 (§7.4):1)LVLM 对抗性攻击是传统攻击的扩展,具有相似的模式;2)LVLM 攻击目标更广泛,应用更多样,具有不同的目标和方向。
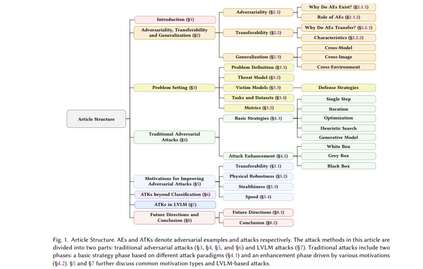
本文提供了对对抗性攻击发展的全面概述,核心贡献(见图 1)包括:
- 总结对抗样本的关键特性,包括对抗性和可迁移性的成因、对抗样本的作用、可迁移性的特征及不同类型的泛化 (§2)。
- 对威胁模型、受害模型、相关数据集和评估方法的全面概述 (§3)。
- 将攻击方法分为两个阶段:基础策略和增强技术 (§4),并根据动机进一步分类攻击增强阶段 (§5)。
- 讨论非分类对抗性攻击和 LVLM 攻击的兴起 (§6)。
- 识别 LVLM 中的新兴攻击模式和潜在漏洞 (§7.1.2)。
- 阐述 LVLM 背景下的受害模型、相关数据集和评估方法 (§7.3)。
- 基于知识水平、目标和技术对 LVLM 攻击方法进行分类 (§7.4)。
- 研究针对 LVLM 对抗性攻击的防御策略 (§7.5)。
传统对抗性攻击
我们将传统对抗性攻击分为两个阶段:基础策略(阶段 1)和攻击增强(阶段 2)。在基础策略阶段,研究人员从其他领域中探索并适配通用的解决方案用于对抗性攻击,从而建立了基础框架。此阶段的方法通常为未来的策略提供了基础。在攻击增强阶段,攻击方法的设计通常基于特定的动机。例如,这些方法旨在在有限或无法访问受害模型的情况下生成对抗样本(AEs),或改善对抗样本的隐蔽性、物理鲁棒性和生成速度。
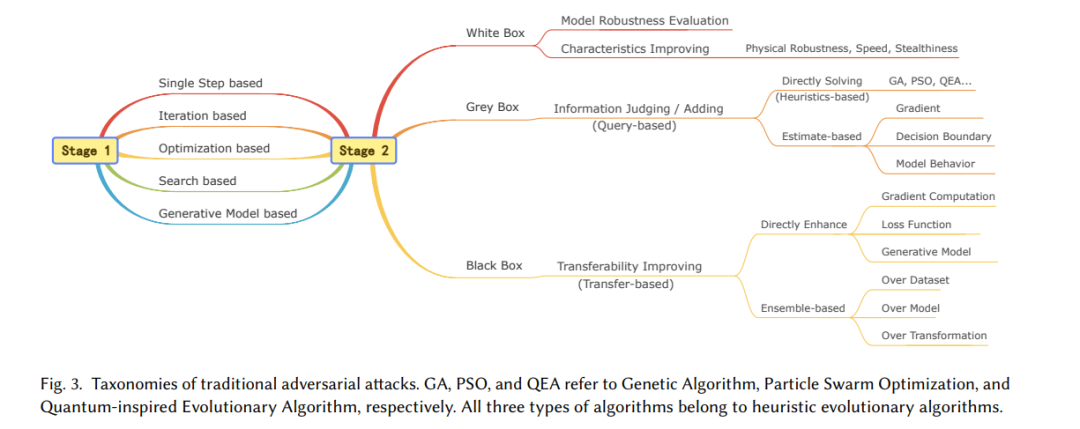
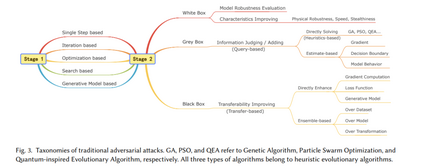
** 阶段 1:基础策略**
如图 3 所示,此阶段的攻击方法可以分为五种类型。单步和迭代方法通常通过在原始样本上添加不同于真实预测的梯度来生成对抗样本。基于优化的方法将扰动生成视为优化问题,而基于搜索和生成模型的方法则使用搜索算法或依赖生成器生成对抗样本。
- 单步方法 [102, 282, 283],如 FGSM [102],依赖于线性假设 [102],通过一次性扰动生成对抗样本。该方法速度快 [317, 351],相较于迭代方法具有更好的可迁移性 [148],但其扰动较大 [226] 且攻击成功率(ASR)有限 [148, 351]。
- 迭代方法 [149, 198, 208] 能生成更精细的扰动,有效减少扰动大小并提高 ASR [148, 351]。然而,与单步方法相比,其可迁移性和物理鲁棒性较差 [73, 74, 124, 148, 240, 351],因为精细扰动更易被破坏 [149]。
- 基于优化的方法 [27, 34, 274] 将扰动的框约束 [34] 转换为优化目标(如 P-范数),并可使用诸如 Adam [143] 等算法生成对抗扰动。与迭代方法相似,这些方法可以创建更隐蔽的扰动,但代价是可迁移性 [74, 174] 和生成速度 [167, 208, 237, 317] 的降低。
- 基于搜索的方法 可分为启发式和定制搜索方法。启发式搜索方法 [213, 258, 269, 284] 仅依赖评估信息(如置信分数)生成对抗样本,通常通过查询受害模型获得,属于灰盒方法。定制搜索方法通过识别决策边界 [29] 和易受攻击的像素位置 [209, 227] 辅助攻击。这些方法可能仅修改少量像素 [209, 227, 269] 或区域 [258],以增强隐蔽性。然而,高查询 [29, 209, 269, 284] 或计算量 [227] 限制了其实际应用。
- 生成模型生成对抗样本 [24, 45, 114, 237, 313, 353, 354] 有两大优势:1)生成速度快;2)样本自然性高。常用生成器(如自编码器 [24, 237] 和 GAN [313, 353, 354])可以在单次前向过程中生成扰动,大大提升了生成速度。尽管扩散模型需要迭代去噪,但其速度仍然较快 [45, 114]。此方法通常避免使用框约束来限制扰动大小,而是旨在创建感知上不可见的对抗样本(无限制对抗样本,UAEs [45]),从新的视角重新定义对抗样本的隐蔽性。
阶段 2:攻击增强
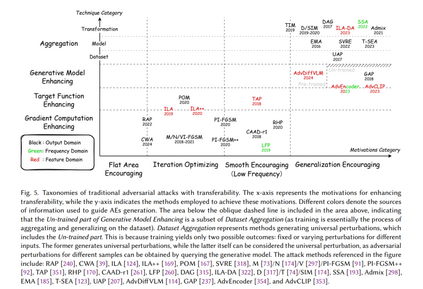
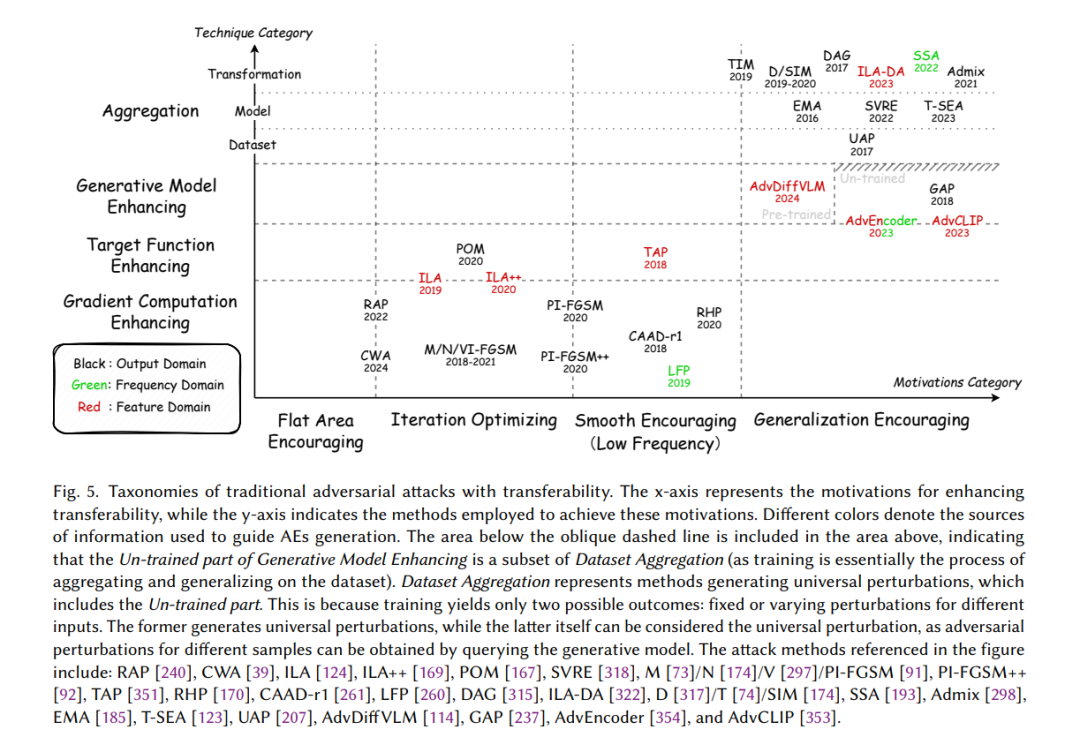
如图 3 所示,此阶段的攻击可根据攻击者的知识水平分为三类。此外,阶段 1 中的方法也可能在此阶段重新出现,作为从不同角度审视的开创性工作。 白盒 在白盒场景中,生成对抗样本主要有两个目的:1)评估模型的鲁棒性;2)增强样本的特定属性,如物理鲁棒性、生成速度和隐蔽性。正如 Carlini 和 Wagner [34] 所指出的,只有足够强的对抗样本才能准确测量模型行为的真实下限,从而代表攻击下的鲁棒性上限。因此,旨在鲁棒性评估的白盒攻击方法关注增强对抗性。例如,FAB [60] 通过迭代线性化分类器并投影生成接近决策边界的攻击样本。CW [34] 和 PGD [198] 分别采用优化和迭代方法实施有效攻击。基于 PGD,APGD [61] 通过动态调整步长改进了迭代过程,而 MT [106] 通过在输出域中最大化变化增强了起始点的多样性。此外,AA [61] 和 CAA [200] 通过聚合多次攻击增强评估能力,而 A3 [186] 通过自适应调整起始点和自动选择攻击图像动态优化攻击过程。 除了对抗性,增强对抗样本在物理鲁棒性、隐蔽性和生成速度方面的性能也至关重要。此主题将在 §5 中讨论。尽管这些能力的改进对黑盒和灰盒场景也有意义,但这里的重点是白盒研究,因为它的研究最为广泛。 灰盒 在灰盒场景中,攻击者可以通过查询获得有限的信息,如预测标签 [29, 128, 209, 225, 226]、标签排序 [128] 和置信分数 [41, 128, 209, 213, 258, 269, 284]。这种限制自然产生了两种攻击策略:1)使用可用信息直接生成攻击样本;2)基于提供的有限数据估计额外信息,如梯度 [41, 128, 209]、决策边界 [29] 和模型行为 [225, 226]。 直接生成方法通常利用启发式搜索算法,因为它们只需使用来自受害模型的与适应度相关的信息评估个体质量。样本更新通过使用适应度指标保留最佳个体的特定策略引导,最终迭代生成有效的攻击样本。EA-CPPN [213] 和 OPA [269] 使用遗传算法(GAs)生成对抗样本,而 RSA-FR [258] 和 AE-QTS [284] 分别采用粒子群和量子启发算法实施攻击。 在基于估计的方法中,估计的目标可能包括梯度、决策边界和模型行为。ZOO [41] 使用对称差商对像素级梯度进行估计,然后执行 CW 攻击。NES [128] 通过高斯基的有限差分在当前迭代中估计梯度,用于更新扰动并配合 PGD。与 ZOO 和 NES 不同,LSA [209] 通过局部贪婪搜索隐式估计相对于真实标签的像素位置的梯度显著性图 [265],通过定位对标签预测最敏感的区域有效减少了扰动大小。BA [29] 使用拒绝采样允许扰动样本随机接近决策边界,间接估计受害模型的决策边界。JDA [226] 和 JDA+ [225] 通过查询受害模型标记代理数据集,训练代理模型以模仿受害模型的行为,最终在代理模型上使用白盒方法生成对抗样本。 黑盒 在黑盒场景中,攻击者无法直接访问受害模型。因此,只能使用代理模型生成对抗样本,然后依赖这些样本的可迁移性攻击目标模型。关于提升可迁移性的方法详见 §5.1,如图 5 所示。
LVLM 中的对抗性攻击
在过去的十年中,对抗性攻击在各种算法 (§4)、动机 (§5) 和应用 (§6) 上不断演变。最近,多模态大型模型,尤其是从大型语言模型(LLMs)发展而来的大型视觉-语言模型(LVLMs),成为新的研究焦点,其可用性和完整性引发了担忧。正如图 6 所示,本章从五个角度全面概述了 LVLM 的对抗性攻击。在 §7.1 中,我们首先讨论 LVLM 在传统对抗性攻击及特定攻击下的表现,接着探讨它们为什么依然易受攻击。§7.2 定义了关键术语和符号。§7.3 提供了评估框架,包括受害模型、数据集和评估指标。§7.4 按目的、攻击者知识和技术分类了攻击方法,§7.5 简要介绍了防御策略。

结论
本文回顾了过去十年视觉对抗攻击的发展。正如Qi等人指出的那样,对抗攻击正从以分类为中心的方法转向在大语言模型(LLM)中的更广泛应用。因此,文章分为两个部分:1)传统对抗攻击,2)大语言模型对抗攻击。 第一部分总结了对抗性、可转移性和泛化,解释了对抗性和可转移性的原因、对抗样本(AE)的角色、可转移性的特征以及泛化的类型。接着定义了问题并介绍了威胁模型、受害者模型、数据集和评估指标,将传统攻击分为两个阶段:基本策略,探索各种攻击范式;攻击增强,旨在提升攻击的有效性。第二阶段的动机可分为四种类型:提高可转移性、物理鲁棒性、隐蔽性和生成速度。该部分最后概述了攻击在不同任务中的应用。 第二部分强调了大语言模型对传统攻击的鲁棒性,同时探索新的范式。尽管拥有大规模数据集和模型容量,大语言模型仍然脆弱,我们总结了原因。我们定义了大语言模型中的对抗攻击,涵盖受害者模型、数据集和评估标准,并根据知识、目的和技术对攻击进行分类。与以往的研究不同,我们将对抗攻击、提示注入和越狱归为一个统一类别,因其具有相似的范式,但按目的加以区分。常见技术包括提示修改、对抗扰动、条件信息生成(CIG)和排版。该部分以防御措施的讨论结束。 最后,文章探讨了未来的研究方向,包括对抗性、可转移性、物理鲁棒性、隐蔽性、生成速度和应用,旨在为视觉对抗攻击的未来研究提供见解。