

推理是一种使用证据来得出合理结论的认知过程。推理能力对于大型语言模型(LLMs)作为人工通用智能代理的“大脑”至关重要。最近的研究表明,对LLMs在具有思维链(COT)推理过程的数据上进行微调可以显著增强其推理能力。然而,我们发现经过微调的LLMs存在一种“评估不一致”问题,即它们经常将更高的分数分配给次优的COTs,从而可能限制了它们的推理能力。为了解决这个问题,我们引入了“对齐微调”(AFT)范式,包括以下三个步骤:1)使用COT训练数据对LLMs进行微调;2)为每个问题生成多个COT响应,并根据它们是否达到正确答案将其分类为正面和负面响应;3)使用新的约束对齐损失来校准LLMs给出的正面和负面响应的分数。具体而言,约束对齐损失有两个目标:a)对齐,确保正面分数超过负面分数,以鼓励具有高质量COTs的答案;b)约束,将负面分数限制在合理范围内,以防止模型降级。除了二元正面和负面反馈之外,当存在排名反馈时,约束对齐损失还可以无缝地适应排名情况。此外,我们还深入研究了最近的基于排名的对齐方法,如DPO、RRHF和PRO,并发现这些方法忽视的约束也对它们的性能至关重要。在四个推理基准上进行的大量实验,包括二元和排名反馈,都证明了AFT的有效性。此外,AFT在多任务和分布外情况下也表现良好。
概述
推理是一种认知过程,涉及利用证据来得出一个基于良好基础的结论(Qiao等人,2023年;Huang和Chang,2023年)。最近,人们越来越关注提高大型语言模型(LLMs)的推理能力(Li等人,2023b年),特别是开源LLMs(Yuan等人,2023a年;Luo等人,2023年;Mukherjee等人,2023年),因为LLMs仍然缺乏推理技能(Wang等人,2023b;d年;Zheng等人,2023年),而这对于它们作为人工通用智能智能体的"大脑"至关重要(Wang等人,2023a年;Yao等人,2023年;Song等人,2023b年)。
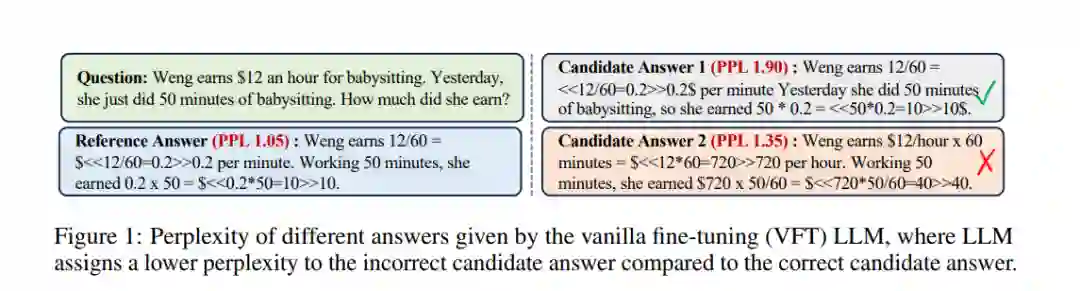
近期的研究(Chung等,2022年;Hsieh等,2023年;Mukherjee等,2023年)发现,使用具有思维链(COT)推理过程的数据来训练LLMs是提高LLMs推理能力非常有效的方法。这些研究通常使用最大似然估计(MLE)来训练LLMs,并采用下一个标记预测的目标。然而,MLE仅为参考COT分配概率质量,这与需要不同推理路径才能得出正确答案的推理任务相矛盾。在本文中,我们发现以前的传统微调(VFT)范例导致LLMs遇到"评估不一致"问题,即LLMs难以评估不同COTs的质量,最终限制了它们的推理能力。以图1为例,VFT-LLMs学会生成给定问题的参考答案,通过为这个参考答案分配概率质量,并将所有其他答案视为负面结果。因此,它们难以评估其他答案的质量,往往会将不正确的候选答案1的困惑度降低(分数提高),而将正确的候选答案2的困惑度提高。 VFT-LLMs的这种行为与人类不一致,因为人类在学会推理后具有评估不同COTs质量的能力。此外,我们的初步实验(第3节)发现,在经过相同的VFT过程后,具有更好推理性能的LLMs能够更合理地评估不同的COTs。因此,我们假设通过减轻VFT引起的评估不一致问题,我们可以提高LLMs的推理能力。为了解决评估不一致问题,本文提出了一种对齐微调(AFT)范例,以三个步骤改善LLM的推理能力:1)使用COT训练数据对LLMs进行微调;2)使用经过微调的LLMs为每个问题生成多个COT响应,并根据它们是否推导出正确答案将它们分类为正面和负面响应;3)使用一种新颖的约束对齐(CA)损失来校准LLMs给出的正面和负面响应的分数。具体而言,CA损失确保所有正面分数(正面COTs的分数)大于负面分数。此外,负面分数由一个约束项保护,这在防止模型降级方面被证明非常重要。除了二进制的正面和负面反馈之外,当存在排名反馈时,CA损失也可以无缝适应排名情况。此外,我们还深入研究了最近基于排名的对齐方法,例如DPO(Rafailov等,2023年)、PRO(Song等,2023a年)和RRHF(Yuan等,2023b年),并发现这些方法忽略的约束对于它们的效果也是至关重要的。 总结一下,我们的贡献包括: 1)我们发现,经过传统微调(VFT)范例微调的LLMs存在"评估不一致"问题:它们经常将高质量的COTs与低质量的COTs相比,分配较低的分数,从而影响了它们的推理能力。 2)我们提出了一个对齐微调(AFT)范例,包括三个简单的步骤,以及一种新颖的约束对齐损失来解决已识别的问题。 3)我们深入研究了最近基于排名的对齐方法,发现这些方法忽略的约束对于它们的性能也是至关重要的。 4)在四个推理基准上进行的实验,包括二元和排名反馈,证明了AFT的有效性。AFT在多任务和分布外情况下也表现良好。 大型语言模型推理与对齐
推理是一种认知过程,涉及利用证据来得出基于充分理由的结论,这是LLMs作为人工通用智能代理"大脑"的核心能力。研究人员已经提出了许多方法来提高LLMs的推理能力,可以广泛分为三组: 1)预训练:预训练方法在大量无监督数据集上对LLMs进行预训练,例如pile(Gao等,2020年)、stack(Kocetkov等,2022年)等,采用简单的下一个标记预测目标。研究人员发现,在更多数据上预训练的更大模型往往具有更好的推理能力(OpenAI,2023年;Anil等,2023年;Touvron等,2023年); 2)微调:微调方法也可以增强LLMs的推理能力。研究人员发现,将LLMs微调到具有思维链式过程的数据上可以显著提高LLMs的推理能力(Mukherjee等,2023年;Chung等,2022年;Li等,2023a年); 3)提示:提示方法旨在通过精心设计的提示策略来提高推理能力,例如思维链提示(Wei等,2022年)、自一致性策略(Wang等,2023c年)等。提示方法不改变模型参数,非常方便和实用。 在本文中,我们重点关注微调方法,并发现传统的传统思维链微调LLMs存在评估不一致问题,这影响了它们的推理能力。因此,我们提出了一种对齐微调范例来解决这个问题,以增强LLMs的推理能力。 AI对齐研究旨在将AI系统引导到人类期望的目标、偏好或伦理原则上。AI对齐方法主要分为两大类: 1)来自人类反馈的强化学习(RLHF)(Ouyang等,2022年),该方法通过利用人类反馈来训练奖励模型,然后将其作为强化学习(RL)技术中的奖励函数,用于通过强化学习技术(例如Proximal Policy Optimization)来优化代理策略。RLHF被用于对齐强大的LLMs,如ChatGPT和GPT4。然而,基于RL的方法在训练效率和复杂性方面存在局限性; 2)带排序的监督微调(Liu等,2022年;Yuan等,2023b年;Song等,2023a年;Rafailov等,2023年),该方法涉及使用监督微调范例来训练LLMs,并引入排名损失以帮助LLMs与人类偏好对齐。以前的对齐研究主要集中在提高LLMs的安全性上,经常忽视了对于推理的对齐的重要性。此外,广泛使用的排名方法通常在减少低质量示例的分数时忽视了约束项,这可能会对模型性能产生负面影响。在本文中,我们指出了对于推理而言对齐的有效性,并引入了一种新颖的约束对齐损失,以使LLMs在对齐的情况下成为更好的推理器。
方法
我们已经展示了传统微调LLMs的评分行为与黄金标准评估存在不一致。在本节中,我们提出了一个对齐微调(AFT)范例来解决这个问题,以增强它们的推理能力。具体来说,在传统微调的目标LVFT之上,AFT进一步引入了一个对齐目标L∗A:LAFT = LVFT + L∗A。 正如我们的初步实验所示,传统微调的LLMs未能对GP和GN中的COTs给出合理的分数。为了使LLMs的评分行为与真实标准评估对齐,我们需要设计一个目标,确保GP中所有正面COTs的分数大于GN中的负面COTs的分数。这个目标与对比学习相似,其目标是确保正例的分数大于所有负例的分数,利用InfoNCE损失:

直观地说,最小化方程5的目标是使正面分数scpθ大于所有负面分数。然而,由于GP中有不止一个正例,受到(Su等,2022年;Wang等,2022年)的启发,我们扩展了LInfoNCE以适应多个正例:
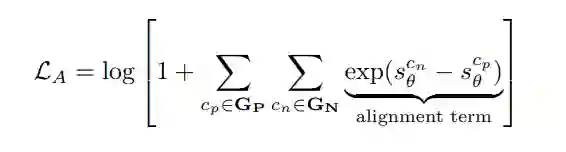
其中,scθ是由方程2计算的COT c 的平均对数似然分数。最小化LA鼓励所有正分数都大于所有负分数。 实验结果
我们在三个广泛使用的推理数据集上进行实验,这些数据集包括人工注释的思维链,包括数学推理任务GSM8K(Cobbe等,2021年)、AQUARAT(Ling等,2017年)和常识推理任务ECQA(Aggarwal等,2021年)。此外,我们创建了GSM8K-RANK来评估我们AFT在排名情况下的有效性。更多有关这些数据集的详细信息,请参考附录A。

我们将我们的AFT与以下基线方法进行比较:1**)VFT**:传统微调(VFT)方法,仅使用MLE损失简单地训练LLMs以参考COT,这是最广泛使用的训练策略;2)RFT:拒绝抽样微调(RFT)(Yuan等,2023a年)选择具有正确答案的COTs,将这些COTs添加到原始训练数据中,并使用新的增强训练数据来训练LLMs,这已被证明是一个非常强大的基线;3)RRHF:以人类反馈对齐的候选排名(RRHF)(Yuan等,2023b年),该方法考虑了候选排名,并通过一对一排名损失来区分不同的候选者;4)PRO:候选者排名优化(PRO)(Song等,2023a年),该方法考虑了候选排名,并通过带有动态温度的排名损失来区分不同的候选者。
表2显示了不同微调方法在三个推理数据集上的结果。如下所示: 1)AFT在所有三个数据集上明显优于VFT,提高了所有模型的平均准确率1.91%∼2.57%,表明了AFT的有效性; 2)我们同时进行的研究RFT与VFT相比也表现出显著的改善。然而,原始的RFT论文只将RFT视为一种简单的数据增强方法,没有解释其显著改进背后的原因。我们的对齐视角可以为RFT的有效性提供解释,即RFT也可以被视为一种对齐策略,加强了许多正面COTs的分数,从而可以缓解VFT的评估不一致问题; 3)我们提出的两种约束对齐策略在具有二进制反馈的情况下略优于RFT。此外,我们的AFT也可以轻松扩展以利用RFT难以很好利用的排名反馈。这些结果显示了揭示VFT评估不一致问题的重要性以及我们的AFT方法的有效性。

正如第4.4节所述,我们的AFT也可以轻松适应排名情况,其中我们可以获得生成的COTs的质量排名序列。表3展示了GSM8k-RANK中不同方法的结果。如下所示: 1)我们的AFT超越了所有其他方法,在具有排名反馈的情况下展示了其有效性。例如,AFT在平均准确率上超过了最强基线RFT 0.88%。这种优越性可以归因于AFT在排名背景下帮助LLMs识别任何给定对中的质量差异的能力,而RFT仅专注于优化最高质量示例的概率; 2)以前的使用排名损失的方法对模型性能产生了显著负面影响。例如,将RRHF损失集成到VFT中导致准确率降低了14.8%。实际上,他们自己的论文(Song等,2023a)中也观察到了性能下降,这表明排名损失通常增强了LLMs的奖励,但导致BLEU分数降低。然而,他们没有确定原因,在本文中,我们发现性能下降的一个潜在原因是他们的损失中缺乏约束,我们将在第6.1节中讨论。
结论
在本文中,我们发现传统微调(VFT)的LLMs在具有思维链(COT)推理过程的情况下存在评估不一致问题,即它们未能评估学习问题的不同COTs的质量,从而阻碍了LLMs的推理能力。为此,我们提出了一种对齐微调(AFT)范例。我们的AFT包括一种新颖的约束对齐损失,可以在不损害模型性能的情况下对齐模型的评估行为。此外,我们还深入研究了最近广泛使用的用于对齐的排名损失,并发现这些方法忽视的约束项也对其性能至关重要。在四个推理基准的大量实验中证明了AFT的有效性。此外,AFT在多任务和分布外情况下表现出色。

