导语:本报告描述了美国空军研究实验室工作:关于创建可视化系统,使领域专家(SME)能够构建、策划、评估和评价以数据为中心的机器学习模型。专知做了中文编译,欢迎关注,完整中英文版请上专知网站(www.zhuanzhi.ai)查看!
欢迎关注 专知【AI+军事】主题:
https://www.zhuanzhi.ai/topic/2001883600396423
![]()
以下为正文:
本项目目标是创建可视化系统,使领域专家(SME)能够构建、策划、评估和评价以数据为中心的机器学习模型。系统允许领域专家直观地探索数据,通过界面构建目标函数,并将其提交给AutoML系统以生成机器学习模型。通过整合输入数据、模型输出和结果的可视化探索,系统支持模型的开发、调整,并以一种与底层建模技术相分离的直观方式进行验证。
关键词:自动机器学习;可视化;模型学习;模型比较;数据增强
1.0引言
本项目是DARPA数据驱动模型开发(D3M)项目的一部分。我们项目的目标是创建可视化系统,使领域专家(SME)能够构建、策划、评估和评价以数据为中心的机器学习模型。领域专家拥有特定领域的专业知识,通常是通过多年的经验获得的。然而,他们往往不是计算和数据科学方面的专家,因此无法利用现代机器学习技术的力量。我们将构建一些系统,使领域专家能够直观地探索数据,通过直观的界面构建目标函数并提交给AutoML系统,检查和比较AutoML返回的模型,并为分析目标选择最佳模型。通过整合输入数据、模型输出和验证结果的可视化探索,我们的系统将允许以一种与底层建模技术脱钩的方式进行模型开发、调整、形式化、验证和记录。
考虑了一个情报分析员的任务:使用我们的可视化系统,根据最近的新闻报道分析一个国家的政治风向。由于他可以通过可视化系统直接访问一套机器学习模型,他能够在可视化系统中打开一个预定义的高级分析任务列表,并选择一个适合她的目标(例如,"发现不寻常的事件"),而不必直接选择合适的机器学习算法或手动选择其参数。通过AutoML,可以构建多个不同的模型和具有不同参数的模型,并将输出结果可视化,从而可以对其进行评估、比较,并与原始数据连接起来。这有助于情报分析员专注于他们的任务和数据,而无需花费精力去了解机器学习建模和参数调整的细微差别。
此外,我们考虑通过用知识库中的信息来增强领域专家的数据分析能力。知识库能够存储大量的信息和数据。例如,WikiData是一个知识库,它对维基百科的关系信息进行编码。与供人类阅读的维基百科不同,WikiData以结构化的格式存储信息,从而可以通过SPARQL等正式的查询语言来检索数据。将丰富的知识库整合到领域专家的分析过程中可以帮助领域专家探索新的假设,否则是不可能的做到的。
技术方法
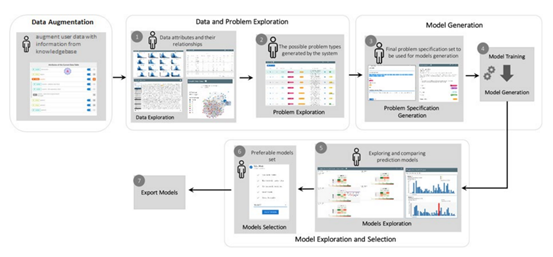
我们提出的可视化系统有四个组成部分,将使领域专家(SME)通过使用AutoML来利用复杂的数据分析算法(见图1)。我们系统的四个组成部分是 (1) 数据增强,(2) 数据和问题探索,(3) 模型生成,(4) 模型探索和选择。
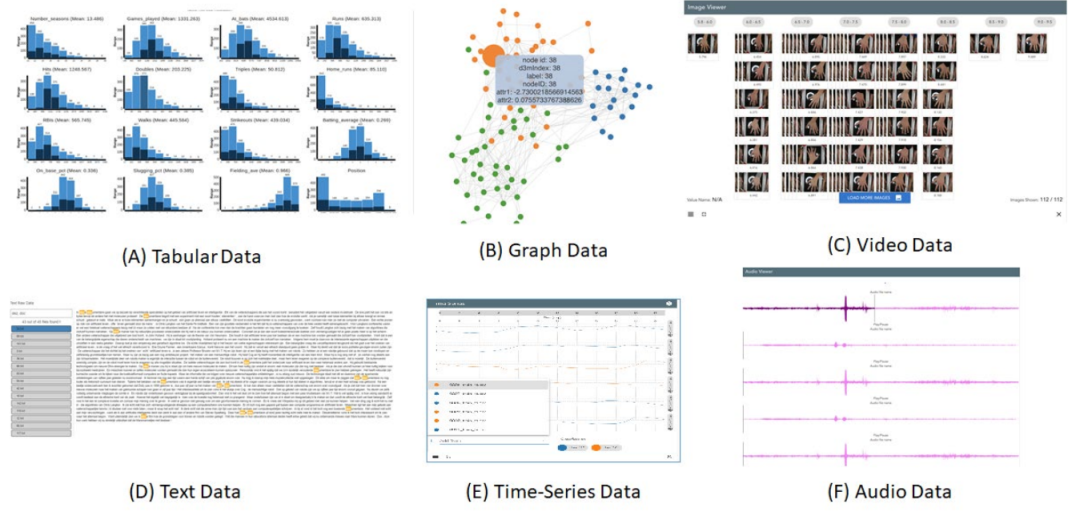
(1) 数据增强。机器学习模型只有在用数据去创建时才是准确和有用的。为此,建模过程的第一步是帮助领域专家搜索、识别并为他们的建模任务策划必要的数据。需要一个交互式工具来帮助领域专家用从知识库中获得的额外特征来增加他们的初始数据集。(2) 数据和问题探索。领域专家拥有领域专业知识,但缺乏数据科学技能。当他们不了解应该使用哪种算法时,系统如何支持他们创建查询?我们的解决方案包括两个步骤。(a) 提供一个探索性的可视化界面,允许领域专家检查输入的数据,以及(b) 在数据的基础上自动生成一些合理的机器学习问题。在向AutoML系统发布任务之前,领域专家可以完善和更新相关的问题。(3) 模型生成。我们将可视化界面与AutoML系统相结合。给出一个问题定义(由领域专家在上一步通过使用可视化界面生成),我们的系统要求AutoML系统执行该问题并生成一些可信的机器学习模型。(4) 模型探索和选择。由AutoML系统生成的模型会有类似的定量指标(如准确率、F1分数等)。然而,它们往往在与领域问题相关的定性指标上有所不同。例如,疾病传播的增加是以片状线性方式进行的,还是更有可能是二次性的增加?为了帮助领域专家做出这样的判断,我们的关键见解是,模型性能的标准评价所提供的丰富数据提供了一个丰富的数据集,对它的探索将使领域专家获得对模型集合的洞察力,以执行诸如性能预测、模型选择和信任特征等任务。由AutoML系统生成的模型对领域专家来说(在大多数情况下)是 "黑盒"。因此,我们专注于开发工具,让领域专家只用这些黑盒产生的输入/输出对就能完成他们的任务。
与现有技术的比较
目前的模型构建和整理系统是为那些了解如何与模型直接互动的数据科学家设计的。数据专家必须将问题形式化,以确定一个合适的方法。他们选择算法和处理通道,并手动调整参数。然后对结果进行评估,可能会导致进一步的调整。这种方法对领域专家来说是不合适的:
-
该方法需要具备建模工具(如R和Python)的专业知识,这些工具涉及编程和对算法参数的直接控制。
-
该方法需要了解特定的机器学习建模技术,随着可用基元集合的增加,这很难维持不断学习新的建模技术。
-
该方法要求具备建模过程的技能,包括如何以适当的形式表述问题,如何将问题映射到建模通道,如何比较许多可能的模型,如何通过设计验证实验评估结果,以及如何适当地记录模型的出处。
虽然这些界面对数据科学家来说可能是可用的,但我们需要为领域专家提供新的用户体验。
https://www.zhuanzhi.ai/vip/6f635fa0ccbcefda4d3cd340586ec076
专知便捷查看
便捷下载,请关注专知人工智能公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取100000+AI(AI与军事、医药、公安等)主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取100000+AI主题知识资料