

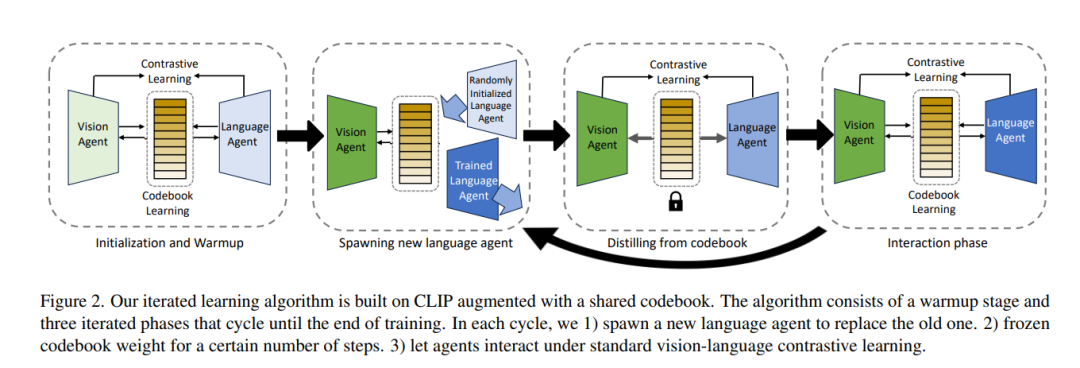
人类视觉和自然语言的一个共同的基本特性是它们的组合性。然而,尽管大型视觉和语言预训练带来了性能提升,最近的研究发现,我们的大多数(如果不是全部)最先进的视觉-语言模型在组合性方面存在困难。它们无法区分“一个穿白衣面向一个穿黑衣的男人的女孩”和“一个穿黑衣面向一个穿白衣的男人的女孩”的图像。此外,先前的工作表明,组合性并不随着规模的增加而出现:更大的模型大小或训练数据并无帮助。本文开发了一种新的迭代训练算法,激励组合性。我们借鉴了数十年的认知科学研究,该研究认为文化传播——需要教育新一代——是激励人类发展组合语言的必要归纳先验。具体而言,我们将视觉-语言对比学习重新框定为视觉智能体和语言智能体之间的Lewis信号游戏,并通过在训练期间迭代重置其中一个智能体的权重来操作化文化传播。每次迭代后,这种训练范式诱导出的表示变得“更易于学习”,这是组合语言的一个属性:例如,我们在CC3M和CC12M上训练的模型在SugarCrepe基准测试中分别使标准CLIP提高了4.7%,4.0%。
成为VIP会员查看完整内容
相关内容

Arxiv
224+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日