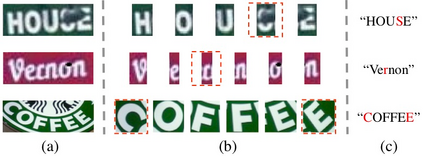
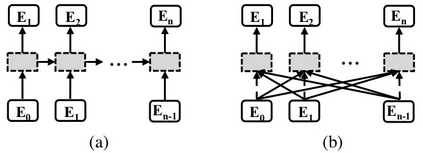
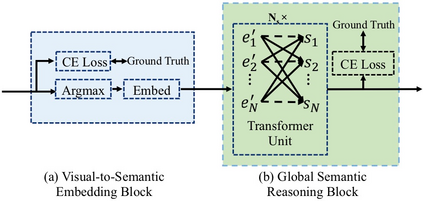
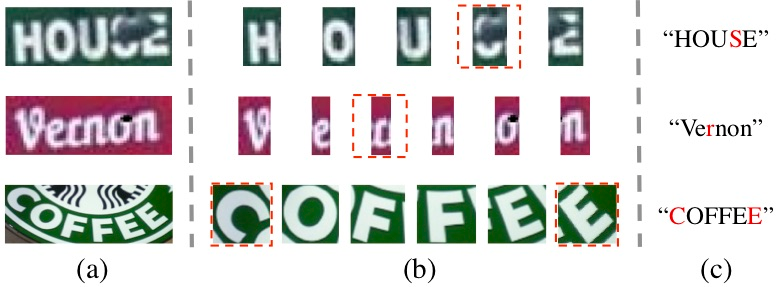
Scene text image contains two levels of contents: visual texture and semantic information. Although the previous scene text recognition methods have made great progress over the past few years, the research on mining semantic information to assist text recognition attracts less attention, only RNN-like structures are explored to implicitly model semantic information. However, we observe that RNN based methods have some obvious shortcomings, such as time-dependent decoding manner and one-way serial transmission of semantic context, which greatly limit the help of semantic information and the computation efficiency. To mitigate these limitations, we propose a novel end-to-end trainable framework named semantic reasoning network (SRN) for accurate scene text recognition, where a global semantic reasoning module (GSRM) is introduced to capture global semantic context through multi-way parallel transmission. The state-of-the-art results on 7 public benchmarks, including regular text, irregular text and non-Latin long text, verify the effectiveness and robustness of the proposed method. In addition, the speed of SRN has significant advantages over the RNN based methods, demonstrating its value in practical use.
翻译:文字图象包含两个层次的内容:视觉纹理和语义信息。虽然以往的现场文字识别方法在过去几年里取得了很大进展,但用于帮助文字识别的采矿语义信息研究没有引起多少注意,但只探讨了类似于RNN的结构,以隐含地模拟语义信息。然而,我们注意到,基于RNN的方法有一些明显的缺点,例如根据时间的解码方式和单向序列传输语义背景,这大大限制了语义信息的帮助和计算效率。为了减少这些限制,我们提议了一个名为语义推理网络(SRN)的新型端到端可训练框架,用于准确的现场文字识别,在此过程中,引入了一个全球语义推理模块(GSRM),通过多路平行传输来捕捉全球语义背景。7个公共基准的状态结果,包括普通文本、非拉丁文本和非拉丁长文本,验证拟议方法的有效性和稳健性。此外,SRN的速度比基于RNNN的方法有相当大的优势,表明其实际使用的价值。