

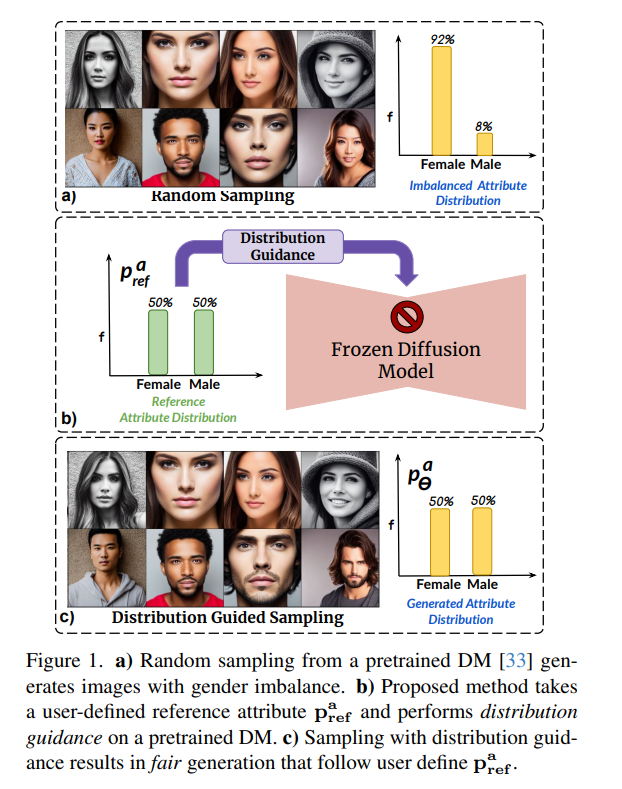
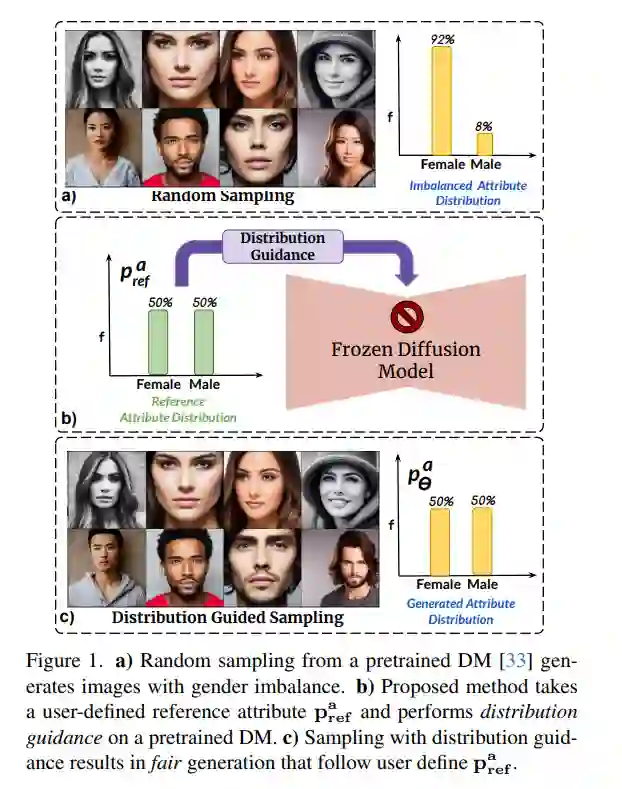
扩散模型(DMs)已经成为具有前所未有的图像生成能力的强大生成模型。这些模型广泛用于数据增强和创意应用。然而,DMs反映了训练数据集中存在的偏见。在面部图像的上下文中,这一点尤其令人关注,其中DM倾向于偏好某一人口亚群而不是其他亚群(例如,女性对比男性)。在这项工作中,我们提出了一种不依赖额外数据或模型重新训练的去偏差DMs的方法。具体来说,我们提出了分布指导,这种方法强制生成的图像遵循预设的属性分布。为了实现这一点,我们建立在一个关键见解上,即去噪UNet的潜在特征包含丰富的人口统计学语义,同样可以被利用来指导无偏差的生成。我们训练了属性分布预测器(ADP)-一个小型的多层感知机(mlp),它将潜在特征映射到属性的分布上。ADP是通过从现有属性分类器生成的伪标签训练的。提出的分布指导与ADP使我们能够进行公平生成。我们的方法减少了单个/多个属性的偏见,并且在无条件和文本条件扩散模型的基准测试中以显著的优势超越了基线。此外,我们提出了一个下游任务,通过使用我们生成的数据重新平衡训练集来训练一个公平的属性分类器。
成为VIP会员查看完整内容

相关内容
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日