第一篇从模态角度全面综述AIGC方法的综述论文,不可错过!
来自新加坡科技设计大学《各种模态数据AIGC》综述论文
AI生成的内容(AIGC)方法旨在使用AI算法产生文本、图像、视频、3D资产和其他媒体。由于其广泛的应用范围和最近的工作展示的潜力,AIGC的发展最近受到了很多关注,AIGC方法已经为各种数据模态(如图像、视频、文本、3D形状(体素、点云、网格和神经隐式场)、3D场景、3D人类头像(身体和头部)、3D运动和音频)开发——每种都呈现不同的特征和挑战。
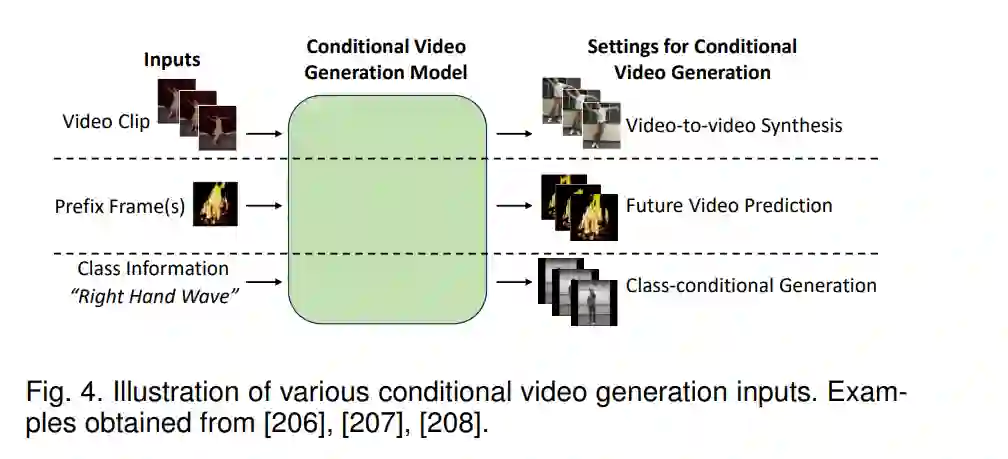
此外,跨模态AIGC方法也有很多重大的发展,其中生成方法可以在一种模态中接收条件输入,并在另一种模态中产生输出。示例包括从各种模态到图像、视频、3D形状、3D场景、3D头像(身体和头部)、3D运动(骨骼和头像)和音频模态。
在这篇文章中,我们提供了一个全面的AIGC方法评价,包括单模态和跨模态方法,强调了每种设置中的各种挑战、代表性的工作和最近的技术方向。我们还提供了在不同模态的几个基准数据集上的比较结果。此外,我们还讨论了挑战和潜在的未来研究方向。

在人工智能(AI)的迅速发展中,内容生成技术的发展是该领域中最吸引人、讨论最广泛的话题之一。AI生成的内容(AIGC)包括通过AI算法产生文本、图像、视频、3D资产和其他媒体,从而实现内容创建过程的自动化。AIGC促进的这种自动化显著减少了对人力的需求,降低了内容创建的成本,从根本上重塑了诸如广告[1]、[2]、[3]、教育[4]、[5]、[6]、代码开发[7]、[8]、[9]和娱乐[10]、[11]、[12]等行业。
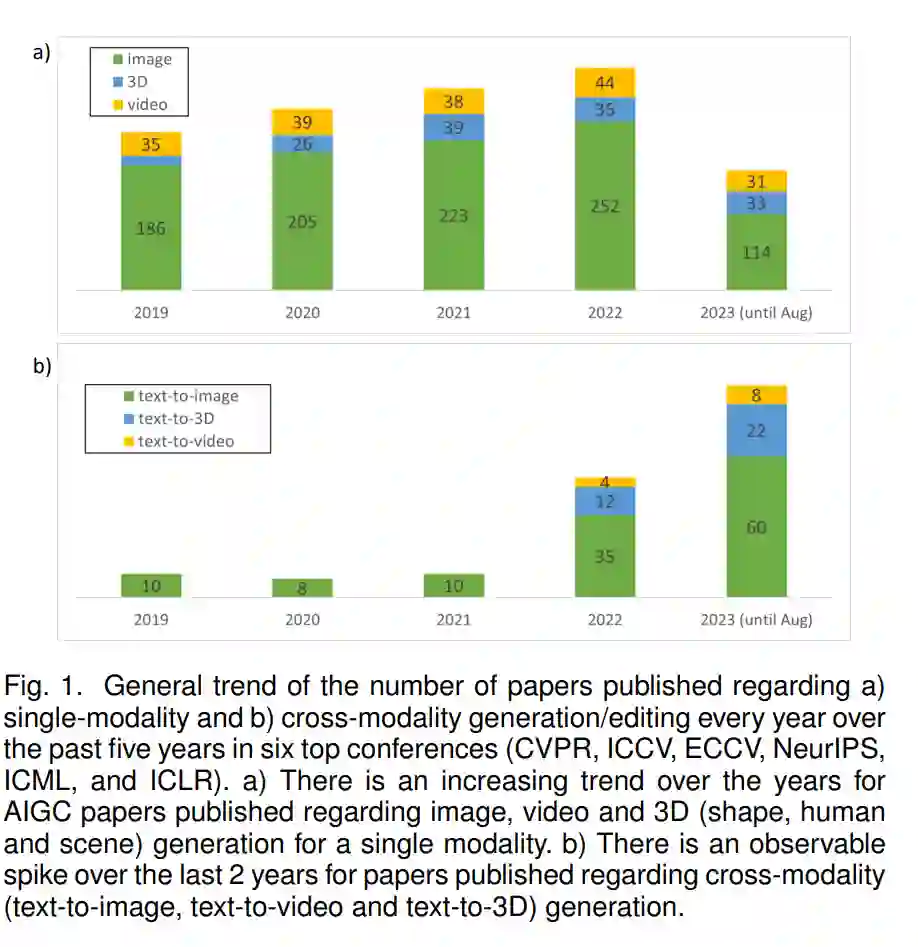
在AIGC的早期,发展和方法主要涉及单一模态,其中生成模型的输入(如果有)和输出都共享相同的模态。Goodfellow等人的开创性工作[13]首次介绍了生成对抗网络(GANs),它原则上能够训练深度神经网络生成难以区分训练数据集中的图像的图像。深度神经网络的生成能力的这种展示导致了图像[13]、[14]、[15]的单模态生成的广泛发展,以及其他各种模态,如视频[16]、[17]、文本[18]、[19]、[20]、3D形状(如体素[21]、[22]、点云[23]、[24]、网格[25]、[26]和神经隐式场[27]、[28])、3D场景[29]、[30]、3D头像(全身[31]、[32]和头部[33]、[34])、3D运动[35]、[36]、音频[37]、[38]等。此外,这些发展多年来一直持续不断,每年在该领域发表的工作数量一直在稳步增加,如图1(a)所示。尽管每种模态的生成模型共享一些相似的方法和原则,但它们也遇到了独特的挑战。因此,每种模态的生成模型的方法和设计专门用于解决这些不同的挑战。
最近,涉及多种模态的人工智能生成技术(AIGC)也得到了快速发展,其中输入和输出的模态是不同的。这种跨模态的组合使用户在生成输出方面拥有更大的控制权,例如,通过输入文本描述生成所需的图像,或者通过RGB图像或视频生成个性化的3D人类化身。然而,这种跨模态的方法通常更具挑战性,因为不同模态之间的表示可能存在很大差距。此外,它们通常需要更大的数据集,其中包括来自多种模态的配对数据,以便有效捕捉它们之间的多样关系。值得注意的是,最近的作品,例如Stable Diffusion [39],MakeA-Video [40]和DreamFusion [41]进一步展示了AIGC在接收文本提示方面的卓越能力,并以各种模态交付出色的输出,可与人类工艺相媲美,这在该领域激发了大量的研究工作,如图1(b)所示。这些最近的进展展示了AIGC在各种模态中的潜力,同时也为跨模态内容生成开辟了新的令人兴奋的途径。
因此,鉴于不同模态下生成模型的多样性以及跨模态生成在最近的进展中的重要意义,我们从这个角度审视现有的AIGC方法。具体而言,我们全面调研了在广泛的模态范围内的单模态方法,同时还审查了为未来工作奠定基础的最新跨模态方法。我们讨论了每种模态和设置中面临的挑战,以及代表性的作品和最近的技术方向。主要贡献总结如下: • 据我们所知,这是第一篇从模态角度全面综述AIGC方法的综述论文,其中包括图像、视频、文本、3D形状(作为体素、点云、网格和神经隐式场)、3D场景、3D化身(完整人体和头部)、3D运动和音频模态。由于我们关注模态,我们进一步根据输入条件信息对每种模态中的设置进行分类。 • 我们全面调研了跨模态AIGC方法,包括跨模态图像、视频、3D形状、3D场景、3D化身(全身和头部)、3D运动(骨架和化身)以及音频生成。 • 我们重点调研了最近和先进的AIGC方法,以向读者提供最先进的方法。
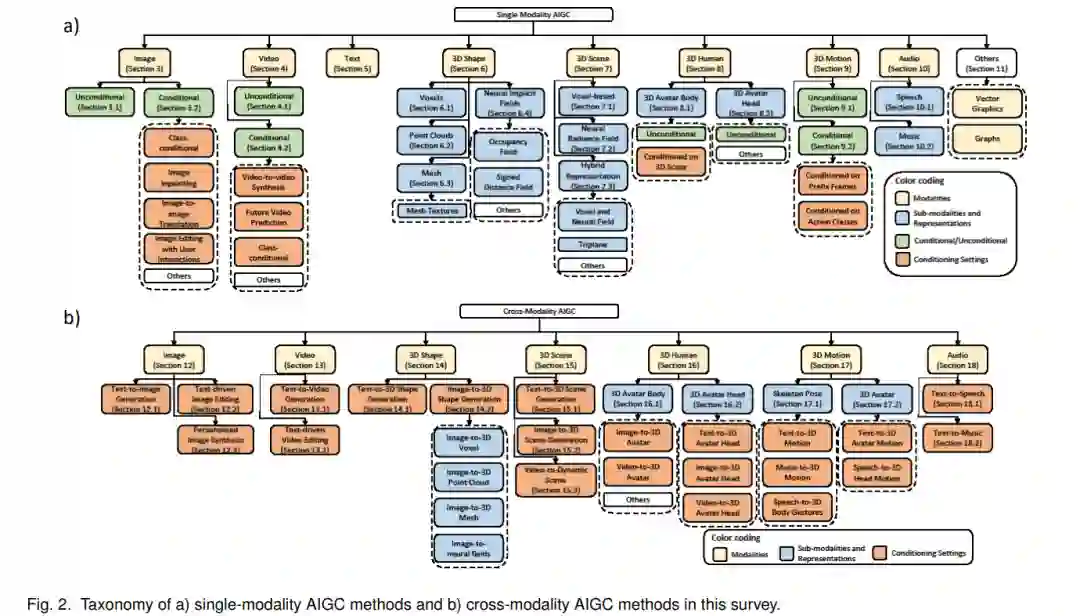
本文的组织结构如下。首先,将本文综述与现有工作进行比较。通过分别介绍每个模态,介绍涉及单一模态的生成模型。由于关注的是模态,因此进一步对每个模态中的方法进行分类,根据它们是无条件方法(对于要生成的图像没有提供约束)还是根据所需的条件信息类型。这些单模态方法的分类见图2(A)。然后,介绍了跨模态AIGC方法,这些方法的分类见图2(b)。最后,我们将讨论现有AIGC方法的挑战和可能的未来的发展方向。
图像模态生成
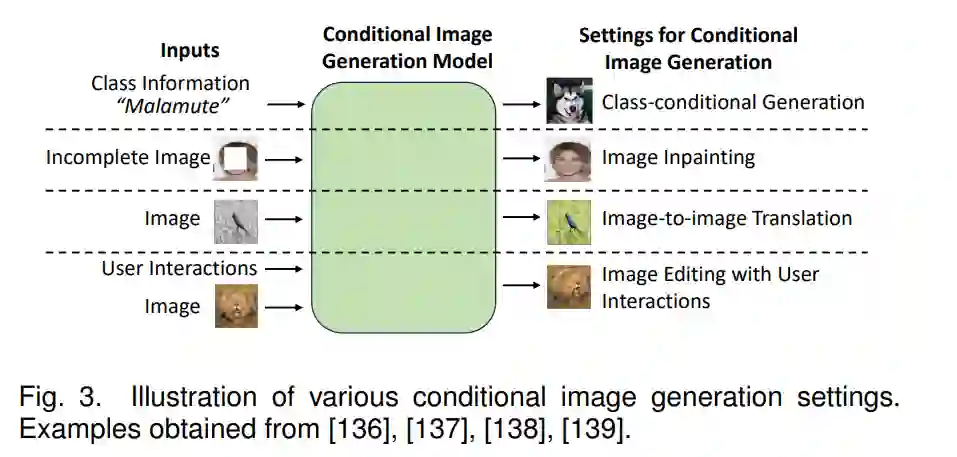
图像模态是最早进行深度生成建模发展的模态,并经常成为许多基础技术的测试平台,如生成对抗网络(GANs)、变分自编码器(VAEs)、归一化流(NFs)和去噪扩散模型(DMs)。这是由于几个原因,包括图像数据的现成可用性,与其他模态(如视频或3D数据)相比,图像的相对简单性,以及使用卷积神经网络(CNNs)对网格状RGB数据进行建模的易用性和效率。使用深度学习进行图像生成的最初尝试面临着无数的困难。例如,许多方法面临着训练不稳定性,这在具有模式崩溃风险的GAN中尤为明显。此外,建模长程依赖性和有效地扩大图像分辨率带来了重大困难。此外,生成多样化的图像也具有挑战性。然而,多年来取得的进展大多克服了这些问题,使得训练图像生成模型来生成多样化和高质量的图像变得相对容易,这些图像通常很难用肉眼与真实图像区分开来。下面,我们首先讨论无条件方法,然后讨论条件方法,其中各种约束应用于生成过程。
视频模态
随着基于图像的AIGC的发展,基于视频的AIGC也受到了许多关注,它在广告和娱乐行业中有很多应用。然而,视频生成仍然是一个非常具有挑战性的任务。除了生成单个帧/图像的困难外,生成的视频还必须在时间上保持一致,以确保帧之间的连贯性,这对于较长的视频来说可能非常具有挑战性。此外,生成逼真的运动也可能很难。此外,由于输出的尺寸要大得多,快速高效地生成视频也具有挑战性。下面我们讨论了一些克服这些挑战的方法,从无条件方法开始。
文本模态
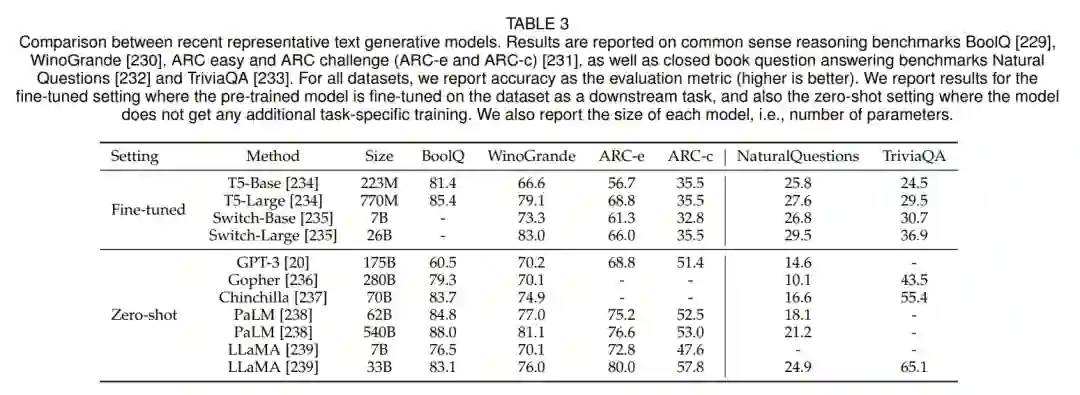
另一个受到大量关注的领域是文本生成,它通过ChatGPT等知名聊天机器人获得了更广泛的兴趣。由于几个原因,文本生成是一个具有挑战性的任务。最初的方法发现,采用GAN等生成方法来处理离散的文本表示具有挑战性,这也导致了训练稳定性的问题。在较长的文本段落中保持连贯并始终跟踪上下文也具有挑战性。此外,应用深度生成模型生成符合语法规则的文本,同时捕捉预期的语气、风格和正式程度也很难。一般来说,文本生成模型大多是在条件设置中进行训练和测试的,其中模型在受文本输入(例如输入问题、之前的文本或待翻译的文本)的条件下生成文本。因此,我们不基于条件或无条件进行分类。相反,我们根据其生成技术对方法进行分类:VAE、GAN和自回归Transformer。表3报告了一些最近的文本生成方法的性能。
3D形状生成
另一个重要且快速发展的领域是3D形状生成,其目的是生成新的3D形状和对象。快速生成3D资产的能力可能非常有用,特别是在制造业和娱乐等行业,它有助于快速原型设计和设计探索。值得注意的是,在生成3D形状时,用户可以选择以各种3D表示形式生成3D形状:体素、点云、网格或神经隐式场,其中每个3D表示通常采用不同的设置和骨干,每个都有自己的特点、优点和缺点。各种3D表示的可视化如图5所示。在实践中,对于许多任务,特定的表示可能比其他表示更适合,其中考虑因素可以包括内存效率、处理表示的易用性和获得监督信号的成本。下面,我们根据每个方法生成的输出3D数据表示进一步对3D形状生成方法进行分类。表4报告了一些具有代表性的3D形状方法的性能。
三维场景的新视图合成
随着三维形状重建的进展,人们对三维场景也越来越关注和感兴趣,这些场景可以涉及一个或多个物体和背景。涉及三维场景的主流生成方法是显式或隐式地编码三维场景表示(即通过基于体素的表示或神经隐式表示),这允许在需要时从新视图合成图像。由于需要对完整的场景进行编码,这项任务往往比三维形状生成更具挑战性。另一个困难是如何隐式地编码三维场景,因为三维场景的渲染涉及颜色、纹理和照明的生成,这些都是现在需要编码的具有挑战性的元素,而第6.4节中介绍的用于三维形状表示的占用域和符号距离域并不自然地对颜色进行编码。
结论
AIGC是一个重要的主题,在不同的模态中获得了重要的研究关注,每个模态都呈现出不同的特点和挑战。在本综述中,我们全面回顾了不同数据模态的AIGC方法,包括单模态和跨模态方法。此外,我们还根据条件输入信息对这些方法进行了组织,提供了结构化和标准化的输入模态的概览。我们强调了每个设置中的各种挑战、代表性工作和最近的技术方向。此外,我们还对各种模态的代表性工作进行了性能比较。我们还讨论了挑战和潜在的未来研究方向。